

0 引言
传统的测井岩性识别方法主要采用的是交会图分析、统计学分析以及成像测井等方法,但这些传统方法识别精度低、效率慢、价格昂贵,不利于推广应用[9]。随着人工智能的发展,越来越多的机器学习和深度学习算法也用到了测井解释中来,一些相应的问题也得到了一定解决。如蔡泽园等[10]提出了自适应核密度的贝叶斯概率模型,该模型利用多种不同岩石对应的物性参数,通过自适应核密度提高了分类结果的稳定性。谷宇峰等[11]采用了梯度提升决策树(GBDT)方法进行岩性识别,即使在具有一定相似性的预测样本时也能给出准确的判别。苏赋等[12]提出一种模糊孪生支持向量机多分类算法,相比于传统的支持向量机算法,有效地解决了数据不平衡导致样本较少的岩性类别难以识别的问题。杨柳青等[13]采用了深层卷积神经网络联合了多种测井参数对储层孔隙度进行了预测,在减小预测误差的同时,提高了预测的实时性。武中原等[14]采用了循环神经网络LSTM进行岩性识别,有效提取了岩石沉积作用下的时序特征,提高了测井曲线和岩性标签的整体匹配效果。周恒等[15]通过胶囊网络提取了测井岩性数据在空间序列特征之间的内在联系,能有效地对岩性交界处的复杂结构进行识别。但是这些方法都是单一的对测井曲线深度上的特征进行提取,并没有对测井数据的多尺度频域特征进行挖掘。除此之外,以上的深度学习方法都是选取时间或者空间的单一特征进行学习,并没有融合多种网络进行联合学习。
因此,为了进一步提高岩性识别的准确性,本文提出一种多尺度时频空三域特征联合下的储层岩性识别方法。此方法结合了测井曲线在深度-频域上的多尺度特征,能有效提取不同频率尺度下测井曲线间的空间信息和地层沉积的时间信息,并且通过注意力机制改进了GRU网络模型,有效缓解了GRU网络错误信息传播的问题,提高了模型的分类效果,并通过对比实验证明了本文方法相比于传统方法岩性识别精度更高,具有良好的应用前景。
1 多尺度频域特征分析
在地质勘探中,实际获得的测井曲线一般带有很多噪声信息,这些噪声和地层信息混合在一起,造成了部分有用信息丢失。此外部分岩性的测井响应还具有一定的相似性,例如在常见的泥砂岩储层中,泥岩和砂岩的测井响应相似且交替频繁,仅用原始测井曲线难以划分,这些问题都给岩性识别带来一些困难。而测井数据是叠加了各地层信息的复合信号,隐含了地层沉积过程中的多尺度信息,通过引入测井曲线的多尺度频率分量,可发现不同频率尺度下的地层特征,从而提高测井曲线的纵向分辨率。
在此基础上,本文选择了互补集合经验模态分解(CEEMD)的方法对测井曲线进行多尺度分解。相比于小波分解和经验模态分解,此方法对非线性和非平稳的信号分解效果较好,能有效地缓解模态混叠的问题,且具有一定的自适应性。
CEEMD通过提取测井信号在每一个时刻局部的震荡规律,最终可以把测井信号分解成不同频率的本征模态函数(IMF),通过对不同频率IMF的特征提取,从而学习不同周期下地质变化规律,提高模型对岩性的识别能力。其算法流程如表1所示。
表1 互补集合经验模态分解算法流程
Table 1
| 步骤 | 描述 |
|---|---|
| Step 1: | 将高斯白噪声 |
| Step 2: | 对加入噪声的新信号进行EMD分解,并得出一阶本征模态分量 |
