

0 引言
随着矿产资源的不断开采,有效管理矿产资源的利用现状信息和准确预测未来储量已成为亟待解决的问题。传统的储量预测方法受到勘查数据的限制和地质条件的不确定性,预测结果往往不够准确,无法满足资源规划和战略部署的需要[1]。因此,研究矿产资源的利用现状信息管理和储量预测方法尤为重要。
王成彬等[2]收集地质勘查数据,构建矿化勘查系统中用于矿产预测的多时相全要素知识图。利用构建的知识图,建立勘查预测模型,并对矿产资源进行定量预测。该方法可以自动整合和分析大量地质勘查数据,减少人工干预,提高预测过程的智能化和自动化水平。但该方法在数据采集和整合过程方面存在困难,导致累积误差较大,无法保证预测结果的可靠性。Ding等[3]利用Siamese网络对地质勘查数据进行特征学习,并使用暹罗网络计算地质数据间的相似性。基于相似性评估的结果,生成矿产预测图或报告。该方法可以自动提取地质数据的特征表示,大大提高了矿产预测的效率。然而,网络的性能受到多种超参数的影响,通常需要多次实验来确定最佳组合,使得该方法的实际应用受限。郑孝诚等[4]利用卷积神经网络算法构建矿产预测模型, 使用已知矿床的地质数据作为输入数据,通过反向传播算法输出未知矿区的矿产资源量。该方法泛化能力强,可以很好地适应不同地质背景和矿化环境的预测需求,但该方法存在过拟合风险,导致预测结果准确率偏低。Babii等[5]利用扫描电子显微镜、能量色散谱等先进的矿物分析技术,分析矿物之间的共生关系,基于克里金插值和协同克里金等地质统计学方法,构建尾矿含铁石英岩富集区矿物成分的空间分布预测模型。然而,矿物成分的空间分布受到各种因素的影响,这些因素的不确定性可能会导致该方法的预测结果出现一定的误差。曾小龙等[6]对收集到的数据进行预处理,以消除影响预测准确性的因素,采用K-Means++算法对地质构造进行聚类分析,并采用随机森林算法建立不同地层类型的钻井速度预测模式,进一步结合KNN模型实现储量预测。该方法适应性广,即使在没有钻探数据的地区,也可以根据地质情况选择类似地区的参数进行预测和后续校正。然而,如果数据中存在缺失或重大错误,可能会影响模型的预测性能。
基于此背景,为提高矿产资源量预测的准确度,本研究旨在通过引入先进的信息管理技术和创新的预测方法,实现对矿产资源利用现状的实时监测和动态分析,提高信息管理的准确性和及时性。
1 储量预测方法设计
1.1 矿产资源利用现状信息管理数据库构建
矿产资源利用现状信息管理数据库的构建为储量预测提供了重要的数据基础。通过收集、整理、存储和管理各类矿产资源数据,形成一个全面、准确、及时的信息平台数据库,为储量预测提供所需的地质、矿产、开采等方面的数据支撑。
本研究采用GIS技术确立矿产资源利用现状管理体系,并通过数据分类组织和规划,构建管理数据库,以实现信息数据的共享、通信以及并发控制,为后续矿产资源储量预测提供数据基础。
将地质勘查报告、采矿活动记录以及遥感监测数据等数据源,根据数据性质将其分类为空间数据和属性数据两大类别。空间数据与矿产空间位置和空间关系有关;属性数据与矿产资源空间实体属性有关[7]。将这两类数据进行格式转换与编码,使其能够被GIS识别与处理。该过程可表示为:
式中:Es表示转换后的数据;vt表示第t个矿产资源开采点;αg表示编码系数;qw表示转换矩阵;Ft表示格式规范化函数,其计算方式如下:
式中:μ0表示数据清洗函数;x0表示编码规则;ϑc表示属性向量;dk表示第k类数据的有效长度。
