

0 引言
上述方法在数据丰富条件下可以达到理想的岩性预测效果,但在实际矿层条件下往往存在一定的问题:①尽管测井数据较为丰富,但对应的岩性解译数据往往有限;②地层岩性分布概率具有严重不均匀性。上述问题会导致机器学习模型训练和预测能力受到限制。针对数据不完备的情况,选择LSTM模型为基础模型,发挥模型权重数量少、不易过度拟合的优势,表达输入测井数据和输出岩性数据之间的关系;另外引入SMOTE算法,对少数类别样本进行分析和增补,不同类别数据的数量尽量保持平衡,形成SMOTE-LSTM混合模型,用于实际测井数据支撑下的岩性解译,并与主流机器学习方法,在准确度、精确率方面进行对比,体现新方法的优越性和工程实用性。
1 研究区概况
图1
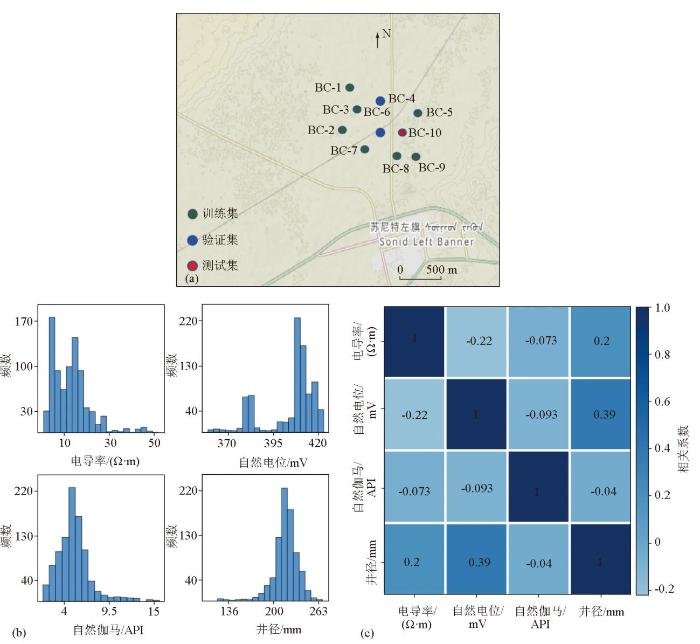
图1
研究区域测井位置分布示意(a)、测井数据频率分布(b)与测井间相关系数分布(c)
Fig.1
Distribution of logging positions in the study area (a), distribution of logging data frequency (b) and correlation coefficient between logging (c)
本次选择9口具有相对完备的测井数据和岩性编录的勘探井进行模型训练,测井曲线包括自然伽马、电导率、自然电位和井径。选取BC-10号测井作为模型测试集进行测试。各钻孔均包含岩性编录和测井数据(图1b),测井数据的深度间隔为0.1 m,深度均分布在0~120 m,岩性编录按照0.1 m间隔进行统计,在模型训练过程中训练集与验证集数据量的采样比设置为7∶2。同时,模型采用Pearson相关系数量化两个连续变量之间的线性关系强度和方向[21],图1中自然电位与井径的相关性最好,相关系数为0.39;电导率和自然电位的相关系数为-0.22,表明测井数据之间具有一定的相关性,同时,离散数据与复杂环境下岩层实际环境的关系将更密切。
2 理论和方法
2.1 SMOTE-LSTM模型
针对地层的岩性数据有限与不均匀性,导致少数类岩性和薄层砂岩预测准确率低或难以预测的问题,以及传统方法在测井数据解释时忽略测井数据空间的关联性和时序性的问题,运用SMOTE算法对岩性数据进行平衡处理使不同岩性数量和占比基本达到一致。在此基础上搭建SMOTE-LSTM模型,调整模型结构和优化超参数进行训练和验证,实现一维钻孔岩性的精细刻画。
模型输入数据内容为深度、不同深度测井数据,由SMOTE-LSTM模型对输入多维度序列数据进行分析处理,得到测井岩性编录预测结果,并基于评估指标通过混淆矩阵量化模型的准确度,借助常规机器学习算法对比模型先进性和更精细的准确性,流程如图2所示。
图2
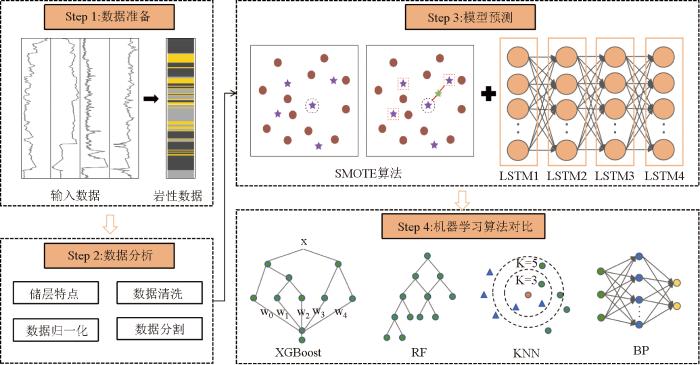
图2
SMOTE-LSTM算法流程示意与主要机器学习算法对比
Fig.2
Comparison between SMOTE-LSTM algorithm flow chart and main machine learning algorithms
2.1.1 SMOTE算法
2.1.2 LSTM算法