| Step 3: | 对N个模态分量进行总体平均得到CEEMD分解的第一个本征模态分量: |
| Step 4: | 去除第一个模态分量后的残差: |
| Step 5: | 在 |
| Step 6: | 去除第二个本征模态分量后的残差: |
| Step 7: | 重复以上步骤,直到 |
2 CNN-BiGRU-AT模型构建
2.1 整体网络结构
本文网络模型由3个模块构成:数据分析及处理模块、CNN多尺度空间特征提取模块和BiGRU-AT时序特征提取模块。通过不同尺度的卷积层和BiGRU层串联融合并行输出的方式,实现对不同尺度频率下的测井数据时空特征的联合提取,最后通过注意力机制对不同特征赋予不同权重,提高重要特征的表达。具体流程如图1所示。
图1
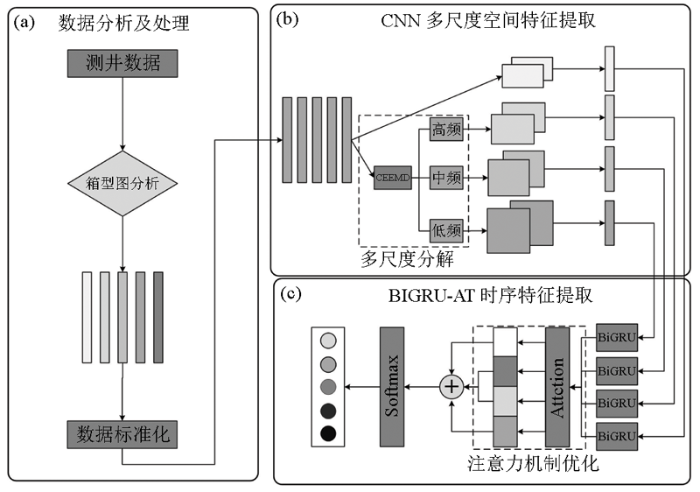
图1
多尺度CNN-BiGRU-AT岩性识别算法流程
Fig.1
Flow chart of multi-scale CNN-BiGRU-AT lithology identification algoritm
2.2 CNN多尺度空间特征提取
随着近几年人工智能的发展,卷积神经网络(CNN)已经成为众多领域研究中的热门话题,被大量应用在语音信号分析和图像处理等领域。
卷积神经网络由于其特殊的网络结构具有表征学习的能力,能对不同数据之间的空间特征进行提取,包含卷积、池化两层。其中卷积层主要用于特征提取和特征映射,并且通过权值共享的方法提高了特征提取的效率;而池化层的主要作用为特征降维,在减少参数的同时保留重要信息,从而提高网络的计算速度[16]。
因此,为了提取原测井曲线和多尺度频率分量的空间特征,本文设计了一个两层的多尺度卷积网络。经过第一层二维卷积核后,CNN可以提取不同测井曲线在时间尺度上的空间相关性,得到不同测井曲线综合的特征表达;然后再经过第二层的一维卷积核提取综合参数在邻近深度上的变化,得到局部特征图集合,这个特征图集合就作为后续网络的输入。具体流程如图2所示。
图2
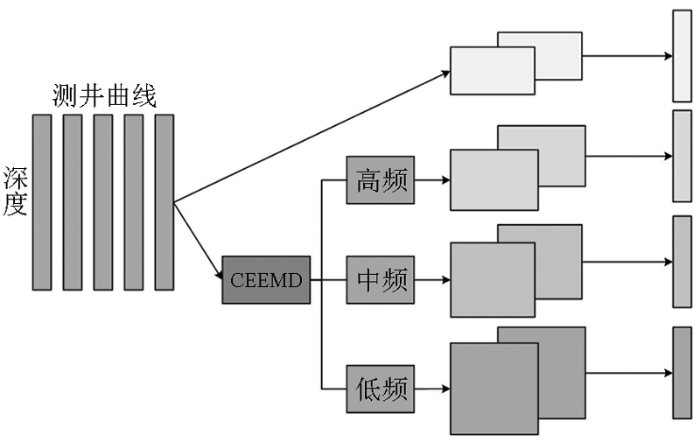
其中,卷积计算公式如下所示:
式中:
为了减少参数,保证网络计算速度,在卷积后通过池化保留重要信息,具体公式如下:
式中:l表示卷积层数;
2.3 BiGRU时序特征提取
门控循环单元(GRU)是长短期记忆神经网络(LSTM)的一种常见的改进网络,在很多任务中能够与LSTM有相当的表现,同时具有更简洁的模型结构。GRU去掉了单元状态,采用隐藏状态来传输,相对于LSTM减少了模型参数,同时提高了模型防止过拟合的能力,加快了网络的收敛速度[17]。
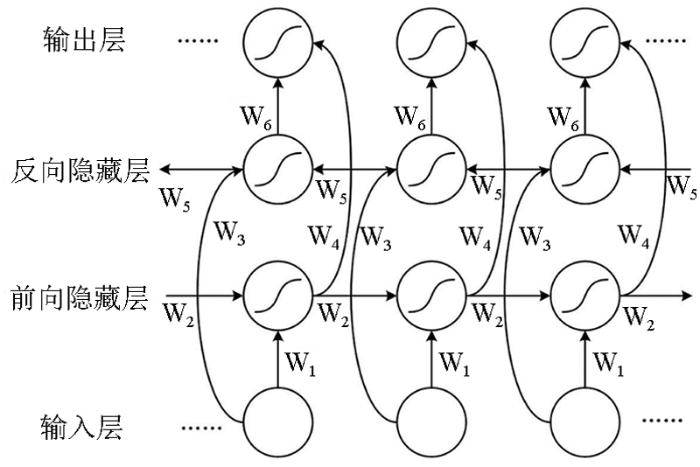
传统的GRU网络为单向传播,只能学到数据的正向时序关系。但通过对地质演变的相关资料分析可知,地层岩性常年受沉积作用的影响,上下围岩的组成具有一定关联性,联合正反向信息有助于学习到更多的时序特征,减小岩性识别的误差。因此本文采用双向门控循环神经网络(BiGRU),BiGRU是通过堆叠正反两层的GRU单元构成,其输出由这两个隐藏层同时决定,能有效解决这一问题。其结构如图3所示。
图3
其中前向隐藏层和反向隐藏层的每一个细胞为一个GRU单元,每一个GRU单元由更新门和重置门组成。其结构如图4所示。