图1
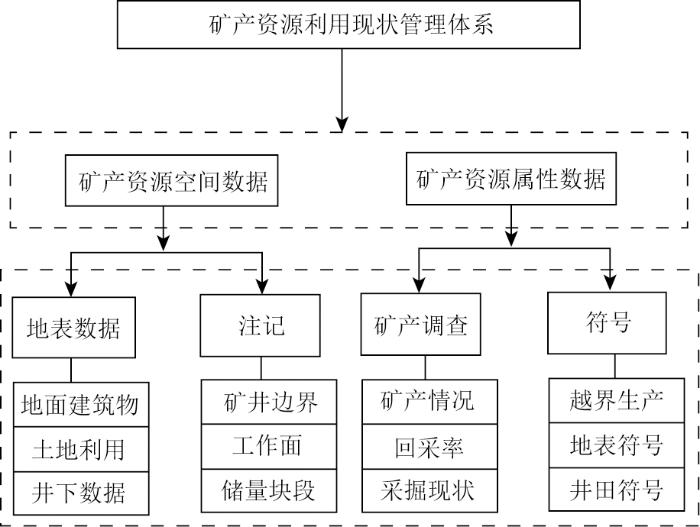
图1
矿产资源利用现状管理体系
Fig.1
Management system for mineral resource utilization status
表1 管理数据库
Table 1
| 数据类型 | 字段名称 | 字段类型 | 字段长度 |
|---|---|---|---|
| 空间数据 | 矿产名称 | VARCHAR | 255 |
| 地理位置 | VARCHAR | 4 | |
| 品位 | DECIMAL | 255 | |
| 开发利用现状 | VARCHAR | 100 | |
| 勘查时间 | DATE | - | |
| 坐标系统 | VARCHAR | 50 | |
| 形态描述 | TEXT | - | |
| 属性数据 | 矿区范围 | VARCHAR | 50 |
| 开采期限 | DATE | 18 | |
| 已开采量 | DECIMAL | 2 | |
| 地质情况 | TEXT | 100 | |
| 矿产资源ID | INT | 200 | |
| 矿种 | VARCHAR | 100 | |
| 倾向 | DECIMAL | 10 | |
| 平均厚度 | DECIMAL | 10 |
将经过格式转换和编码处理后的矿产资源勘查数据输入到GIS系统中,结合矿产资源的空间数据和属性数据确立资源利用现状管理体系,引入全关系型数据,库实现矿产资源利用现状管理,便于后续矿产储量预测。
1.2 矿产资源靶区圈定
为实现对研究区域地质矿产资源储量的精准预测,首先需要在有利于成矿的构造区域中识别并划定那些具备良好成矿条件、可能蕴藏有工业矿床或矿体的地区,确定潜在的矿产资源分布范围以为后期找矿和储量预测奠定基础。
结合矿产资源利用现状管理数据库和研究区域地质、地球物理和地球化学等数据,明确区域的构造特征和矿化信息,建立地质三维模型[10]。在模型中,利用主成分分析法选定高产量矿物元素,并计算元素对应的地球化学异常下限,即:
式中:m表示识别的矿物元素数量;βx表示地表辐射率;ke表示矿产品位分级个数;θf表示矿区变程;Ac表示计算矩阵。
将各类空间信息数据进行整合,得到地质变量权系数[11],计算公式如下:
式中:
将地球化学异常下限低于指定值的区域初步确定为找矿靶区,并对其进行地质填图和地球化学勘探,以获取靶区的成矿有利度[12],计算公式为:
式中:Su表示成矿有利度函数;h0表示正对角加权矩阵;ηk表示矿区背景值的标准差;ιu表示根据矿产品位置信水平确定的系数;wo表示矿石密度;rt表示地表某点的磁异常值。
利用上述过程对靶区进行优化,将成矿有利度高于预设阈值的靶区确定为最终靶区,完成成矿靶区的圈定,为进一步的研究工作创造条件。
1.3 矿产资源储量预测
采用优化后的成矿靶区建立矿产资源的品位—吨位模型[13],表达式为:
式中:Su表示成矿有利度函数;νc表示矿石平均厚度;gd表示品位大于d的矿石所占的比例;ϕx表示参考品位;zs表示模型控制参数。
假设矿石品位分布服从正态分布[14],则品位的概率密度函数可表示为:
式中:ψ0表示品位均值;Hi表示品位标准差;yn表示半变异函数,其计算方法为:
式中:bj表示矿山角度容差;Za表示叠加标度函数。
基于统计取样理论,结合区域成矿靶区的采样信息[15],利用随机变量概率函数预测研究区域的矿产资源储量,计算公式为:
式中:Xw表示区域内矿产资源储量预测值;cf表示随机变量矩阵;λg表示地质三维模型中单元块的体积;χp表示区域内的夹石率;κs表示一阶滞后变量。
综上所述,基于矿产资源利用现状动态信息的储量预测方法的流程如图2所示。
图2

矿产资源信息管理预测软件系统界面如图3所示。
图3
图3
矿产资源信息管理预测软件系统界面示例
Fig.3
Example of interface for mineral resource information management and prediction software system
2 实例论证分析
为验证基于矿产资源利用现状动态信息的储量预测方法在实际工作中的应用效果,将本文方法初步应用在某矿区中,并对其进行矿产资源利用现状信息管理以及储量预测,根据实验结果分析该方法的应用效果。
2.1 研究区域概况
以广东凤凰岭矿区为研究对象,该矿区坐落于地质活动频繁、成矿环境优越的区域,主要矿产资源为建筑所用的片麻岩(含少量花岗岩等)。矿区规划总面积为21.086 km2,分期进行开发。
该区域的主要构造特征表现为以NE-SW方向为主的断层构造占据主导地位,NW-SE方向的断层为次要构造特征。这些断裂带不仅控制着矿体的空间分布,而且还是热液活动的通道,在成矿中起着关键作用。通过详细的地质测绘和钻探数据分析,已确认矿区至少有3条大型控矿断层,编号分别为F1、F2和F3。其中,F2断层是矿体的主要控矿构造。矿体的厚度从1~20 m不等,平均厚度约为8 m。在某些区域存在矿体厚度快速变化的现象,例如尖灭和分支复合等。
矿体呈脉状、层状,且严格受F2断层控制,走向NE,倾角SE,倾角变化较大,范围在25°~65°,平均倾角约为45°。矿体在平面上呈“S”形弯曲,呈复杂的豆状或透镜状横截面,显示出强烈的构造改造痕迹,该矿区的基本概况如图4所示。
图4

图4
研究区矿产资源开发利用概况
Fig.4
Overview of the study area on the development and utilization of mineral resources in the research area
为便于分析与实验,以该研究区域的南部矿层为测试研究目标。剖面主要沿构造线或矿体走向进行切绘,剖面编号为01-01,起点坐标为(100,200,30),终点坐标为(200,50,150)。剖面揭示了3个地层单元:风化层、砂岩夹页岩和含矿层,厚度分别为1.3 m、1.6 m和2.5 m。剖面方向为NE—SW向,面积为4.8 km2,海拔为36~126 m。
研究区域南部矿层剖面如图5所示。
图5

2.2 实验准备
利用遥感技术采集研究区的矿产资源数据,并通过处理与分类,得到空间数据和属性数据,借助GIS系统构建矿产资源利用现状管理数据库,如表2所示。
表2 研究区域矿产资源开发利用信息
Table 2
| 序号 | 项目 | 描述 |
|---|---|---|
| 1 | 矿产资源类型 | 片麻岩(含少量花岗岩等) |
| 2 | 已开采量/t | 1.32 |
| 3 | 利用率/% | 85 |
| 4 | 年开采量/t | 11.2 |
| 5 | 主要矿体特征 | 矿品位高,易于开采 |
| 6 | 回采率/% | 70 |
| 7 | 开采期限/年 | 45 |
根据测区的地质构造特征和矿化信息构建三维地质模型,并基于模型与地球化学异常值对成矿靶区进行圈定,结果如图6所示。
