

0 引言
因此根据区域地质条件选择结构合适的深度学习算法进行地球化学异常识别,对于提高异常靶区圈定成矿的准确率十分关键。对比不同网络结构配置的深度学习算法提取地质背景信息的效果,能为依据研究区域地质背景具体成矿条件选择合适的深度学习模型特征,从而为构建地球化学异常预测模型提供有效依据。
本文基于闽西南坳陷带铜锌银成矿区的1∶20万水系沉积物数据设计了对比实验,利用3种无监督深度学习模型AE(autoencoder,AE)[8]、MCAE(multi-convolutional autoencoder,MCAE)[9]、FCAE(fusion convolutional autoencoder,FCAE)[10]进行地球化学异常识别,分别提取了样本中多元素间的组合结构特征、空间分布特征,以及融合了前两者的混合特征,将其作为区域多元地质特征在深度学习模型中的3种降维表达。为对比3种深度学习模型的综合性能,分别绘制了其ROC曲线和AUC分布,并分析了模型对卷积窗口尺寸变化的敏感度,以了解空间观测尺度变化时模型的抗干扰能力,同时生成了地球化学异常图,并将其与已知矿点位置和断层分布进行对比,进而验证模型预测成矿分布的准确度。
1 地质概况
本次研究选取位于闽西南与粤东北交接地区的一片区域,该区域属于闽西南坳陷带的胡坊—永定隆起带中段西坡。该研究区域是我国重要的铜、银金属成矿带之一,区域地质简图如图1所示。
图1
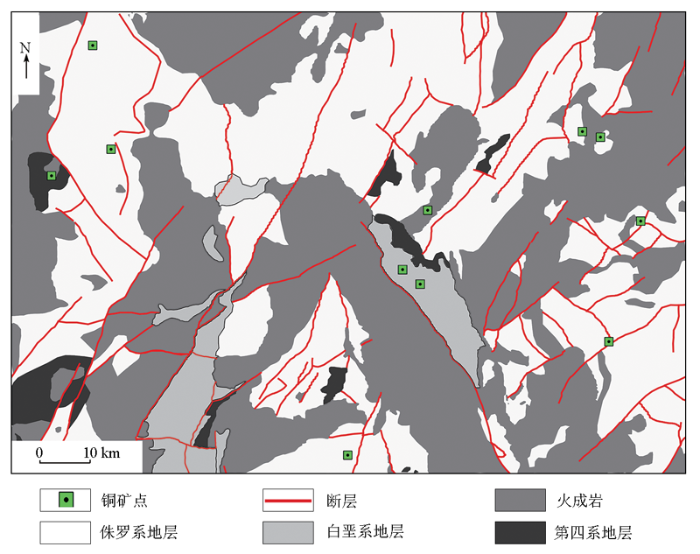
研究区域内各元素异常套合显著,以铜异常浓集中心最明显,但异常较分散,区域内已知铜矿点数量仅11个,已知铜矿资源分布稀疏。该区部分地段已发现铜铝矿化,具有相似的成矿背景,是寻找斑岩型铜矿的有利地区[13]。在该区域地层存在未发现铜矿点的可能性较大,具有重要勘探价值。
2 研究方法
采用不同神经网络进行地球化学异常识别,其效果也不同[14]。本文基于对现有模型的改编,设计了3种无监督深度学习模型AE、MCAE、FCAE,分别基于不同类型的地球化学元素异常特征圈定异常靶区。3种模型的结构是一个灵活的框架,其本质是对深度学习中自编码器神经网络的衍生设计,基于其框架可以采用不同组合的神经网络构建模型,为依据区域地质背景具体成矿条件构建用于地球化学异常识别的适合深度学习的模型提供了设计思路和参考依据。
2.1 特征提取
利用深度学习模型对化探数据进行异常识别,从而得到区域内多元地质特征的降维向量表示,实现对复杂地质条件下区域成矿特征的重构。本文在已有研究的基础上,利用自编码器AE提取样本中多元素间的组合结构特征,多卷积自编码器MCAE提取样本中多元素的空间分布特征,混合卷积自编码器FCAE提取融合以上两种特征的混合特征。
2.1.1 自编码器
图2
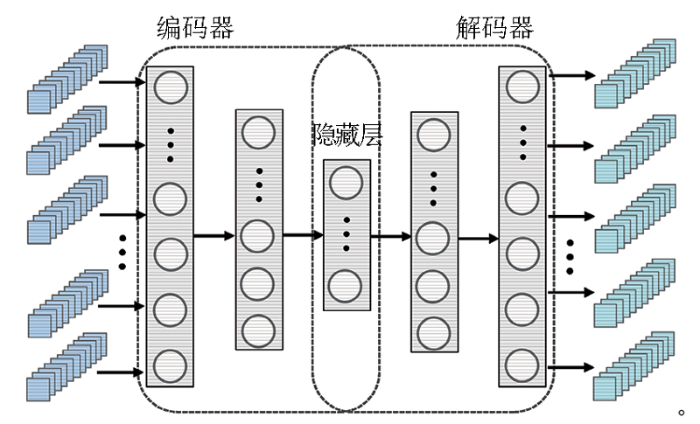