图4
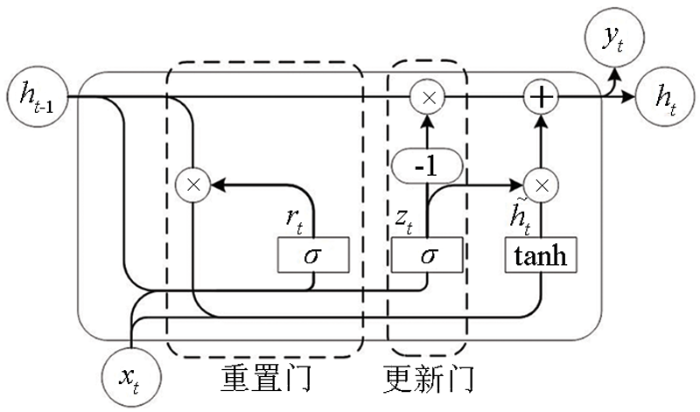
更新门:控制前一时刻的状态信息进入到当前状态中的程度,其公式如下:
重置门:控制写入到当前的候选集
通过更新门和重置门的输出,对细胞状态进行更新:
式中:ht-1是上一个GRU的输出值;ht为传到下一个GRU的输入值;W和U代表权重;σ为sigmoid激活函数;tanh为双曲正切函数。
2.4 注意力机制(Attention)
BiGRU网络虽然能提取上下特征的时序关系,但在长序列数据分类任务中仍会出现一些新问题。即在网络传输过程中,GRU单元在t时刻的输入由t-1时刻输出决定,这样就会导致前面预测错误的信息会一直传递下去,影响后面的预测结果,这样极大影响了深层岩性识别的准确性。
为解决这一问题,采用注意力机制优化BiGRU网络结构。通过注意力机制对每个GRU单元输出的历史信息赋予权重,使得模型不仅仅依赖于上一时刻的输出,而通过整个历史信息决定这一时刻的输出,提高对整体序列的感知能力,减少错误信息的干扰。以一层GRU单元为例,具体流程如图5所示。
图5
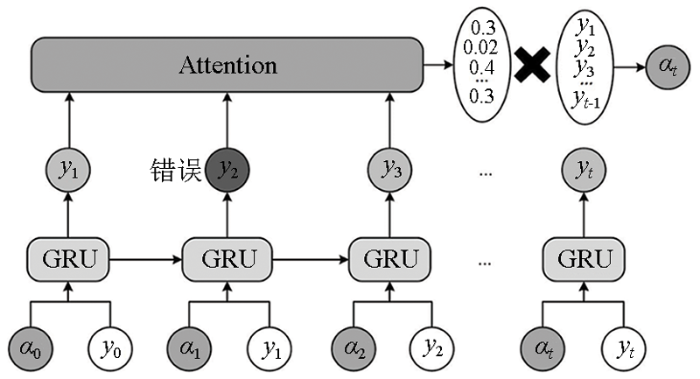
{y0,y1,…,yt}为GRU输入特征,在
其中
通过带有注意力权重的历史信息注入,GRU网络可以找到特征之间的相关性,从而缓解了错误信息传播的问题,提高了GRU网络的识别精度。
3 实验结果分析
3.1 数据说明及分析
本次实验选取实际工区测井岩性资料比较完整的苏5井、苏11井,苏27井,苏28井和苏41井共5口井作为实验数据,采样间隔为0.125 m。按照泥岩、砂岩、砾岩、火山岩和火山碎屑岩5类进行划分,经过地质专家和科研人员的精细标定,共计8 792个样本,其中泥岩3 156个样本,砂岩1 896个样本,砾岩732个样本,火山岩2 544个样本,火山碎屑岩464个样本。虽然样本分布不均衡,但是符合真实工区的数据分布,具有一定的代表性。
通过对测井数据和岩性资料进行分析,本文选取了自然伽马(GR)、声波时差(AC)、自然电位(SP)、电阻率(R4)、微电极1(MINV)和微电极2(MNOR)6条测井曲线作为模型的输入特征。部分数据如表2所示。
表2 部分测井岩性数据
Table 2
| 深度 | AC | GR | MINV | MNOR | R4 | SP | Label |
|---|---|---|---|---|---|---|---|
| 3200 | 192.5 | 3.735 | 5.183 | 4.34 | 20.923 | 17.097 | 3 |
| 3200.125 | 190.439 | 3.939 | 5.217 | 5.908 | 22.488 | 17.065 | 3 |
| 3200.25 | 189.385 | 4.278 | 4.716 | 6.812 | 24.14 | 16.997 | 3 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 3799.75 | 327.084 | 8.221 | 0.856 | 0.807 | 1.84 | 19.522 | 0 |