图6
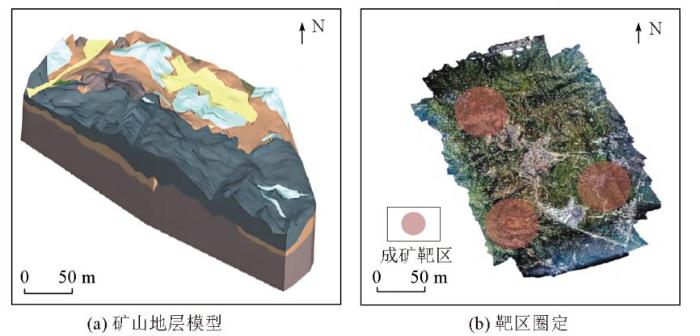
图6
地质三维模型和矿区靶区圈定
Fig.6
Geological 3D model and delineation of mining target area
实验环境的硬件平台为服务器集群配备多核CPU、大容量内存和SSD阵列,以确保高效的数据处理和模型计算。软件平台包括操作系统Linux CentOS 7.x、数据库管理系统、数据分析和编程工具Python 3.8和地理信息系统软件平台ArcGIS 10.8,用于地图制作、空间数据分析和可视化显示。实验过程为:利用地质调查、无人机、卫星遥感影像等手段收集地质、地球物理、地球化学等多源数据,将预处理后的数据存储在PostgreSQL数据库中,并构建矿产资源数据库,利用GIS软件进行空间分析和数据可视化;根据历史数据和专家知识,选择对储量有影响的控矿特征,使用Python脚本构建储量预测模型,对测区矿产资源储量进行预测;使用GIS软件在地图上输出预测结果。
基于以上实验准备和过程,对该研究区域的矿产资源量进行预测,以分析本文论述方法的预测性能。
2.3 矿产资源储量预测结果与分析
图7
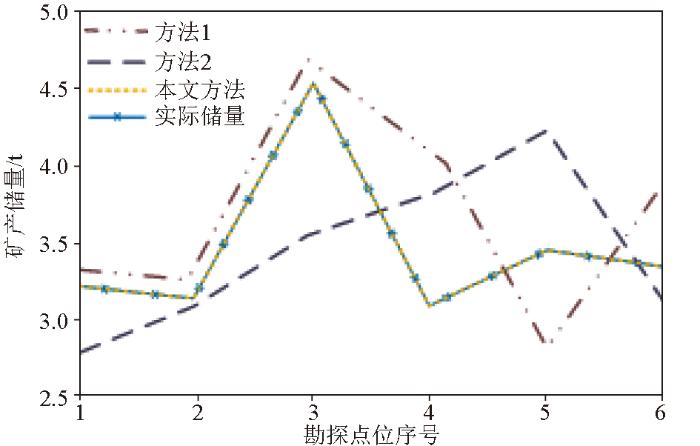
根据图7可知,本文提出的矿产资源储量预测方法具有较高的预测准确度,得到的储量预测值与实际值基本一致,而方法1和方法2的预测结果与真实值之间存在较大误差。由此可以证明本文方法在实际应用中具有可靠性。
2.4 对比实验与分析
在上述实验基础上,为综合体现本文方法在矿产资源量预测精度方面的优异性能,采用“稳定裕度”这一指标对不同预测方法的性能进行评估。稳定裕度越高,代表相应方法得到的预测结果与实际值的拟合程度越高,预测准确度越高。对比结果如表3所示。
表3 3种方法预测结果对比
Table 3
| 块段品位/% | 稳定裕度 | ||
|---|---|---|---|
| 方法1 | 方法2 | 本文方法 | |
| 0.1 | 0.54 | 0.66 | 0.87 |
| 0.2 | 0.57 | 0.75 | 0.92 |
| 0.3 | 0.49 | 0.80 | 0.85 |
| 0.4 | 0.66 | 0.57 | 0.90 |
| 0.5 | 0.70 | 0.63 | 0.88 |
| 0.6 | 0.69 | 0.58 | 0.97 |
| 0.7 | 0.57 | 0.75 | 0.95 |
| 0.8 | 0.40 | 0.81 | 0.92 |
| 0.9 | 0.55 | 0.69 | 0.94 |
| 1.0 | 0.47 | 0.77 | 0.99 |
通过分析表3中的数据可知,与其他两种方法相比,本文方法预测结果的稳定裕度更高,表明本文方法的预测结果更加准确,在预测精度方面具有显著优势,可以满足实际应用需求。
3 结束语
本研究综合应用了数据库技术和地质统计学原理,实现了多专业地质数据的高效集成与智能分析,不仅显著提高了矿产资源管理的精细化水平,而且提高了储量的科学预测准确性。该方法的应用能够为政府决策和企业规划提供全面、实时的矿产资源信息支持,有助于优化资源配置,促进采矿业的可持续发展。同时,通过提前预测矿产资源储量变化趋势,可以为矿产资源勘探开发提供前瞻性指导。
参考文献
基于本体指导的矿产预测知识图谱构建研究
[J].
