

0 引言
岩性识别是地质研究工作中必不可少的一部分,准确高效的岩性识别具有重要的应用价值[1]。在矿产资源勘探中,尤其是在固体金属矿产资源勘探中,岩性识别发挥着不可估量的作用,岩性识别可以提供特定的地质信息, 刻画地下岩矿石的空间分布状态,为矿产勘探提供坚实的地质基础。准确识别岩性是确定储层孔隙度和含油饱和度必不可少的前提。
目前岩性识别方法有直接手段和间接手段。直接手段有岩心取样、手标本及薄片鉴定等,但获取样品的成本很高,并需要进行后续的实验分析鉴定岩性。间接手段主要有地质填图以及地球化学、地球物理、遥感等方法,其中地质填图受深度限制,只能反映浅地表的岩性分布,遥感技术探测在植被覆盖区域难于获取有效信息而限制其采纳几率,因此地球物理方法在深部岩性识别中发挥着重要作用。岩石的物理性质(密度、磁化率、电阻率、波阻抗等)是连接岩性与地球物理场的桥梁,因此可以通过地球物理手段,如重力、磁力、地震等方法反演岩石物性,再根据物性与岩性对应的逻辑关系,判断岩性的空间展布。目前的地球物理手段中,重、磁力反演在无约束的情况下分辨率较差、多解性强,地震反演具有较高的分辨率,但作业成本高昂,不适用于大面积的岩性识别研究[2⇓-4];测井手段主要利用交会图版法或者基于统计、聚类等方法进行岩性识别[5⇓⇓⇓-9],此技术在纵向储层岩性识别中应用较为广泛,但无法进行横向的岩性识别,并且测井数据在交会图上存在重叠区域,不适用于复杂岩性的分类问题。
本文将基于特征加权的K近邻(KNN)方法应用于岩性识别中,实现从物性到岩性的转换。K近邻方法的直观思想是:给定已知的训练数据集,选择距离函数计算待分类样本和训练样本之间的距离,选取距离最小的K个样本作为“近邻”,将待分类样本归属于K个近邻样本所属类别最多的数类。K近邻算法直观、简洁有效,所需要调整的参数少,不做额外的假设,具有通用性,可以用于分类、回归和搜索等应用[15]。但是K近邻算法也存在着一些缺点,首先该算法是一种惰性学习方法,直到有样本需要分类时才建立分类器,将已知样本和未知样本逐个计算相似程度,计算量大、分类效率低;其次K值的选择也会影响分类效果,K值较小容易导致“过拟合”,K值较大容易导致模型的近似误差增大;传统KNN方法将输入的每个属性赋予相同的权值,忽略了各个属性在实际工作中对分类结果的重要程度不同,影响了分类结果的准确性。
针对KNN算法中分类结果受K值选取影响较大的问题,孙可等[18]引入稀疏学习理论,提出SA-KNN算法,通过局部保持投影LPP重构测试样本,利用
面对数据集的众多分类特征,如何选择合适的指标评价特征属性的重要程度是至关重要的。传统KNN算法中,计算待分类点到训练样本之间的距离时,将所有属性都同等对待,但实际工作中,岩性分布一般是复杂多样的,各个属性在分类中所起的作用是不同的,有的起关键作用,有的甚至不起作用。因此,针对不同特征在特征距离计算时所占据的重要程度不同,并考虑到传统KNN算法对容量少的样本存在误判的情况,本文将一种基于特征加权的KNN识别方法应用于岩性识别中,利用信息增益确定每个特征属性的重要程度,信息增益越大,特征的重要程度就越高,计算不同特征值的权重,将其代入距离公式中,从距离上扩大相似数据之间的区别。
1 基本原理
1.1 K近邻分类
K近邻方法(KNN)首先由Cover等[23]于1967年提出,属于统计模式识别方法,其思想就是计算未知类别样本与已知类别样本之间的距离,根据距离度量,找出与未知类别样本距离最小的K个近邻样本,以“少数服从多数”原则判别未知样本类型。具体流程为:
1)选择距离度量函数,一般选择欧式距离,计算待测样本与邻近样本间距离值:
其中:
2)对计算出的距离值进行排序,选前K个最小距离的样本作为近邻样本。
3)确定前K个样本类别出现的频率。
4)返回前K个点出现频率最高的类别,即出现频率最高的类别就是预测的未知样本类别。
KNN方法无需事先训练模型,模型结构简单有效,其准确度和灵敏度都很高,是向量空间模型(VSM)下最好的分类算法之一[24]。KNN模型只有一个参数K,需要对参数K进行优化,寻找最佳K值。
交叉验证(cross-validation)[25]是常用的选取最优化模型参数的方法,在可用数据较少的情况下,通过对数据的有效重复利用,选出最为合适的模型参数。交叉验证的思想为将训练集交叉拆分为不同的训练集和验证集,使用拆分出的训练集和验证集分别测试模型的精度,求出精度的均值就是交叉验证的结果。将交叉验证作用到不同的参数中,选取精度最高的参数作为模型参数即可。
常见的交叉验证方法有简单交叉验证(holdout cross validation),L折交叉验证(L-fold cross validation)和留一交叉验证(leave-one-out cross validation)。本文使用的是L折交叉验证,所有数据都会参与到训练和预测中,可以有效地避免过拟合以及欠拟合情况的发生,具体做法为:
1)随机将原始训练集划分为L个互不相交、大小相等的子集;
2)将其中1份作为测试集,其余L-1份为训练集,进行模型的训练和评估;
3)将上一步重复L次(每次选择不同子集作为测试集),将L次评估指标的平均值作为最终的评估指标。
交叉验证从有限的数据中尽可能多地获取有效信息,可以用于评估模型的预测性能,在数据量较少的时候更方便找到合适的模型参数,在一定程度上减小模型过拟合。
1.2 特征权重
信息增益表示数据集中某个特征x的信息使类别y的信息的不确定性减小的程度[26],即特征x对类别的贡献程度。若特征为A,训练数据集为D,则特征A对训练集D的信息增益为:
其中:
1)计算训练数据集D的信息熵
其中:
2)计算特征A对数据集D的条件熵
可进一步优化为:
其中:
3)计算信息增益
一般地,信息增益越大,则表示属性x对类别y的不确定程度降低越大,也就是说信息增益越大的特征重要程度越高。根据特征的信息增益构造特征权重,若训练集D共有n个属性,则属性A的权重为:
K近邻模型中的加权欧式距离为:
2 模型测试
2.1 模型设计
图1
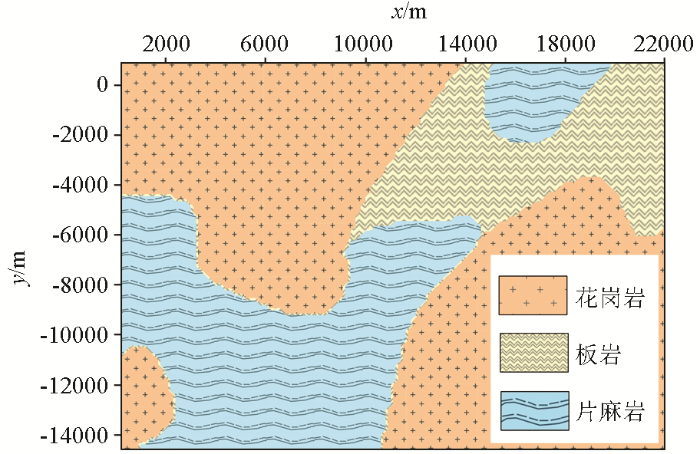
表1 模型物性参数
Table 1
| 岩石名称 | 密度/ (kg·m-3) | 磁化率/ (10-5 SI) | 电阻率/ (Ω·m) |
|---|---|---|---|
| 板岩 | 2630~2850 | 0~160 | 3~8 |
| 片麻岩 | 2570~2830 | 180~280 | 40~60 |
| 花岗岩 | 2580~2640 | 0~160 | 10~30 |
图2

图2
物性参数分布
a—模型密度分布;b—模型磁化率分布;c—模型电阻率分布
Fig.2
Physical properties distribution of the model
a—density distribution of the model;b—magnetic susceptibility distribution of the model;c—resistivity distribution of the model
2.2 数据预处理
由于各物性参数的量纲、数值量级都不相同,将它们直接用于KNN模型会导致量级较高的数据权重较大。为均衡不同特征属性之间的权重,将对输入数据进行数据规范化处理,其本质是对各个属性的取值范围压缩到统一数值区间,消除属性间量纲差异对模型的消极影响。本次使用z-score标准化[27]方法进行规范化处理。