| 3799.875 | 332.941 | 8.47 | 0.895 | 0.877 | 1.841 | 19.522 | 0 |
| 3800 | 331.738 | 8.53 | 0.953 | 0.935 | 1.841 | 19.623 | 0 |
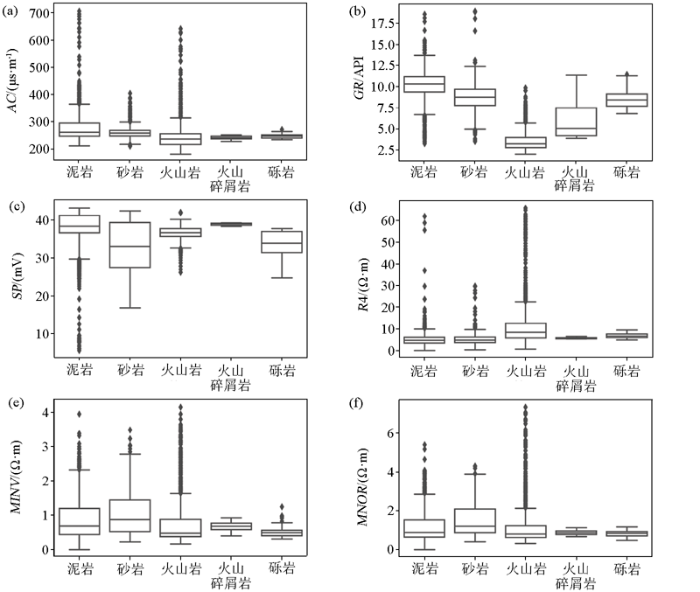
以苏27井为例,5种岩性的箱型图分布如图6所示,从图中可以看出,只有GR曲线5种岩性的数值分布较为分散,其他曲线都存在大量重叠,但只用GR曲线对岩性进行建模主观性太大,难以投入使用。因此为了充分利用不同测井曲线的特征,本文对测井曲线进行了分解,从分解的IMF中找到不同频率分量对不同岩性的联系,从而更有效地区分岩性。
图6
3.2 数据预处理
通过表2可知,实验选取的6条测井曲线数值分布不在同一量纲上,防止网络被数值较大的测井曲线特征影响,本文对所有测井曲线特征值进行z-score标准化处理,使样本保持在同一量纲水平内,z-score标准化公式如下所示:
式中,
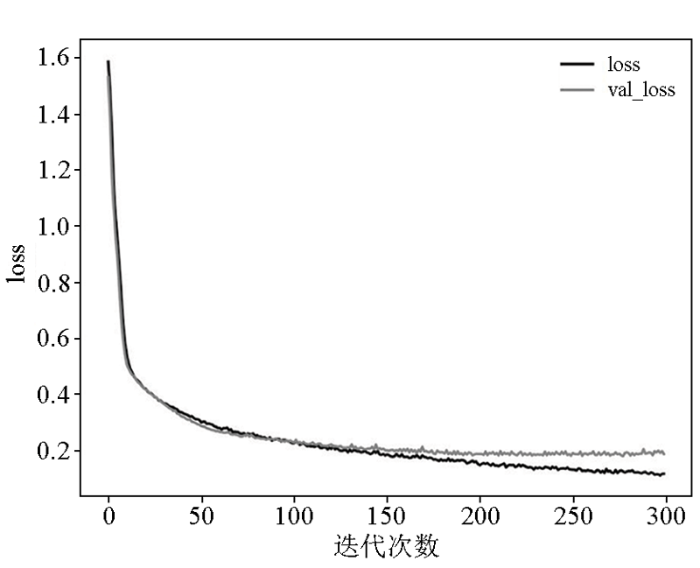
3.3 参数配置及模型训练
本次实验按照类别数对每一类岩性样本都按照训练集和验证集4∶1的比例进行划分,用4口井的数据进行训练,1口井的数据进行测试。由于在实际工区中,苏27井处于这5口井的中间位置,所以本次实验以其它4口井作为训练数据,苏27井作为测试数据。为了评估模型的效果,本次实验引用了精准率、准确率、召回率和F1分数作为模型的评价指标。
本次网络模型训练平台如下:CPU为Intel Core i7-10870,GPU为Nvidia GeForce RTX 2070 with Max-Q Design,运行环境为Python3.7,深度学习框架为Keras(Tensorflow2.1)。实验超参数如表3所示:
表3 实验超参数配置
Table 3
| 参数类型 | 参数值 |
|---|---|
| 卷积层Ⅰ卷积核尺寸 | 3×6、5×6、7×6、9×6 |
| 卷积层Ⅱ卷积核尺寸 | 3×1、5×1、7×1、9×1 |
| 卷积层Ⅰ卷积核个数 | 32 |
| 卷积层Ⅱ卷积核个数 | 64 |
| 每层BiGRU的GRU单元个数 | 128×2 |
| 丢弃概率 | 0.3 |
| 学习率 | 0.0001 |
| 迭代次数 | 300 |
| 批次大小 | 64 |
| 优化器 | Adam |
图7
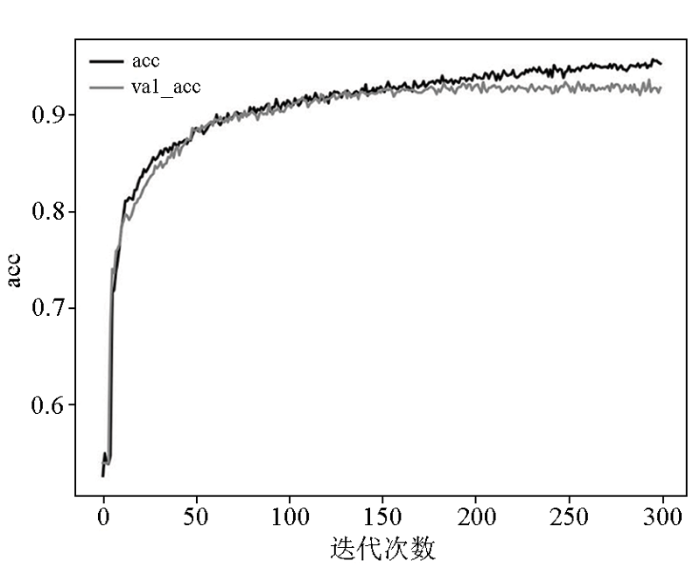
图8
3.4 实验结果及对比实验分析
3.4.1 测井曲线多尺度分解对比实验分析
图9中的a、b、c依次为小波分解(WD)、经验模态分解(EMD)和互补集合经验模态分解(CEEMD)3种方法的GR曲线分解效果。由于EMD和CEEMD算法具有自适应性,无需设置基函数,能自动分解到最大层,因此,本文小波分解也设置为最大分解级数与其进行对比。此外,对非平稳信号进行小波分解需要选择局部性好、紧支撑性好、对不规则性敏感的小波基,经过反复实验,本文选取了Daubechies小波基中的db5进行分解,此时分解效果与本文的CEEMD方法最为相似。
图9