LSTM算法创新性引入单元状态机制实现信息的选择性保留和遗忘,从而有效捕捉数据中的长期依赖关系[23]。LSTM算法的结构由遗忘门、输入门、记忆细胞和输出门4个关键组件构成[24]。在每个时间步,LSTM接收当前的测井参数数据输入以及上一时间步的隐藏状态。首先,通过遗忘门对当前时间步的输入和上一时间步的隐藏状态进行处理,决定哪些旧的测井参数信息应该被遗忘;接着输入门利用sigmoid层决定哪些新的测井参数信息值得被接纳,同时tanh层生成新的候选记忆细胞状态,两者结合后更新到记忆细胞中;最后,输出门基于当前时间步的输入、上一时间步的隐藏状态以及更新后的记忆细胞,通过sigmoid层决定哪些信息应被输出为当前时间步的岩性预测隐藏状态[25]。这一过程在整个测井参数序列数据中迭代进行,从而有效地捕捉测井参数与岩性之间的长期依赖关系,实现精准的岩性预测。2.1.3 SMOTE-LSTM模型结构及超参数优化
模型以自然伽马、井径、自然电位和电导率4种测井数据为模型输入,岩性数据为模型输出,首先对测井数据进行数据清洗,同时排除未定义数据与离群数据,为确保不同测井数据间,尽管存在量纲不同和数值差异的问题,仍能进行有效的比较和加权处理[26]。研究采用的标准化方法为最大最小归一化方法,将数据映射到[0,1]区间。具体公式为:
在归一化的基础上,搭建SMOTE-LSTM岩性智能识别模型,模型主要利用LSTM层捕捉数据中的长期依赖关系,并通过独特的门控机制有选择地记忆和遗忘信息,从而在处理SMOTE生成的合成少数类样本时能够更好地分辨有意义的模式与噪声。
在SMOTE-LSTM模型中,增加LSTM层数可以提高模型的复杂度和捕捉深层时序特征的能力,并使网络能够构建更抽象的数据表示,模型中LSTM层为3、4层时模型训练、验证集的准确率均高于87%(图3),但层数的增加也会导致过拟合和梯度传播困难问题,当LSTM层分别设置为5、6、7层时,模型预测准确率不断下降,表明层数为4时达到最佳收敛能力。隐藏层神经单元数则直接决定网络的参数复杂度和特征表征能力,当隐藏层单元数目较小时,模型参数量少,特征提取能力受限,模型中隐藏层尺寸为2,训练集和验证集的准确率均较低,分别为88.2%和85%(图3c),当尺寸大于4后,模型具备更强大的表征空间和非线性映射能力,训练集和验证集准确率均上升到90%以上,但不再随着尺寸增大而增大,是由于隐藏层数量越大,容易过拟合且导致计算速度变慢,因此本次研究采用隐藏层神经单元数为4。
图3
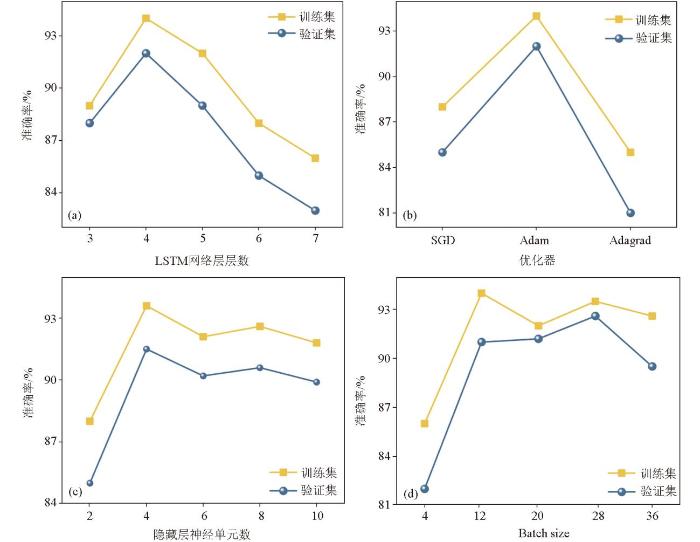
图3
SMOTE-LSTM模型训练集、验证集准确率随(a)LSTM网络层层数、(b)优化器种类、(c)隐藏层神经单元数、(d)Batch size参数变化趋势
Fig.3
The accuracy of SMOTE-LSTM model training set and verification set varies with (a) the number of LSTM network layers, (b) the type of optimizer, (c) the number of neural units in hidden layer, and (d) Batch size parameters
此外,适当的优化器不仅能提高模型对少数类样本的敏感度,还能更好地区分SMOTE生成样本中的有用信息与噪声,平衡准确率与泛化能力。研究中模型综合对比Adam优化器、SGD(随机梯度下降)、Adagrad(自适应梯度优化器)3类优化器,结果显示Adam优化器取得最优的预测性能,模型的训练、验证过程准确率分别达到94.5%、91.6%(图3b),原因是Adam优化器结合动量和自适应学习率的优点,在快速收敛的同时对SMOTE生成的合成样本噪声有较强的鲁棒性。因而研究优化算法采用Adam优化器和Dropout正则化方法,通过自适应调整学习率防止过拟合现象发生,模型得到更快的收敛速度和稳定性。