为了提取样本元素间的组合结构特征,AE的输入数据x是以样本为单位的地球化学特征数据。样本元素间的组合结构特征是指样本中所有组分间隐藏的某种组合关系,通过提取该特征,有助于发现与成矿关联最紧密的特征元素组合,降低弱相关组分对成矿预测的干扰。
AE属于无监督学习,其编码器和解码器分别构造了编码函数f(x)和解码函数g(h);表示叉乘,即向量积。
式(1)中Sf为编码器激活函数;h为经过f(x)映射后x的特征表达;Wi和bi分别为编码器输入层到隐藏层之间网络的权重矩阵和偏置矩阵。式(2)中Sg为解码器激活函数;y为经过g(h)映射后x的重构数据;Wj和bj分别为解码器隐藏层到输出层之间网络的权重矩阵和偏置矩阵,其中Wj通常取
式(1)与式(2)中的参数矩阵可用θi={Wi,bi}和θj={Wj,bj}进行表示,模型训练的目的是优化模型参数[θi,θj],使输入x与输出y之间的重构误差达到最小。AE的整体损失函数可定义为:
式中L(x,y)表示x与y之间的重构误差,用于衡量x与y之间的接近程度; N表示样本总数。通过批量梯度下降法在网络中迭代调整AE各层网络的权重和偏置,使损失函数最小化。
由于大多数样品不具备异常特征,因此异常分布的区域通常在研究区域内的面积占比较小。AE通过模型训练能从化探数据中学习到区域的地球化学背景模式,在重构过程中发现重构误差高于一般背景样本的异常样本,从而识别出极少数具有异常特征的样本。
2.1.2 多重卷积自编码器
CAE与AE具备形式类似、含义一致的损失函数。CAE实现异常识别的原理与AE相同,但编码函数和解码函数存在区别,其主要区别在于输入数据x的输入方式不同,以及每层网络的权重和偏置的转换过程不同。
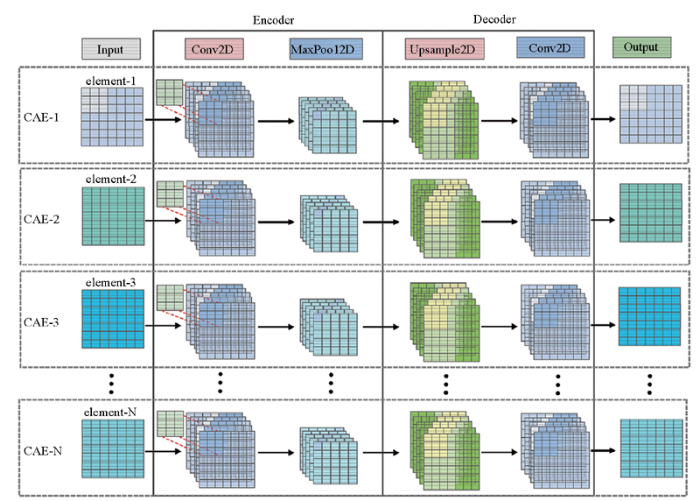
为提取样本中多种元素的空间分布特征,同时组合多个CAE组成了多重卷积自编码器模型(multi-convolutional autoencoder,MCAE),其模型结构如图3所示。MCAE的输入数据是以元素为单位的地球化学特征数据,每个CAE针对提取单个样本元素的空间分布特征。编码和解码过程主要由CNN的参数决定,如卷积核个数、卷积核尺寸等。模型训练的目的与AE相同,使输入x与输出y之间的重构误差达到最小。
图3
2.1.3 混合卷积自编码器
地球化学异常识别模型可用于辅助矿产预测的底层逻辑是,模型会将实际地质背景下的已知矿点识别为异常,通过学习已知矿点作为异常样本的特征,提取区域矿点分布特征信息,以模拟复杂地质环境下的矿产分布,从而辅助预测未知矿点的位置。为了提高异常识别模型预测的准确率,需要在模型中尽可能综合多元地质背景信息。利用混合卷积自编码器模型(fusion convolutional autoencoder,FCAE)提取融合了样本多元素组合结构特征和空间分布特征的混合特征,以在模型中进一步融合区域复杂地质特征信息。