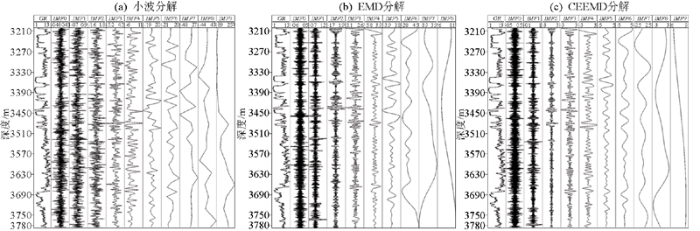
由图9可以看出,小波分解的分量成锯齿状,周期性特征不明显,对高频分量的噪声提取效果并不理想,并且小波分解需要人为的调节参数,如果小波基选择不当,则应用效果会大受影响。相比于小波变换,EMD和CEEMD算法则不需要人为设置基函数。并且从分解的效果中可以看出,后面两种方法分解的曲线更加平滑,且周期特征更加明显。
此外,EMD最大分解级数为9级而CEEMD有10级,由此可看出EMD分解模态混叠严重。从EMD分解的IMF5中可以看出,高低频分量混杂,在其它IMF中同样也会出现这样的问题,这会让信号分析变得更加复杂。
而CEEMD分解通过加入互补的白噪声,在一定程度上缓解了模态混叠现象,通过将EMD的IMF5与CEEMD中的IMF5对比可以发现,CEEMD在一定程度上抑制了多种频率分量的出现,虽然仍有部分模态混叠的现象,但从整体分解效果上看,CEEMD受模态混叠影响最小,并且具有良好的自适应性。因此,通过对自适应性和分解效果的综合考虑,本文选取CEEMD作为信号分解的方法。
通过相关性分析可得CEEMD分解后的10个本征模态与原始测井曲线的相关性系数依次为:0.064、0.076、0.136、0.265、0.269、0.439、0.411、0.388、0.457、0.283,其中相关性较低的IMF多为噪声和干扰信息,相关性较高的IMF反应着不同尺度频率下地层的变化规律。因此,选取相关系数相对较高的3条分量IMF5、IMF6、IMF8作为测井曲线的多尺度频率分量,将筛选的多尺度频率分量与原始测井曲线一起输入CNN网络进行特征提取,为岩性识别提供更多的特征选择。
表4为苏5井3 500~3 600 m不同数据组合下岩性识别的结果,从中可以看出相比只用单一特征进行岩性识别的组别1和组别2,对两种特征进行联合提取的组别3在训练集和验证集的识别准确率上都有显著提高。
表4 不同组合数据的实验结果
Table 4
| 组别 | 数据类型 | |||
|---|---|---|---|---|
| 原测井数据 | 多尺度频 率分量 | 训练识别 准确率/% | 验证识别 准确率/% | |
| 1 | √ | 75.69 | 75.02 | |
| 2 | √ | 71.86 | 71.27 | |
| 3 | √ | √ | 85.19 | 83.68 |
图10为组别1和组别3岩性识别柱状图,通过与录井岩性对比发现,相比于只用原测井曲线(组别1),在加入多尺度频率分量后(组别3),模型对薄互层岩性识别效果更好,由此可看出,加入多尺度频率分量能有效提高测井曲线的纵向分辨率,使模型对储层岩性的识别更加精细。所以在后续实验中,默认对原测井曲线和分解的多尺度频率分量都进行特征提取。
图10
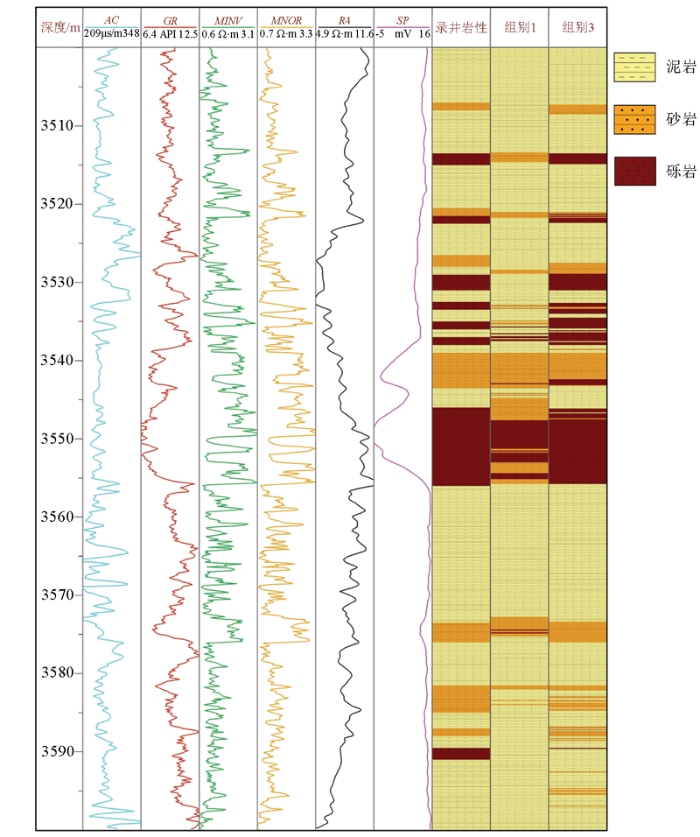
图10
组别1和组别3岩性识别柱状图
Fig.10
Lithology identification bar charts for groups 1 and 3
3.4.2 不同模型对比实验分析
为了验证CNN-BiGRU融合模型的识别效果,本文选取了支持向量机(SVM)、BP神经网络、卷积神经网络(CNN)、双向门控循环神经网络(BiGRU) 与其进行对比实验。