z-score标准化对每个数据变换时假定其满足正态分布,计算公式为:
其中:
2.3 模型评价
图3

图3
250个训练样本物性参数交会图
Fig.3
Interaction diagram of physical property parameters of 250 training samples
图4
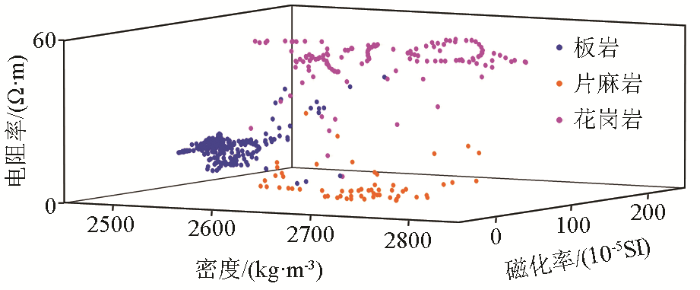
图4
435个训练样本物性参数交会图
Fig.4
Interaction diagram of physical property parameters of 435 training samples
图5
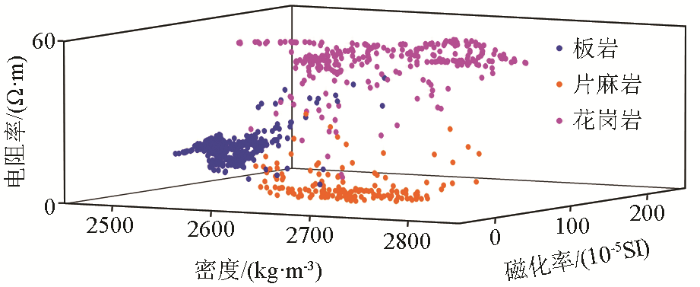
图5
870个训练样本物性参数交会图
Fig.5
Interaction diagram of physical property parameters of 870 training samples
基于上述物性数据,实验得出3种模型的KNN识别结果,并对3种模型识别结果准确度进行了对比。表2是3种模型在K值为1~30下计算出的均值、方差以及均方根误差(RMSE)统计,3种模型的平均识别准确率均在90%以上,识别效果良好。
表2 模型准确率与误差统计
Table 2
| 训练样本/个 | 平均准确率/% | 方差/% | RMSE/% |
|---|---|---|---|
| 250 | 90.22 | 0.42 | 11.68 |
| 435 | 90.81 | 0.52 | 11.58 |
| 870 | 90.09 | 0.26 | 11.09 |
2.4 参数优化
K值逐渐增大时,模型的精度会趋于稳定,但在实际应用中,K值是难以准确界定的:K值过小容易产生“过拟合”现象,模型整体变复杂,容易受到异常点影响;K值过大容易产生“欠拟合”现象,模型整体变得简单,容易受到样本分布不均衡的影响。本次试验使用L折交叉验证方法选取最佳参数K,交叉值L取5,即将训练集平均分为5份,选取一份作为测试集,剩下4份作为训练集,进行5次交叉验证,最后对交叉验证的结果取平均,得到各种K值下的平均准确率,选择平均准确率最大时对应的K值为模型的最佳参数。但在使用交叉验证方法确定最佳K值Kopt前,须先确定K值的搜索范围,也就是最大K值
表3 模型最佳K值及准确率
Table 3
| 训练样本/个 | 最佳K值 | 准确率/% |
|---|---|---|
| 250 | 4 | 91.41 |
| 435 | 20 | 93.95 |
| 870 | 21 | 92.51 |
2.5 基于特征加权模型分析
表4 特征信息增益与权重统计
Table 4
| 样本个数/个 | 特征 | 信息增益值 | 权重值 |
|---|---|---|---|
| 250 | 密度 | 0.8311 | 0.3145 |
| 磁化率 | 0.6502 | 0.2461 | |
| 电阻率 | 1.1610 | 0.4394 | |
| 435 | 密度 | 0.6282 | 0.2628 |
| 磁化率 | 0.7167 | 0.2998 | |
| 电阻率 | 1.0459 | 0.4374 | |
| 870 | 密度 | 0.7041 | 0.2754 |
| 磁化率 | 0.7096 | 0.2776 | |
| 电阻率 | 1.1425 | 0.4470 |