FCAE同时综合了AE和MCAE的结构和优点,其模型结构如图4所示。FCAE由两个子自编码器AE-S和AE-C构成。AE-S是位于FCAE外层的自编码器,由多个CAE构成,相当于MCAE,用于提取样本中多种元素的空间分布特征。AE-C是位于FCAE内层的自编码器,连接了AE-S的编码器和解码器,用于在FCAE模型中融合样本元素之间的组合结构特征。
图4
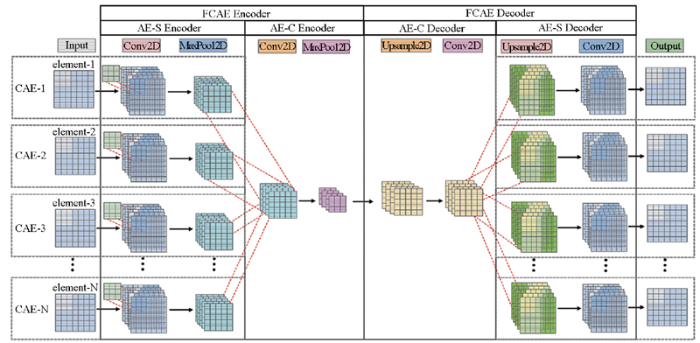
使用FCAE进行异常识别的原理与AE和MCAE相同,模型训练目的都是最小化输入x与输出y的重构误差。训练过程中,FCAE的编码和解码过程在AE-S和AE-C中混合进行。FCAE的输入数据与MCAE输入数据的结构一致,都是以元素为单位的地球化学特征数据。
2.2 异常得分计算
在本项研究中,利用每个样本原始数据和模型重构数据之间的欧式距离作为样本的重构误差,用于定量描述每个样本的异常程度,并将其作为每个样本的异常得分。假设每个样本包含N个观测值(如N个元素的标准化浓度值),则样本i与样本j之间的欧式距离Dij计算为:
式中:xik表示样本i第k个观测值;xjk同理。样本的异常得分越大,说明该样本的异常程度越明显,该样本成为异常样本的概率越大。
2.3 性能评估
在评价不同深度学习模型异常识别效果的过程中,必须考虑异常样本占总样本和异常样本占已知矿点样本的比例,以确定模型圈定靶区预测矿产分布的准确度。受试者工作特征曲线(receiver operating characteristic curve, ROC)经常被用于评价分类预测模型的性能[26],目前已被广泛应用于分类预测模型的评价,本文基于ROC曲线对模型进行定量对比评价。
ROC曲线的曲线下面积(area under curve,AUC)是用于定量描述预测模型预测准确度的常用指标,当AUC∈(0.5,1)时说明模型预测达到了可接受的精度。通常情况下,ROC曲线越陡峭,越靠近左上角的(0,1)坐标,则说明ROC曲线的AUC值越大,预测模型性能越好。
利用ROC曲线确定异常样本和背景样本的最佳区分阈值的具体做法如下:首先利用已知矿点和样本异常得分绘制ROC曲线,取ROC曲线上距离左上角(0,1)最近的一点作为最佳临界点,取该点的异常得分作为异常得分的最佳区分阈值,异常得分不小于该阈值的样本,预测为异常样本,否则预测为背景样本。模型预测的混淆矩阵如表1所示。
表1 模型预测结果混淆矩阵
Table 1
| 真实/预测 | 异常样本 | 背景样本 |
|---|---|---|
| 已知矿点 | true positive(TP) | false negative(FN) |
| 非已知矿点 | false positive(FP) | true negative(TN) |