Batch size是指训练模型时一次性处理的样本数量,大小将影响模型训练效率和稳定性。较大的批量大小使梯度更新稳定且噪声更小,收敛路径更为平滑,较小的批量大小带来更频繁的参数更新和更高的随机性,使模型更敏感地响应每个样本,特别是少数类样本的梯度信息,有利于跳出局部最优。模型中Batch size大于12小于36时(图3d),模型预测准确率均不稳定,综合准确率和稳定性研究选取Batch size数值为28。
综上,在上述模型参数设置的基础上,当模型学习率、迭代次数分别设置为0.001、100时,为模型相对最优的超参数,模型LSTM层激活函数设置为relu函数,全连接层激活函数设置为Softmax函数。
本次研究属于多分类算法模型,采用交叉熵损失函数表示算法误差:
式中:p(ym)表示真实标签数据的概率值;p(om)表示预测标签数据的概率值。
2.2 评估指标
精确率是模型预测为正类的样本中,实际为正类的样本比例,用于衡量模型在正类预测上的准确性,计算公式为:
式(3)、(4)中:TP为正类样本被正确预测为正类的数量;FN为正类样本被错误预测为负类的数量;TN为负类样本被正确预测为负类的数量;FP为负类样本被错误预测为正类的数量。
3 结果与讨论
3.1 岩性预测
在模型训练过程中,随着迭代次数的增加模型性能显著提升。具体而言,训练、验证阶段的准确率分别可达到94%、92%(图4),且曲线趋势基本一致,模型不存在过拟合现象,模型损失函数值最终稳定在0.5以下,数据指标充分展示模型的卓越鲁棒性,预测结果与实际岩性数据高度吻合。
图4
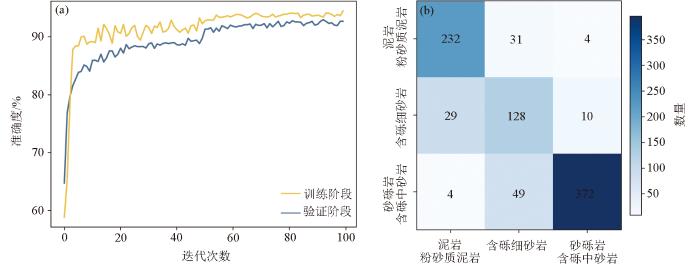
图4
模型训练集与验证集的准确率趋势(a)和模型混淆矩阵分类结果(b)
Fig.4
The trend chart of accuracy of model training set and verification set (a) and classification result of model confusion matrix (b)
图5
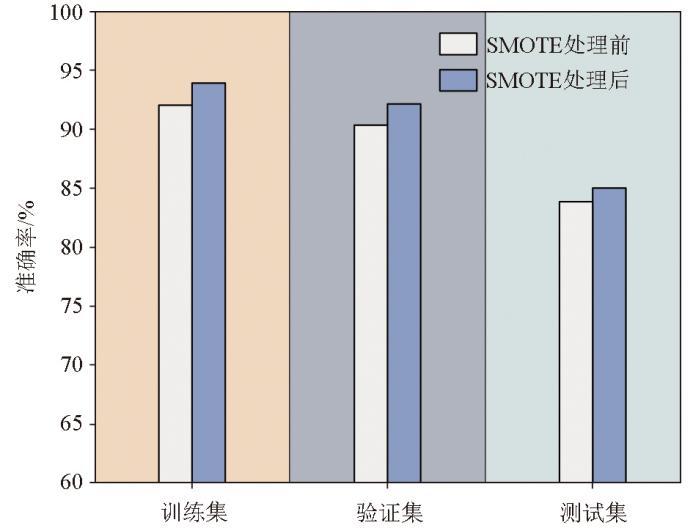
图5
测试井经SMOTE算法处理前后准确率对比
Fig.5
Comparison of accuracy of test wells before and after SMOTE algorithm processing
3.2 方法对比
结果显示(图6)SMOTE-LSTM模型预测准确率显著优于KNN和RF模型,分别存在25.6%、17.4%的差异,主要在于KNN和RF模型在区分泥岩和含砾细砂岩方面存在较多误判,基于薄层岩性识别,RF和KNN模型同样出现较多误差;相较于XGBoost和BP模型,SMOTE-LSTM模型虽然准确率优势不太明显,但在预测精确度方面表现出显著优势,分别提升了4.6%、3.4%,原因在于XGBOOST和BP模型在某些薄层岩性的识别上存在预测盲区,而SMOTE-LSTM模型通过时序门控机制实现对测井垂向数据前后关联性的控制。
图6
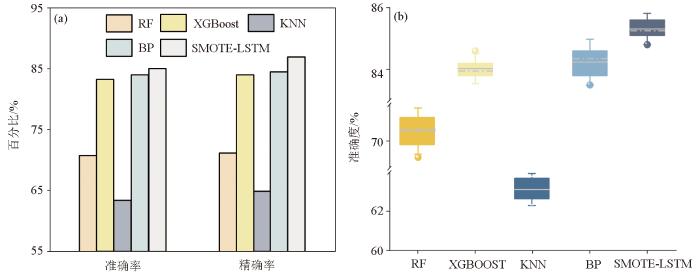