表5为不同模型岩性识别准确率和精准率的结果对比,准确率为预测正确的样本数量占总量的百分比;精准率为模型预测为正样本的结果中,真正是正样本所占的百分比。从表5的识别结果可以看出,同时提取测井曲线之间横向空间特征和纵向时序特征的CNN-BiGRU融合模型相比于其他模型具有更高的准确率。SVM、BP神经网络和CNN模型没有考虑测井数据在深度上的时序特征,整体识别准确率较低。并且这3种模型受样本不均衡影响较大,对于样本较少的砾岩识别精准率较差,而样本更少的火山碎屑岩更是无法识别,虽然保证了整体识别准确率,但是模型无法投入实际应用。而BiGRU模型能提取测井曲线在深度上的时序特征,识别效果也比较稳定,对样本最少的火山碎屑岩也有一定识别能力,在样本较少的砾岩上,识别精准率也有一定提升,但从每类岩性的识别精准率来看,样本不均衡对BiGRU模型仍有一定影响,样本较少的岩性识别精准率都低于80%,离投入实际应用仍有一定距离。而CNN-BiGRU融合模型相较于BiGRU模型在整体识别准确率上提高了1.67%,相较于其他3个模型识别准确率平均提高了10.77%。CNN-BiGRU融合模型在每类岩性识别上表现良好,识别精准率都达到了80%以上。尤其对样本较少的砾岩和火山碎屑岩的识别效果显著提升。由此可看出,融合模型受样本不均衡影响较小,识别效果更加稳定。
表5 苏27井不同模型岩性识别的结果
Table 5
| 岩性 | 精准率/% | |||||
|---|---|---|---|---|---|---|
| SVM | BP | CNN | BiGRU | CNN- BiGRU | 本文 方法 | |
| 泥岩 | 80.76 | 81.78 | 84.01 | 88.53 | 89.55 | 93.05 |
| 砂岩 | 55.68 | 60.34 | 64.26 | 82.81 | 84.79 | 90.41 |
| 砾岩 | 39.13 | 16.13 | 68.00 | 70.73 | 81.55 | 95.10 |
| 火山岩 | 92.34 | 93.08 | 93.72 | 96.61 | 99.18 | 99.64 |
| 火山碎屑岩 | 0.00 | 0.00 | 0.00 | 55.56 | 82.61 | 88.00 |
| 准确率/% | 77.90 | 79.57 | 82.42 | 89.06 | 90.73 | 94.11 |
图11
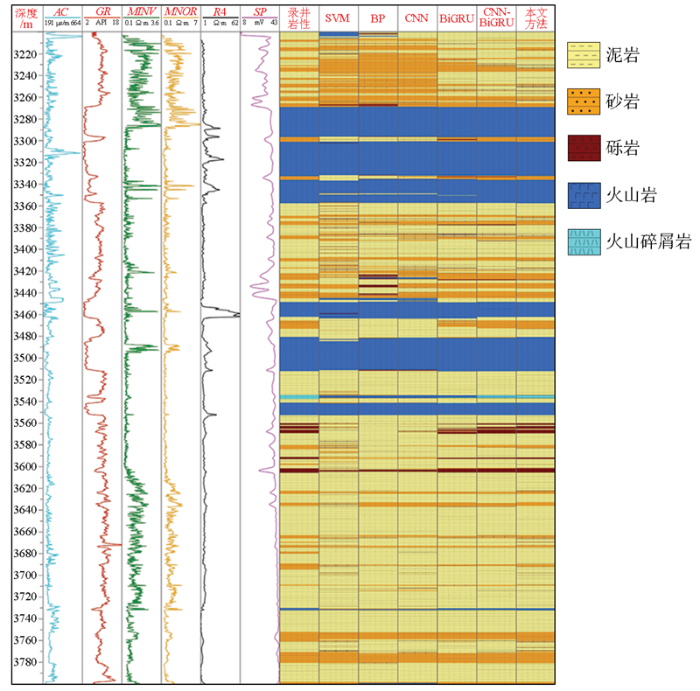
图11
苏27井不同模型岩性识别结果柱状图
Fig.11
Histogram of lithology identification results of different models in Well Su 27
3.4.3 注意力机制消融实验分析
为了验证注意力机制对模型的优化效果,本文在CNN-BiGRU融合模型的基础上对注意力机制进行了消融实验分析。
表6 苏27井本文方法和CNN-BiGRU模型的混淆矩阵
Table 6
| 真实岩性 | 预测岩性(本文方法/CNN-BiGRU) | 精准率/% | 召回率/% | F1得分/% | ||||