真阳性率(true positive rate, TPR)同时也被称为召回值(Recall),是衡量预测分类模型准确度的重要指标之一。在地球化学异常识别模型中TPR含义如下式所示:
为了进一步定量比较模型圈定异常区域的能力,定义一个性能评价指标PAbnormal,其计算公式如下:
由式(5)和式(6)可知,PAbnormal越小,TPR值越大,说明异常识别模型圈定的异常区域与已知矿点位置重合越精确,模型的性能评价越好。
利用AE、MCAE以及FCAE 3种无监督深度学习模型进行地球化学异常识别,重构区域多元地质背景信息,提取区域成矿特征的流程如图5所示。
图5
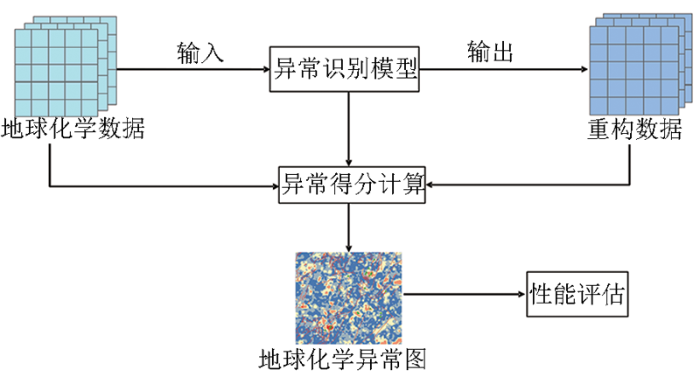
3 实验与评价
3.1 数据处理
本实验在研究区采集了1∶20万水系沉积物测量中3 484个采样点的数据,包括32种元素和6种氧化物。利用邻近样本的平均值填充缺失和极端异常处的样本数据。为了进一步降低噪声的影响,采用标准归一化将输入数据归一化到[01]区间。
研究区域内已知铜矿点有11个。为了通过地球化学异常识别圈定铜矿靶区,需要选择与铜成矿密切相关的元素和氧化物作为异常识别的指标。采用Benesty等[27]的方法计算Pearson相关系数,铜与其他地球化学变量之间的Pearson相关系数见表2[10]。根据相关系数检验表,当显著性水平为0.001时,若两个变量的相关系数大于0.104,说明两个变量显著相关[28]。因此选取Cu、Ag、Au、Zn、As、Cd、Sb、Ti、Pb、P、Na2O这11个地球化学变量作为铜成矿的异常识别指标,最终得到了11个地球化学变量维数为57×92、空间分辨率为1634.5 m×1492.8 m的样本浓度值矩阵,作为模型的输入数据。
表2 Cu与其他指标的Pearson相关系数[10]
Table 2
| 指标 | Ag | Au | Zn | As | Cd | Sb | Ti | Pb | P | Na2O |
|---|---|---|---|---|---|---|---|---|---|---|
| 相关系数 | 0.742 | 0.531 | 0.525 | 0.434 | 0.379 | 0.353 | 0.244 | 0.242 | 0.142 | 0.156 |
模型网络基于keras(2.5.0)和tensorflow-gpu(2.5.0)搭建,python版本为3.7.4。硬件环境采用Intel(R)Xeon(R)Gold 6142 CPU@2.60GHz,8核处理器,显卡为NVIDIA GeForce RTX 3080,采用29.77TFLOPS半精度和29.77TFLOPS单精度。
表3 AE和MCAE网络结构
Table 3