图6
岩性识别算法模型准确率、精确率对比(a)和对比模型十折交叉验证结果(b)
Fig.6
Comparison of accuracy and accuracy of lithologic identification algorithm model (a) and ten-fold cross-validation results of comparison model (b)
此外,为量化模型可靠性,研究采用十折交叉验证方式,通过多次训练、测试来降低评估结果的偶然性。研究随机抽取7口井数据构建训练集用于模型参数学习,选取2口井数据作为验证集进行超参数优化,1口井数据作为独立测试集评估最终性能,重复执行十次以确保评估的统计有效性。通过多次交叉验证,模型学习不同地质环境下的通用特征,减少单井特性对模型的误导。结果表明,SMOTE-LSTM联合模型预测准确率在中位数附近聚集,预测性能指标高度一致,准确率均处于84.5%~86.0% (图6b),模型具有稳定性。而XGBOOST算法和KNN算法同样具有稳定的预测能力,但预测性能远低于SMOTE-LSTM联合模型。
图7
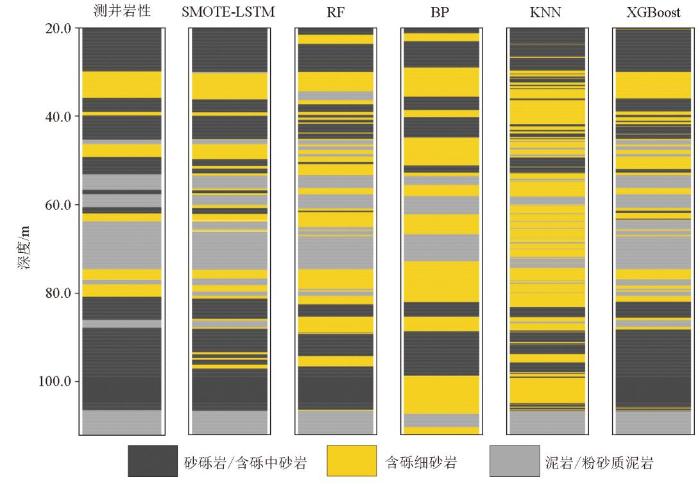
图7
BC-10号测试井预测岩性与真实岩性对比
Fig.7
Comparison between predicted lithology and real lithology of BC-10 test well
表1 SMOTE-LSTM联合模型预测结果参数特征
Table 1
| 岩性 | 精确率/% | 准确率/% | 数目 |
|---|---|---|---|
| 泥岩粉砂质泥岩 | 88 | 87 | 267 |
| 含砾细砂岩 | 62 | 77 | 167 |
| 砂砾岩含砾中砂岩 | 96 | 88 | 425 |
| 权重平均 | 87 | 85 | 859 |
然而,模型仍存在一些识别误差,其中含砾细砂岩的精确率、准确率分别为62%、77%,主要表现在两个方面:部分含砾细砂岩被错误识别为砂砾岩或含砾中砂岩、某些泥岩和粉砂质泥岩被误判为含砾细砂岩,这些误差主要来源于模型在预测时倾向于选择样本量较大的岩性类别,以及选择与预测点特征相似度较高的数据类别。但是SMOTE-LSTM联合模型总体预测精确率为87%,准确率为85%,预测性能最为稳定,综合表现远超其他4种模型。
4 结论
1)经代表性测井数据与岩性编录数据的检验,模型在训练区域岩性准确率超过94%,在验证区域岩性准确率超过92%;测试集成功率为85.1%,其中岩层砂砾岩、含砾中砂岩预测准确率达88%,泥岩、粉砂质泥岩预测准确率达87%,改善了少数类岩性的预测效果,验证了模型对于复杂储层高精度识别相似岩石相能力,同时,数据表明SMOTE算法有效提高了LSTM模型预测能力。
2)模型通过数据平衡和对于测井垂向数据前后关联性的控制,提高了薄层岩性预测准确率,预测性能高于RF、BP、XGBoost、KNN等机器学习算法,表现出一定的优越性。
参考文献
岩性识别:方法、现状及智能化发展趋势
[J].
Lithology identification: Method,research status and intelligent development trend
[J].
基于深度学习的测井岩性识别方法研究与应用
[J].