DOI:10.13745/j.esf.sf.2024.5.4
[本文引用: 1]

在基于数据驱动范式的科学研究中,构建知识图谱已被证明是获取和表征知识的有效手段之一。然而,目前已构建的矿产资源预测领域知识图谱仍然存在诸多挑战和局限性,有待进一步解决和完善。首先,针对矿产预测的本体构建问题研究相对较少,尤其是该领域现有知识图谱的本体层普遍缺乏时空语义,限制了对于矿产资源时空特征的有效表示与分析。其次,现有图谱构建方法主要为面向数据层面的文本抽取,而缺乏对于复杂逻辑关系的本体层建设,以及本体层与数据层之间的有效关联。以上问题会导致构建的地学知识图谱缺乏深层次的语义信息,难以满足矿产资源预测对表达复杂地学概念和关系的需求。针对上述问题,本研究以综合信息矿产预测理论为指导,旨在构建可应用于矿产预测任务的复杂语义知识图谱。具体而言,首先通过对矿产预测的理论和方法进行解析构建初始化领域本体,然后选择成熟的地质时间本体和地理空间本体对初始本体进行本体融合和扩展,通过嵌入时空语义有效表达地矿产资源的时空特征。此外,重点关注了本体层与数据层之间的关联建设,通过建立丰富的语义关系,实现知识图谱中各个节点之间的有效连接与信息共享。实验结果表明,采用本文所提出的方法构建的图谱在知识丰度和置信度等指标上均优于其他现有方法。这一研究为矿产预测领域提供了更为深入和全面的数据资源建设的方法支撑,有助于推动该领域的进一步发展和应用。
Ontology-guided knowledge graph construction for mineral prediction
[J].
DOI:10.13745/j.esf.sf.2024.5.4
[本文引用: 1]
Knowledge graph construction is an effective means of acquiring and representing knowledge in data-driven research, however, existing knowledge graphs have many problems and limitations in mineral resource prediction. Firstly, relevant studies are few while existing knowledge graphs lack spatiotemporal semantics, which limits the effective representation and analysis of the spatiotemporal characteristics of mineral resources. Secondly, existing graph construction methods emphasize text extraction at the data level, but lack ontology construction involving complex logical relationships and lack effective association between ontology and data layers. As a result, existing knowledge graphs lack in-depth and sufficient semantic information to meet the requirement of mineral resource prediction in expressing complex geoscience concepts and relationships. To address this issue, this study takes an ontology-guided approach to construct a knowledge graph suitable for mineral prediction tasks. We first construct the initial domain ontology on the basis of in-depth understanding of mineral prediction theories and methods; we then integrate the domain ontology with selected mature geological time ontology and geographical space ontology to expand the initial ontology—by embedding spatiotemporal semantics we can effectively express the spatiotemporal characteristics of mineral resources. We also pay attention to the association between ontology and data layers—by establishing rich semantic relationships we can achieve effective inter-node connection and information sharing in the knowledge graph. Experimental results show that the knowledge graph outperformed other existing graphs in terms of knowledge richness and confidence. This study provides a methodology for multi-ontology based knowledge graph construction for mineral prediction, thereby promoting further development of this field.
融合知识图谱的矿产资源定量预测
[J].