| 模型 | 编码器 | 解码器 |
|---|---|---|
| AE | 输入:以样本为单位输入,输入为11×5244(57×92)的样本浓度值矩阵 全连接层:250个神经元,激活函数relu 全连接层:180个神经元,激活函数relu 全连接层:80个神经元,激活函数relu | 全连接层:80个神经元,激活函数relu 全连接层:180个神经元,激活函数relu 全连接层:250个神经元,激活函数relu 输出:输出维度为11×5244(57×92)的重构矩阵,激活函数为softmax |
| 训练次数为10000次 | ||
| MCAE | 输入层:以元素为单位输入,维度为(57×92)5244×11的样本浓度值矩阵 卷积层:二维卷积,卷积核数为16,多尺寸卷积窗口,激活函数relu,填充方式same 池化层:二维池化,池化窗口3×2,填充方式same | 上采样层:二维上采样,池化窗口3×2 卷积层:二维卷积,卷积核数为16,多尺寸卷积窗口,激活函数relu,填充方式same 输出层:卷积窗口为1的卷积层,输出维度为11×5244(57×92)的重构矩阵,激活函数sigmoid |
| 训练次数为1500次 |
表4 FCAE网络结构
Table 4
| 模型 | 编码器 | 解码器 | ||
|---|---|---|---|---|
| AE-S编码器 | AE-C编码器 | AE-C解码器 | AE-S解码器 | |
| FCAE | 输入:以元素为单位输入,维度为(57×92)5244×11的样本浓度值矩阵 卷积层:二维卷积,卷积核数为16,多尺寸卷积窗口,激活函数relu,填充方式same 池化层:二维池化,池化窗口3×2,填充方式same | 输入:以元素为单位输入,维度为(57×92)5244×11的样本浓度值矩阵 卷积层:二维卷积,卷积核数为16,多尺寸卷积窗口,激活函数relu,填充方式same 池化层:二维池化,池化窗口3×2,填充方式same | 输入:AE-C编码器输出的拼接层 上采样层:二维上采样,池化窗口3×2 卷积层:二维卷积,卷积核数为16,多尺寸卷积窗口,激活函数relu 输出:卷积窗口为1的卷积层,输出维度为11×5244(57×92)的重构矩阵,激活函数是sigmoid,填充方式same | 输入:AE-S解码器输出的拼接层 上采样层:二维上采样,池化窗口3×2 卷积层:二维卷积,卷积核数为16,多尺寸卷积窗口,激活函数relu |
| AE-S的训练次数为1200次,AE-C的训练次数为1000次 | ||||
3.2 实验结果
3.2.1 性能对比
表5 三种模型性能对比
Table 5
| 模型 | PAbnormal | Recall | AUC |
|---|---|---|---|
| AE | 0.126 | 0.455 | 0.611 |