Research and application of logging lithology identification based on deep learning
[J].
Performance evaluation of machine learning-based classification with rock-physics analysis of geological lithofacies in Tarakan Basin,Indonesia
[J].DOI:10.1016/j.petrol.2021.109250 URL [本文引用: 1]
交会图技术在火山岩岩性与裂缝识别中的应用
[J].
Application of crossplot technique to the determination of lithology composition and fracture identification of igneous rock
[J].
Integrated geological and geophysical investigations to characterize the anthropic layer of the Palatine hill and Roman Forum
[J].DOI:10.1007/s10518-013-9460-5 URL [本文引用: 1]
Multidomain petrophysically constrained inversion and geology differentiation using guided fuzzy c-means clustering
[J].
地震波阻抗反演技术的现状和发展
[J].地球物理反演是利用观测数据恢复地下地质结构和岩石性质的方法。介绍了地震反演技术从直接反演到模型反演,从线性反演到非线性反演,以及从叠后反演到叠前反演的发展过程。弹性波阻抗反演的出现将成为反演进一步发展的方向之一,地震反演正走向声波波阻抗与弹性波阻抗相结合的道路。
The present and future of wave impedance inversion technique
[J].Geophysical inversion is a computational process to restore subsurface geological structures and petrophysical properties from observed geophysical data.This paper outlined the evolution of seismic inversion technologies, from direct inversion tomodel based inversion, from linear inversion to nonlinear inversion, and from poststack inversion to prestack inversion. The inversion of elastic impedance will be one of directions of inversion development.Seismic inversion is on the way of integrating acoustic impedance with elastic impedance.