表5 基于特征加权模型准确率与误差统计
Table 5
| 训练样本/个 | 平均准确率/% | 方差/% | RMSE/% |
|---|---|---|---|
| 250 | 93.68 | 0.20 | 7.70 |
| 435 | 93.62 | 0.20 | 7.86 |
| 870 | 93.76 | 0.35 | 8.52 |
图6
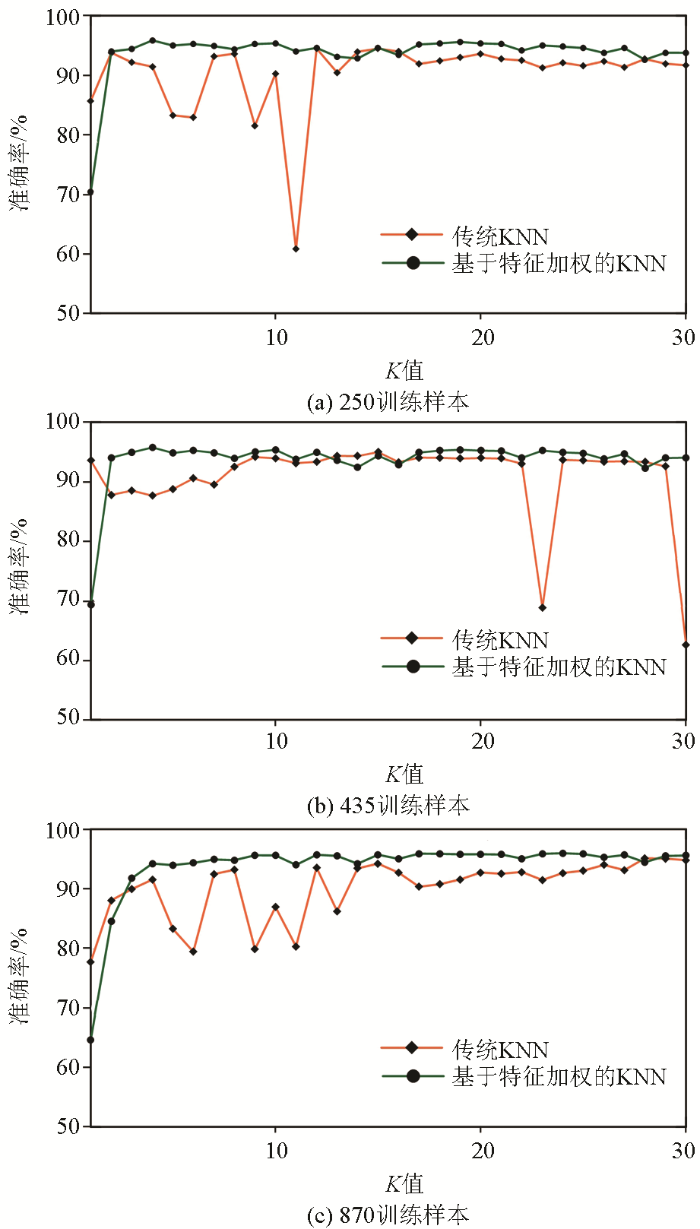
图6
两种模型在不同K值下准确率折线
Fig.6
Accuracy line graph of two models under different K value
表6和图7分别为传统KNN模型和基于特征加权的KNN模型在最佳K值下的错误率统计与岩性识别结果,两者对比发现,基于特征加权的KNN模型的识别性能有显著提升,识别错误率大幅降低,图7中的红色散点为识别错误点,可以看出,基于特征加权的KNN模型的判错点明显少于传统KNN模型,一些集中在岩性分布内部的错误点消失,原来分布在在岩性边界区域的错误点也明显减少,说明该方法对岩性交界处的识别能力有大幅提升。图7d~f还可以看出该模型对3种岩性的识别能力:模型对花岗岩和片麻岩的识别能力更佳,对板岩的识别能力最弱,这可能是受样本数量不均衡的影响,说明基于特征加权的KNN模型对样本容量小的类域容易误分,因此当训练样本取值不均衡时,会导致模型识别性能下降。
表6 模型错误率对比
Table 6
| 训练样本/个 | 最佳K值 | 错误率/% | |
|---|---|---|---|
| 传统KNN方法 | 基于特征加 权的KNN方法 | ||
| 250 | 4 | 8.59 | 4.17 |
| 435 | 20 | 6.05 | 4.78 |
| 870 | 21 | 7.49 | 4.25 |
图7
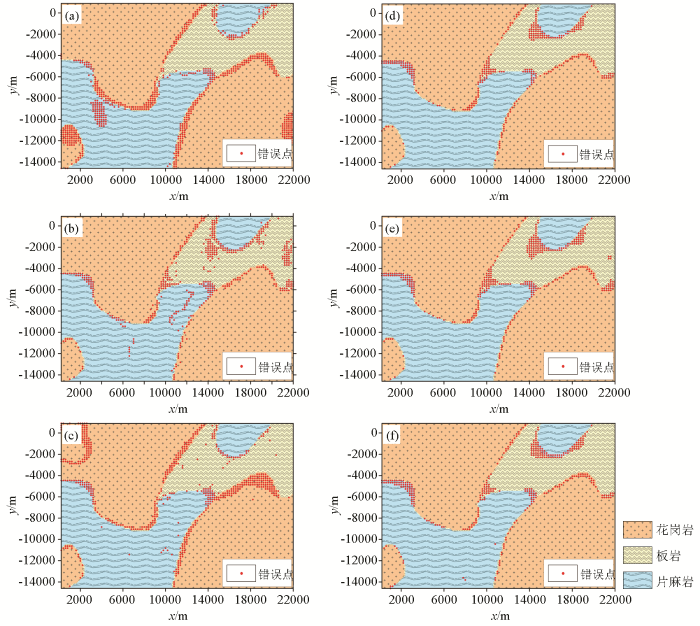
图7
模型在最佳K值下的识别结果
(a)~(c)—250、435、870训练样本在传统KNN模型下的识别结果;(d)~(f)—250、435、870训练样本在基于特征加权KNN模型下的识别结果
Fig.7
The recognition result of the model under the optimal K value
Figures(a) ~ (c) is the recognition results of training samples 250, 435 and 870 under the traditional KNN model. Figures (d) ~ (f) is the recognition junction of 250, 435 and 870 training samples based on the feature-weighted KNN model
3 结论与讨论
本文将基于特征加权的KNN模型应用到岩性识别问题中,结论如下:
1)传统KNN近邻模型的方法在岩性识别中表现良好,在有足够的已知训练样本条件下,不同训练样本数下平均准确率可以达90%以上。KNN算法在模型训练过程中,使用交叉验证方法可以选择关键参数K来确定识别的准确率,本次使用了5折交叉验证方法对参数K进行优化,得到最佳K值。
2)本文将基于特征加权的KNN模型应用到岩性识别中,该方法通过计算特征的信息增益值度量分类特征的重要程度,计算特征权重进行识别,提高了模型的精度和稳定性,该模型较全面地考虑到特征参数的分布对识别结果的影响,使识别结果更符合客观事实。从本文的岩性模型可看出,基于特征加权的KNN模型分类效果整体优于传统KNN模型,在分类精度和稳定性上都有明显的提升,并且在岩性分界处的识别效果有大幅提升,可以较好地识别出岩石的类别和轮廓,但当训练样本取值不均衡时,会导致模型识别性能下降,因此模型不适用于样本类域分布非常不均衡的情况,容易导致误分。