| MCAE | 0.499 | 0.909 | 0.780 |
| FCAE | 0.399 | 0.909 | 0.802 |
图6
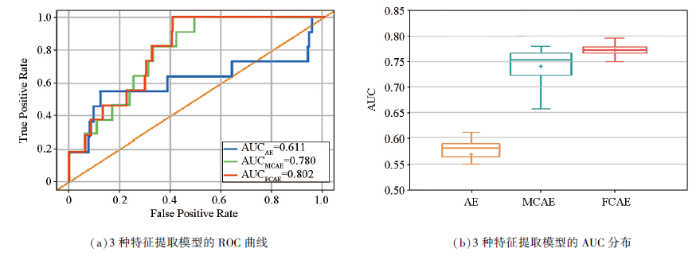
图6
三种特征提取模型的ROC曲线和AUC分布
Fig.6
ROC curves and AUC distributions of three feature extraction models
由图6可知,3种深度学习模型的平均AUC均大于0.5,因此3种模型都能有效完成对多元成矿特征的降维提取,重构符合区域成矿分布的地质背景信息。
AE通过提取样本中多元素间的组合结构特征进行异常识别,AE模型的平均AUC分布在[0.611],Recall不到0.5,在3种特征提取模型中综合性能最差,说明元素间的组合特征包含的成矿信息有限,基于样本多元素间的组合结构特征不足以有效重构区域地质背景,生成符合成矿分布的异常区域。
MCAE通过提取样本中多元素的空间分布特征进行异常识别,MCAE模型的平均AUC略高于AE模型,分布在[0.780],Recall达0.909,MCAE模型综合性能明显优于AE模型,说明基于空间分布特征重构的地质背景中包含区域有效成矿信息的比例显著提高。
FCAE通过提取融合了组合结构特征和空间分布特征的混合特征进行异常识别,FCAE模型的平均AUC最高,分布在[0.802],Recall与MCAE模型相同,但衡量模型圈定异常区域与已知矿点分布重合度的PAbnormal更小,因此FCAE模型圈定的靶区更精确,说明基于混合特征重构区域地质背景的过程中,保留的成矿分布信息最完整,重构的区域地质情况还原程度最高。
3.2.2 卷积核尺寸敏感度分析
提取多元素空间分布特征的MCAE模型,以及提取多元素混合特征的FCAE模型结构中都存在CNN,而卷积窗口的大小是影响CNN性能的关键参数,在实际应用中必须考虑模型对卷积窗口尺寸变化的敏感性。另外,由于提取多元素组合结构特征的AE模型中不存在CNN,因此AE模型对卷积窗口尺寸变化不敏感。
实际场景中,卷积窗口尺寸的变化可理解为对区域的观测空间尺度发生变化,因此探索卷积窗口尺寸变化对于模型性能的影响,能反映模型性能对观测空间尺度变化的敏感度,从侧面体现了模型对由观测空间尺度变化引起噪声的抗干扰能力。
图7
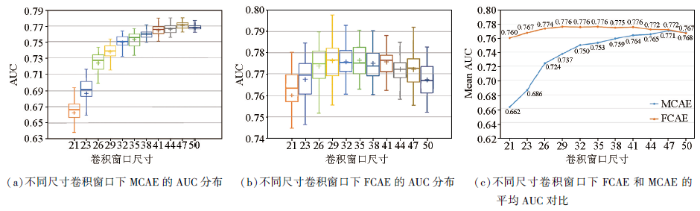
图7
不同尺寸卷积窗口的MCAE和FCAE性能对比
Fig.7
Performance comparison of MCAE and FCAE with different size convolution window
由图7a、b可知,随着卷积窗口尺寸增大,MCAE模型的AUC值波动明显,模型性能逐渐提高后趋于平稳。FCAE模型的AUC值波动较小,模型性能随卷积窗口尺寸变化不明显。