Lithology prediction method of coal-bearing reservoir based on stochastic seismic inversion and Bayesian classification:A case study on Ordos Basin
[J].
DOI:10.1093/jge/gxac033
URL
[本文引用: 1]

The Upper Palaeozoic coal measures in the Ordos Basin are rich in unconventional natural gas resources; however, the reservoir heterogeneity is relatively strong, which majorly restricts the accuracy of lithology prediction. Stochastic seismic inversion can synthesize the geological–geophysical information and establish high-resolution reservoir models based on geostatistical theory to obtain good inversion results; moreover, it can characterize reservoir lithology and fluid-bearing properties. The present study aimed to propose a high-precision lithology classification method for coal-bearing strata in the Ordos Basin, using Bayesian classification and stochastic seismic inversion. Initially, the reservoir geological model was established on the basis of the sequential Gaussian simulation algorithm, and stochastic seismic inversion was performed in combination with rock physics analysis, thereby obtaining a high-resolution elastic parameter data volume. Thereafter, the probability density function (PDF) and the probability density confusion matrix (PDF confusion matrix) were introduced to quantitatively analyse the ability of sensitive elastic parameters to distinguish lithology. Eventually, a logging lithology-fluid classification template was established based on the Bayesian classification technology; furthermore, a 3D lithology-fluid prediction was completed in combination with the inversion results. The prediction results are in good accordance with the logging data, which verifies the feasibility and effectiveness of the method.
人工智能在石油勘探开发领域的应用现状与发展趋势
[J].
DOI:10.11698/PED.2021.01.01
[本文引用: 1]
针对石油勘探开发的实际需求,阐述了人工智能技术在石油勘探开发领域的研究进展与应用情况,探讨并展望未来人工智能技术在石油勘探开发领域的发展方向与发展重点。机器学习在岩性识别、测井曲线重构、储集层参数预测等测井处理解释方面初步应用,并显现出巨大潜力;计算机视觉技术在初至波拾取、断层识别等地震处理解释方面应用已有成效;油藏工程领域深度学习和最优化技术已开始应用于水驱开发实时调控、产量预测等方面;数据挖掘在钻完井、地面工程等领域的应用初步形成了智能化装备、一体化软件。未来人工智能在石油勘探开发领域潜在的发展方向为智能生产装备、自动处理解释和专业软件平台,发展重点为数字盆地、快速智能成像测井仪器、智能化节点地震采集系统、智能旋转导向钻井、智能化压裂技术装备、分层注采实时监测与控制工程等技术。表1参19
Application and development trend of artificial intelligence in petroleum exploration and development
[J].
DOI:10.1016/S1876-3804(21)60001-0
[本文引用: 1]
Aiming at the actual demands of petroleum exploration and development, this paper describes the research progress and application of artificial intelligence (AI) in petroleum exploration and development, and discusses the applications and development directions of AI in the future. Machine learning has been preliminarily applied in lithology identification, logging curve reconstruction, reservoir parameter estimation, and other logging processing and interpretation, exhibiting great potential. Computer vision is effective in picking of seismic first breaks, fault identification, and other seismic processing and interpretation. Deep learning and optimization technology have been applied to reservoir engineering, and realized the real-time optimization of waterflooding development and prediction of oil and gas production. The application of data mining in drilling, completion, and surface facility engineering etc. has resulted in intelligent equipment and integrated software. The potential development directions of artificial intelligence in petroleum exploration and development are intelligent production equipment, automatic processing and interpretation, and professional software platform. The highlights of development will be digital basins, fast intelligent imaging logging tools, intelligent seismic nodal acquisition systems, intelligent rotary-steering drilling, intelligent fracturing technology and equipment, real-time monitoring and control of zonal injection and production.
K最近邻算法理论与应用综述
[J].