|---|---|---|---|---|---|---|---|---|
| 泥岩 | 砂岩 | 砾岩 | 火山岩 | 火山碎屑岩 | ||||
| 泥岩 | 2503/2468 | 80/107 | 3/9 | 2/4 | 0/0 | 93.05/89.55 | 96.72/95.36 | 94.85/92.37 |
| 砂岩 | 174/260 | 792/697 | 2/10 | 1/2 | 0/0 | 90.04/84.79 | 81.73/71.93 | 85.85/77.83 |
| 砾岩 | 7/18 | 0/2 | 97/84 | 0/0 | 0/0 | 95.10/81.55 | 93.27/80.77 | 94.17/81.16 |
| 火山岩 | 3/6 | 2/14 | 0/0 | 1104/1088 | 3/4 | 99.64/99.18 | 99.28/97.84 | 99.46/98.51 |
| 火山碎屑岩 | 3/4 | 2/2 | 0/0 | 1/3 | 22/19 | 88.00/82.61 | 78.57/67.86 | 83.02/74.51 |
此外,在兼顾了精准率和召回率的评价指标F1得分上,本文方法也都达到了80%以上。从表5中也可看出,经注意力机制优化后融合模型在整体识别准确率上也提高了3.38%。
综上可以看出,注意力机制对模型具有良好的优化效果,能对模型训练产生正面影响。
4 结论及展望
本文采用了互补集合经验模态分解的方法对测井曲线进行多尺度分解,将测井曲线在深度—频域上的多尺度信息引入到了模型学习中来,突出了测井曲线在不同频率下的地层特征,有效提高了岩性识别的精度。
本文构建了注意力机制优化的多尺度卷积双向门控循环神经网络(CNN-BiGRU-AT)模型,实现了对不同频率下测井曲线多尺度时空特征的联合提取,并以注意力机制优化了模型输出。与SVM、BP神经网络、CNN、BiGRU和CNN-BiGRU模型相比,本文方法的识别准确率分别提高了16.21%、14.54%、11.69%、5.05%和3.38%,由此可看出本文方法更具优势。
本次实验采用深度学习方法设计模型,在实际储层评价时,对泥岩、砂岩、火山岩等大类岩性进行识别只需要调整网络参数即可,不需要修改网络结构,因此可以随时应用于不同工区,具有较高的泛化性,对工程师快速做出决策具有良好的辅助作用。
参考文献
岩性识别技术现状与进展
[J].
Current status and progress of lithology identification technology
[J].
A competitive ensemble model for permeability prediction in heterogeneous oil and gas reservoirs
[J].DOI:10.1016/j.acags.2019.100004 URL [本文引用: 1]
基于马尔科夫概率模型的碳酸盐岩储集层测井岩性解释
[J].
Interpretation of logging lithology in Carbonate reservoirs based on Markov Chain probability model
[J].