参考文献
A literature review on the improvement of KNN algorithm
[J].The paper points out that the traditional k-nearest neighbor(KNN) algorithm has two shortcomings, one is its high computational complexity, and another is that it gives equal importance to each feature items and neighbor samples during the process of similarity measure and category judgment. According to the first shortcoming, three kinds of improvement strategy are put forward, which are feature reduction, optimization of training set and improvement of neighbor searching method. According to the second shortcoming, two kinds of improvement strategy are put forward, which are feature weighting and sample weighting. Representative method of each strategy is also introduced and commented objectively.
Cross-validatory choice and assessment of statistical predictions
[J].
基于信息增益和基尼不纯度的K近邻算法
[J].
K-nearest neighbor algorithm based on information gain and gini impurity
[J].
岩性识别技术现状与进展
[J].
Current status and progress of lithology identification technology
[J].
综合地球物理方法识别准噶尔盆地的岩性圈闭
[J].
Discussion on identifying method for Identification of lithologic traps in Junggar Basin by comprehensive geophysical method
[J].
基于重磁反演的三维岩性填图试验——以安徽庐枞矿集区为例
[J].
3D lithologic mapping test based on 3D inversion of gravity and magnetic data:A case study in Lu-Zong ore concentration district,Anhui Province
[J].
测井资料交会图法在火山岩岩性识别中的应用
[J].