由图7c可知,当卷积窗口尺寸相同时,FCAE模型的平均AUC值略高于MCAE模型,且两模型的性能差距与卷积窗口尺寸大小成反比。FCAE模型在卷积窗口为35时取得最大AUC值0.802,MCAE模型在卷积窗口为47时取得最大AUC值0.780。
对比实验结果说明,MCAE模型对观测空间尺寸变化敏感,FCAE和AE模型对观测空间尺寸变化不敏感。因此在重构符合区域成矿分布的地质背景时,基于组合结构特征(AE模型)和混合特征(FCAE模型)的深度学习算法能有效降低观测空间尺度变化或不一致引起的噪声带来的影响,有利于采用类似网络结构的深度学习算法在实际矿产勘测场景的推广应用。
3.3 地球化学异常分布
基于ROC曲线得到最优阈值,将每种深度学习模型计算得到的异常得分转换为平面热力分布图,作为其地球化学异常识别的可视化结果,并在图中标明已知铜矿点和断层分布,如图8所示,图中异常得分越高的区域颜色越深。
图8
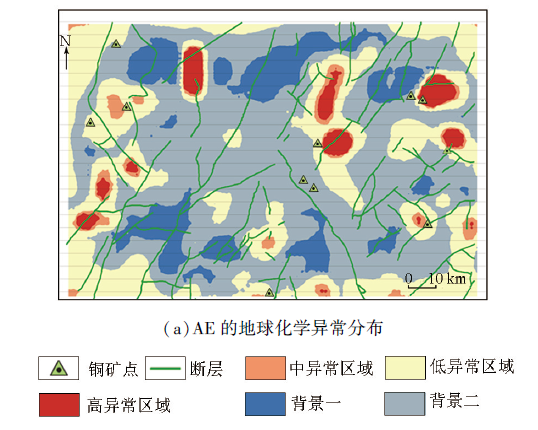
图8
-1 基于ROC曲线最佳阈值的地球化学异常分布
Fig.8
-1 Geochemical anomaly distribution map based on optimal threshold of ROC curve
图8
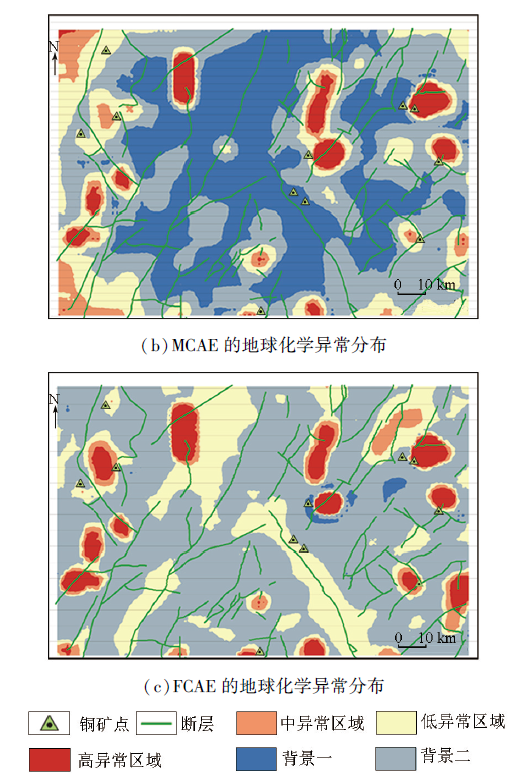
图8
-2 基于ROC曲线最佳阈值的地球化学异常分布
Fig.8
-2 Geochemical anomaly distribution map based on optimal threshold of ROC curve
研究区域内存在11个已知铜矿点。由图8可知,提取样本多元素组合结构特征的AE模型圈定的异常区域覆盖了7个已知铜矿点,提取样本多元素空间分布特征的MCAE模型覆盖了8个,提取样本多元素混合特征的FCAE模型覆盖了9个。
针对同一化探数据集,基于不同的无监督深度学习算法圈定的异常区域分布间存在明显差异,3种模型圈定的中高异常区域分布类似,但低异常和背景区域分布差异显著。其中MCAE和AE的异常分布相似度较高,但MCAE圈定的异常区域范围更小,更贴合已知铜矿分布;与AE和MCAE相比,FCAE模型圈定的中高值异常区域与已知铜矿点分布最贴合,且对中部沿断层分布的铜矿点有较好的预测效果。
3种无监督深度学习算法生成的地球化学异常图中存在若干偏离预测异常区域的已知矿点,分析其可能原因为:
1)在应用无监督异常识别算法前,选择合理的降维算法(如主成分分析法、层次聚类法等)提取与矿种成矿密切相关的地球化学变量作为异常识别指标,能显著改进成矿相关的地球化学异常识别结果[27]。当基于不合适的降维算法提取矿种异常识别指标时,输入数据中会损失大量区域成矿特征的关键信息,使预测模型无法准确还原区域成矿分布,造成已知矿点偏离模型预测区域。