DOI:10.3778/j.issn.1002-8331.1707-0202
[本文引用: 1]
k最近邻算法(kNN)是一个十分简单的分类算法,该算法包括两个步骤:(1)在给定的搜索训练集上按一定距离度量,寻找一个k的值。(2)在这个kNN算法当中,根据大多数分为一致的类来进行分类。kNN算法具有的非参数性质使其非常易于实现,并且它的分类误差受到贝叶斯误差的两倍的限制,因此,kNN算法仍然是模式分类的最受欢迎的选择。通过总结多篇使用了基于kNN算法的文献,详细阐述了每篇文献所使用的改进方法,并对其实验结果进行了分析;通过分析kNN算法在人脸识别、文字识别、医学图像处理等应用中取得的良好分类效果,对kNN算法的发展前景无比期待。
Survey on theory and application of K-Nearest-neighbors algorithm
[J].
DOI:10.3778/j.issn.1002-8331.1707-0202
[本文引用: 1]
K nearest neighbor(kNN) algorithm is a simple classification algorithm, the algorithm consists of two steps: (1)Find out a set of k on a given search training set measure at a distance. (2)The classification is according to the most consistent classes in this kNN algorithm. The non-parametric property of kNN algorithm makes it very easy to implement, and its classification error is restricted by two times of the Bayes error. Therefore, the kNN algorithm is still the most popular choice for pattern classification. This paper summarizes many literatures by using kNN algorithm, expounding the improvement methods used in each document, and analyzing the experimental results. By analyzing the kNN algorithm in face recognition, text recognition, medical image-processing and other applications achieved good classification results, this paper is very promising for the development of kNN algorithm.
Lithology identification using an optimized KNN clustering method based on entropy-weighed cosine distance in Mesozoic strata of Gaoqing field,Jiyang depression
[J].DOI:10.1016/j.petrol.2018.03.034 URL [本文引用: 1]
随机森林算法研究综述
[J].
A review of random forests algorithm
[J].
Accuracy comparison of various remote sensing data in lithological classification based on random forest algorithm
[J].DOI:10.1080/10106049.2022.2088859 URL [本文引用: 1]
支持向量机理论与算法研究综述
[J].
An overview on theory and algorithm of support vector machines
[J].
火山岩岩性的支持向量机识别
[J].
DOI:10.7623/syxb201302013
[本文引用: 1]
提出了用9种火山岩的岩石类型描述火山岩储层岩性的模型,表达岩性对优质储层的控制作用。基于该模型,选取了对火山岩的岩性、组构、成因和孔隙结构反应灵敏的15种岩石物理测井参数,分别采用多元回归分析(MRA)、人工神经网络(ANN)和支持向量机(SVM)3种机器学习算法,尝试火山岩岩性的识别。在三塘湖盆地马朗凹陷牛东油田的实例中,使用了3口井的数据,其中N9-10井和N9-19井的火山岩储层为学习样本,N8-10井的火山岩储层为预测样本。利用N9-10井1361个样本和N9-19井881个样本(每个样本含15种测井参数及岩性),通过这3种机器学习算法分别获得预测火山岩岩性的知识;然后,利用N8-10井961个样本(每个样本仅含15种测井参数),根据上述学习获得的知识,得到这961个样本的岩性。研究发现:对于学习样本,MRA、ANN和SVM的计算与实际的平均相对误差绝对值分别为51.84%,48.66%和0;对于预测样本,则分别为52.44%,46.31%和6.30%。实例分析表明,只有SVM适用于本实例,这是由于火山岩岩性与15种岩石物理测井参数的非线性关系十分强烈。
identification of lithologic characteristics of volcanic rocks by support vector machine
[J].
基于XGBoost的特征选择算法
[J].
DOI:10.11959/j.issn.1000-436x.2019154
[本文引用: 1]
分类问题中的特征选择一直是一个重要而又困难的问题。这类问题中要求特征选择算法不仅能够帮助分类器提高分类准确率,同时还要尽可能地减少冗余特征。因此,为了在分类问题中更好地进行特征选择,提出了一种新型的包裹式特征选择算法XGBSFS。该算法借鉴极端梯度提升(XGBoost)算法中构建树的思想过程,通过从3个重要性度量的角度来衡量特征的重要性,避免单一重要性度量的局限性;然后通过改进的序列浮动前向搜索策略(ISFFS)搜索特征子集,使最终得到的特征子集有较高的质量。在8个UCI数据集的对比实验中表明,所提算法具有很好的性能。
Feature selection algorithm based on XGBoost
[J].