Application of crossplots based on well log data in identifying volcanic lithology
[J].
基于交会图和多元统计法的神经网络技术在火山岩识别中的应用
[J].
Application of neural networks technique based on crosspiot and multielement statistics to recognition of volcanic rocks
[J].
基于交会图与模糊聚类算法的复杂岩性识别
[J].
Complex lithology identification based on crossplot and fuzzy clustering algorithm
[J].
基于交会图和贝叶斯聚类分析法的岩性识别方法
[J].
Method of lithologic identification based on crossplot and Bayesian cluster analysis algorithm
[J].
测井资料交会图法在火山岩岩性识别中的应用探讨
[J].
Discussion on the application of logging data crossplot method in volcanic rock lithology identification
[J].
岩性识别:方法、现状及智能化发展趋势
[J].
Lithology identification:Method,research status and intelligent development trend
[J].
Lithology identification using an optimized KNN clustering method based on entropy-weighed cosine distance in Mesozoic strata of Gaoqing field,Jiyang depression
[J].DOI:10.1016/j.petrol.2018.03.034 URL [本文引用: 1]
Petrofacies classification using machine learning algorithms
[J].
基于自适应核密度的贝叶斯概率模型岩性识别方法研究
[J].
Lithology identification based on Bayesian probability using adaptive kernel density
[J].
3种经典机器学习算法在火山岩测井岩性识别中的对比
[J].
Comparison of three classical machine learning algorithms for lithology identification of volcanic rocks using well logging data
[J].
基于KNN算法识别合水地区长7储层岩性岩相
[J].
Identification of lithology and lithofacies of Chang 7 reservoir in Heshui area by KNN algorithm
[J].
基于中心向量的多级分类KNN算法研究
[J].
A multi-stage classification KNN algorithm based on center vector
[J].
Fast neighbor search by using revised k-d tree
[J].