测井岩性识别方法及应用——以鄂尔多斯盆地中西部长7油层组为例
[J].基于鄂尔多斯盆地中西部延长组长7油层组不同岩性、电性、物性、放射性在测井响应上的差异,建立了两种测井—岩性识别方法:交会图法和测井曲线计算法。交会图法通过测井曲线与岩性交会识别出砂岩类、粉砂岩类、泥页岩类和凝灰岩类,测井曲线计算法通过计算泥质含量和有机碳含量将岩性划分为砂岩类、粉砂岩类、泥岩类和富有机质页岩。将计算结果与实验测试结果和岩心进行比对,准确率均达到86%以上。将研究区240口井的岩性识别结果运用于剖面图和平面图的构建发现,研究区长7油层组底部页岩大面积连续发育,向上逐渐减少;砂体主要发育在研究区北部、东部和东北部,其次为西南部和南部。随时间推移研究区中部孤立沉积的砂体个数和面积逐渐增加,并在长71形成大面积发育的砂体。
Logging-lithology identifi cation methods and their application:A case study on Chang 7 Member in central-western Ordos Basin,NW China
[J].Based on the different logging responses in lithologic, electric, physical and radioactive properties of the seventh member of the Yanchang Formation (Chang 7 Member) in the central-western Ordos Basin, two innovative logging-lithology identification methods have been developed, i.e. cross-plot method and Vsh–TOC method. The former method can be used to identify sandstones, siltstones, mudstones and tuffs by crossing the well logs with lithology, while the latter method can be used to identify sandstones, siltstones, mudstones and high-organic shale through calculating the shale content (Vsh) and organic carbon content (TOC). By comparing the calculation results with test results and core samples, both methods are determined to have accuracy above 86%. Results of lithology identification for 240 wells within the study area were used to generate planar and cross sections. It is indicated that shales are widely and continuously developed at the top of the Chang 7 Member in the study area and reduce upwards; sandstones are distributed in the northern, eastern and northeastern parts of the study area, as well as the southern and southwestern parts. As time goes by, the isolate sand bodies in the central part of the study area increased both in area and quantity, and eventually formed the large distribution in Chang 7<sub>1</sub>.
测井资料用于盆地中火成岩岩性识别及岩相划分:以准噶尔盆地为例
[J].
DOI:10.13745/j.esf.2015.03.022
[本文引用: 1]

以准噶尔盆地为例,建立火成岩的测井岩性识别和测井相划分的方法,运用火成岩岩石学理论和岩石物理学的技术方法,确立了火成岩岩性、岩相的测井分类标准。揭示了自然伽马测井、密度测井、ECS测井对火成岩化学成分的变化最为敏感,从基性到酸性火成岩的自然放射性强度逐渐增强,密度降低,金属元素含量减少,二氧化硅含量增加;火成岩的自然放射性、密度、电阻率对火成岩的结构变化有一定的反映,火山碎屑岩与同质的熔岩相比,自然放射性、密度、电阻率测井值降低;补偿中子测井值对火成岩的蚀变程度反映最为敏感,密度、电阻率对火成岩的蚀变程度有一定的反映,且随着蚀变程度的增强,密度、电阻率测井值有降低的趋势。并用岩性敏感测井曲线制作了多维火成岩岩性识别图版、用成像测井制作了火成岩的结构与构造识别图版,用ECS测井区分岩石成分,用岩心资料进行验证,提出了常规测井+成像测井+ECS测井+岩心标定的火成岩岩性识别模式和技术方法,综合判定火成岩岩石的类型、成分、结构和构造,提高了复杂火成岩岩性识别的准确率。
Igneous lithology identification and lithofacies classification in the basin using logging data:Taking Junggar Basin as an example
[J].
Origin of dolomite in the Middle Ordovician peritidal platform carbonates in the northern Ordos Basin,western China
[J].DOI:10.1007/s12182-016-0114-5 URL [本文引用: 1]
Evaluation of machine learning methods for lithology classification using geophysical data
[J].DOI:10.1016/j.cageo.2020.104475 URL [本文引用: 1]
Automatic lithology prediction from well logging using kernel density estimation
[J].DOI:10.1016/j.petrol.2018.06.012 URL [本文引用: 1]
基于深度学习的测井岩性识别方法研究与应用
[J].
Research and application of logging lithology identification based on deep learning
[J].
基于自适应核密度的贝叶斯概率模型岩性识别方法研究
[J].
Lithology identification based on Bayesian probability using adaptive kernel density
[J].
GBDT识别致密砂岩储层岩性
[J].
Lithology prediction of tight sandstone reservoirs using GBDT
[J].
基于改进多分类孪生支持向量机的测井岩性识别方法研究与应用
[J].
Research and application of logging lithology identification based on improve multi-class twin support vector machine
[J].
利用卷积神经网络对储层孔隙度的预测研究与应用
[J].
Prediction and application of reservoir porosity by convolutional neural network
[J].
基于LSTM循环神经网络的岩性识别方法
[J].
Lithology identification based on LSTM recurrent neural network
[J].
基于胶囊网络的碳酸盐岩储层岩性识别方法
[J].
Lithology identification method of carbonate reservoir based on capsule network
[J].
基于卷积神经网络识别重力异常体
[J].
The identification of gravity anomaly body based on the convolutional neural network
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}