DOI:10.11959/j.issn.1000-436x.2019154
[本文引用: 1]
Feature selection in classification has always been an important but difficult problem.This kind of problem requires that feature selection algorithms can not only help classifiers to improve the classification accuracy,but also reduce the redundant features as much as possible.Therefore,in order to solve feature selection in the classification problems better,a new wrapped feature selection algorithm XGBSFS was proposed.The thought process of building trees in XGBoost was used for reference,and the importance of features from three importance metrics was measured to avoid the limitation of single importance metric.Then the improved sequential floating forward selection (ISFFS) was applied to search the feature subset so that it had high quality.Compared with the experimental results of eight datasets in UCI,the proposed algorithm has good performance.
XGBoost算法在致密砂岩气储层测井解释中的应用
[J].
XGBoost algorithm applied in the interpretation of tight-sand gas reservoir on well logging data
[J].
论基于MATLAB语言的BP神经网络的改进算法
[J].
On the improving backpropagation algorithms of the neural networks based on MATLAB language:A review
[J].
A lithology identification method for continental shale oil reservoir based on BP neural network
[J].DOI:10.1088/1742-2140/aaa4db URL [本文引用: 1]
二连盆地中部古河道砂岩型铀矿成矿特征
[J].
Characteristics of paleo-valley sandstone-type uranium mineralization in the middle of erlian basin
[J].
统计相关性分析方法研究进展
[J].
Survey of research process on statistical correlation analysis
[J].
SMOTE for learning from imbalanced data:Progress and challenges,marking the 15-year anniversary
[J].
DOI:10.1613/jair.1.11192
URL
[本文引用: 1]
The Synthetic Minority Oversampling Technique (SMOTE) preprocessing algorithm is considered \"de facto\" standard in the framework of learning from imbalanced data. This is due to its simplicity in the design of the procedure, as well as its robustness when applied to different type of problems. Since its publication in 2002, SMOTE has proven successful in a variety of applications from several different domains. SMOTE has also inspired several approaches to counter the issue of class imbalance, and has also significantly contributed to new supervised learning paradigms, including multilabel classification, incremental learning, semi-supervised learning, multi-instance learning, among others. It is standard benchmark for learning from imbalanced data. It is also featured in a number of different software packages - from open source to commercial. In this paper, marking the fifteen year anniversary of SMOTE, we reflect on the SMOTE journey, discuss the current state of affairs with SMOTE, its applications, and also identify the next set of challenges to extend SMOTE for Big Data problems.
Learning to forget:Continual prediction with LSTM
[J].
DOI:10.1162/089976600300015015
PMID:11032042
[本文引用: 1]
Long short-term memory (LSTM; Hochreiter & Schmidhuber, 1997) can solve numerous tasks not solvable by previous learning algorithms for recurrent neural networks (RNNs). We identify a weakness of LSTM networks processing continual input streams that are not a priori segmented into subsequences with explicitly marked ends at which the network's internal state could be reset. Without resets, the state may grow indefinitely and eventually cause the network to break down. Our remedy is a novel, adaptive "forget gate" that enables an LSTM cell to learn to reset itself at appropriate times, thus releasing internal resources. We review illustrative benchmark problems on which standard LSTM outperforms other RNN algorithms. All algorithms (including LSTM) fail to solve continual versions of these problems. LSTM with forget gates, however, easily solves them, and in an elegant way.
A review of recurrent neural networks:LSTM cells and network architectures
[J].
DOI:10.1162/neco_a_01199
URL
[本文引用: 1]
Recurrent neural networks (RNNs) have been widely adopted in research areas concerned with sequential data, such as text, audio, and video. However, RNNs consisting of sigma cells or tanh cells are unable to learn the relevant information of input data when the input gap is large. By introducing gate functions into the cell structure, the long short-term memory (LSTM) could handle the problem of long-term dependencies well. Since its introduction, almost all the exciting results based on RNNs have been achieved by the LSTM. The LSTM has become the focus of deep learning. We review the LSTM cell and its variants to explore the learning capacity of the LSTM cell. Furthermore, the LSTM networks are divided into two broad categories: LSTM-dominated networks and integrated LSTM networks. In addition, their various applications are discussed. Finally, future research directions are presented for LSTM networks.
循环神经网络研究综述
[J].
Overview of recurrent neural networks
[J].
A study of standardization of variables in cluster analysis
[J].DOI:10.1007/BF01897163 URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}