DOI:10.1016/j.ins.2018.09.012
[本文引用: 1]

We present two new neighbor query algorithms, including range query (RNN) and nearest neighbor (NN) query, based on revised k-d tree by using two techniques. The first technique is proposed for decreasing unnecessary distance computations by checking whether the cell of a node is inside or outside the specified neighborhood of query point, and the other is used to reduce redundant visiting nodes by saving the indices of descendant points. We also implement the proposed algorithms in Matlab and C. The Matlab version is to improve original RNN and NN which are based on k-d tree, C version is to improve k-Nearest neighbor query (kNN) which is based on buffer k-d tree. Theoretical and experimental analysis have shown that the proposed algorithms significantly improve the original RNN, NN and kNN in low dimension, respectively. The tradeoff is that the additional space cost of the revised k-d tree is approximately O(alpha nlog(n)). (C) 2018 Elsevier Inc.
一种高效的K值自适应的SA-KNN算法
[J].
An efficient SA-KNN algorithm with adaptive Kvalue
[J].
基于属性值相关距离的KNN算法的改进研究
[J].
Research on improvement of KNN algorithm based on correlation distance of attribute values
[J].
基于模糊熵的KNN分类模型在岩性识别中的应用
[J].
DOI:10.3778/j.issn.1002-8331.1709-0084
[本文引用: 1]
KNN分类模型是一种简单直接的惰性分类算法,适用于多分类问题,可应用于复杂岩性识别中。该研究以苏里格气田苏东某区为研究工区,该地区岩性结构复杂多样,其识别是本次研究工作的重点。传统KNN方法在类重叠度高的部分易判错,样本容量小的类域易误分,稀疏类的边缘点易受干扰,分类效果欠佳。为克服缺点,提出了基于模糊熵的KNN分类模型,又称为FE-KNN(Fuzzy Entropy-KNN)。FE-KNN分类模型将传统KNN与模糊理论相结合,区别对待不同特征和不同样本点,使分类的精度由84.7%提高至86.9%,为复杂碳酸盐岩岩性识别提供了一种新的思路。
Application of KNN classification model based on fuzzy entropy in lithology recognition
[J].
DOI:10.3778/j.issn.1002-8331.1709-0084
[本文引用: 1]
The KNN classification model is a simple and direct inert classification algorithm, which is suitable for multi-classification problem and can be applied to complex lithology identification. The southeastern area of Sulige gas field is the research area in this study, and the lithology structure of this area is complex and diverse. Its identification is the focus of this research work. The traditional KNN method is easy to misjudge in the high degree of overlap, and the class domain with small sample size is easy to be misinterpreted. The edge of the sparse class is susceptible to interference, so that the result of classification is ineffective. In order to overcome the shortcomings, the KNN classification model based on fuzzy entropy is proposed, which is called Fuzzy Entropy-KNN(FE-KNN). The FE-KNN classification model combines the traditional KNN with the fuzzy theory, discrimination different characteristics and different sample points. The accuracy of the classification is improved from 84.7% to 86.9%. FE-KNN provides a new idea of complex carbonate rock lithology identification.
Entropy-KNN算法在岩性识别中的应用研究
[J].
Application of entropy-KNN algorithm in lithology identification
[J].
基于特征加权KNN的非侵入式负荷识别方法
[J].
Non-intrusive load identification method based on feature weighted KNN
[J].
Nearest neighbor pattern classification
[J].DOI:10.1109/TIT.1967.1053964 URL [本文引用: 1]
KNN分类算法改进研究进展
[J].指出传统KNN(k-nearest neighbor)算法的两大不足:一是计算开销大,分类效率低;二是在进行相似性度量和类别判断时,等同对待各特征项以及近邻样本,影响分类准确程度.针对第一点不足,提出三种改进策略,分别为:基于特征降维的改进、基于训练集的改进和基于近邻搜索方法的改进;针对第二点不足,提出两种改进策略,分别为:基于特征加权的改进和基于类别判断策略的改进.对每种改进策略中的代表方法进行介绍并加以评述.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}