DOI:10.13745/j.esf.sf.2024.5.3
[本文引用: 2]
大数据和人工智能极大地促进了矿产勘查的发展,创新了矿产预测研究范式,提升了地质找矿大数据的挖掘与集成能力。在资源定量预测领域,知识-数据联合驱动的综合信息智能预测已逐渐成为行业共识,如何实现数据和知识联合驱动是目前亟待解决的问题。知识图谱可以整合多源、异构的地质找矿大数据,其中蕴含的知识和规则在驱动地球科学领域的知识发现方面具有重要的发展潜力。本文针对大数据和人工智能时代对资源定量预测智能化和自动化的需求,结合知识图谱相关技术的特点,探讨融合知识图谱技术的矿产资源定量预测智能化和自动化的可行性和技术方法路线。重点剖析面向矿产预测的成矿-勘查系统多时序全要素知识图谱构建和基于知识图谱从“求同”和“求异”的角度建立找矿预测模型,知识图谱中的知识嵌入到地物化遥异常信息提取的方法,以及融合知识图谱的资源定量预测工作的机遇和挑战。拟希望将知识图谱中知识表达和推理融入到矿产资源定量预测技术方法流程中,协助地质专家来确定矿产预测模型,提高矿产预测的自动化和智能化。
Knowledge graph-infused quantitative mineral resource forecasting
[J].
DOI:10.13745/j.esf.sf.2024.5.3
[本文引用: 2]
Big data and artificial intelligence have greatly transformed mineral exploration practices with the development of innovative mineral forecasting models and improvement of forecasting efficiency for strategic minerals. In the field of quantitative mineral forecasting, comprehensive intelligent forecasting by combining knowledge and data has gradually become a common consensus, however, the challenge lies in how to combine knowledge and data. Knowledge graphs integrate multi-source, heterogeneous geoscience big data and drive knowledge discovery through rules and reasoning. Here, we discuss the feasibility and technical roadmap of knowledge graph-infused intelligent and automated mineral resource forecasting, particularly in consideration of the characteristics of knowledge graphs in the era of big data and artificial intelligence. We focus mainly on the construction of multi-temporal, all-element knowledge graphs for mineral deposit-mineral exploration systems and the methodology for establishing forecasting models from the perspectives of ore commonality and distinctiveness based on knowledge graphs. The opportunities and challenges of knowledge graph embedding for geological anomaly information extraction and quantitative resource forecasting are also discussed, in the hope that the infusion of knowledge representation and reasoning from knowledge graphs into the technical workflow of quantitative mineral resource forecasting can aid geologists in building ore forecasting models and enhancing automated and intelligent mineral forecasting.
Siamese network based prospecting prediction method:A case study from the Au deposit in the Chongli mineral concentrate area in Zhangjiakou,Hebei Province,China
[J].DOI:10.1016/j.oregeorev.2022.105024 URL [本文引用: 1]
卷积神经网络在山东金矿勘查预测中的应用
[J].
Application of convolution neural networks in gold exploration and prediction in Shandong Province
[J].
Prediction of the mineral components spatial distribution in tailings ferruginous quartzite enrichments
[J].
基于南海巨厚塑性泥岩地层特征的钻速预测模型
[J].
Drilling rate prediction model based on the characteristics of thick plastic mudstone strata in the South China Sea
[J].
那陵郭勒河下游重磁异常与铁多金属矿找矿预测
[J].
Gravity and magnetic anomalies in the lower reaches of the Nalingguo River and prospecting prediction of iron polymetallic deposits
[J].
河南嵩县庙岭金矿矿体赋存规律及深部找矿预测
[J].
Ore body occurrence pattern and deep prospecting prediction of Miaoling gold mine in Song County,Henan Province
[J].
南岭东段区域成矿规律与成矿预测
[J].
Regional metallogenic regularity and metallogenic prediction in the eastern Nanling
[J].
基于卷积自编码网络的夏河—合作地区金矿定量预测
[J].
Quantitative prediction of gold mines in Xiahe-Hezuo area based on convolutional autoencoder network
[J].
河南省石墨矿床地质特征、成矿区带划分及找矿预测
[J].
Geological characteristics,metallogenic zone division and prospecting prediction of graphite deposits in Henan Province
[J].
成矿地质体找矿预测理论与方法在矿产勘查中的应用
[J].
Application of prospecting prediction theory and method of ore-forming geological bodies in mineral exploration
[J].
Applications of data augmentation in mineral prospectivity prediction based on convolutional neural networks
[J].
基于PSO-CNN的深部找矿预测模型构建
[J].
Construction of deep mineral exploration prediction model based on PSO-CNN
[J].
基于重磁场特征的洛宁地区构造特征研究及矿产预测
[J].
Research on tectonic characteristics and mineral prediction of Luoning area based on gravity and magnetic field characteristics
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}