2)矿产分布预测工作通常需要基于多类型探测数据,同时结合专业地质背景知识,以挖掘区域成矿规律,辅助指导矿产资源预测工作[6]。在通过异常识别模型预测矿产分布的过程中,仅基于单一类型的化探数据,而没有考虑其他探测手段的数据源(如遥感数据和地球物理数据等),不足以支撑异常识别模型提取成矿规律的有效信息以准确预测矿产分布,从而造成已知矿点偏离模型预测区域的情况。
4 讨论
深度学习算法的卷积神经网络需要限制输入数据为规则网格数据[29],但一些研究区域可能并不具备规则网格数据的采样条件,因此在实际推广中,模型结构中存在CNN的MCAE模型和FCAE模型可能会受到限制,而AE模型中不存在CNN,不受限于输入数据的规格,有机会适用于更广泛的应用场景。
本文研究区域内矿产数量较少且分散,识别的地球化学异常分布只占整个研究区域的一小部分。在已知矿点数量众多且分布占据大部分区域的地区,其地球化学异常模式与本文存在较大差异[30]。因此本文分析的深度学习算法是否适用于该类区域的地球化学异常识别问题,还需要进一步的探索与研究。
基于3种深度学习模型的优缺点及适用范围进行对比总结,如表6所示。针对不同无监督深度学习算法(AE、MCAE、FCAE)在同一研究区圈定的异常分布差异明显的问题,分析其可能原因如下:
表6 三种模型对比总结
Table 6
| 提取特征 | 模型 | 覆盖矿点数/ 总矿点数 | 优点 | 缺点 | 适用范围 |
|---|---|---|---|---|---|
| 元素组合结构特征 | AE | 7/11 | 能有效圈定靶区且对空间噪声不敏感 | 圈定靶区的准确率相对较低 | 矿产分布稀疏的地区 |
| 元素空间分布特征 | MCAE | 8/11 | 能相对精确地圈定靶区 | 需限制输入数据为规则网格数据,且对空间噪声较敏感 | 矿产分布稀疏且具有规则网格数据采样条件的地区 |
| 元素组合结构与空间分布混合特征 | FCAE | 9/11 | 能精确地圈定靶区,同时有效预测沿断层分布的铜矿点,且对空间噪声不敏感 | 需限制输入数据为规则网格数据 | 矿产分布稀疏且具有规则网格数据采样条件的地区 |
1)不同类型的成矿特征含有区域内成矿规律的有效比例不同,因此基于提取出的不同类型的成矿特征,还原区域成矿规律的有效程度存在差异,造成基于不同类型的成矿特征圈定的异常分布间存在明显差异。
2)不同的深度学习网络在结构设计上各有特点,在异常识别的过程中会不同程度地损失区域成矿特征中的有效信息,因此不同的深度学习网络对于区域成矿特征信息的还原程度不同,从而造成基于不同结构的深度学习网络圈定的异常分布间存在差异。
研究表明,融合地球化学变量的空间分布特征和组合关系对地球化学异常识别是有利的,在今后的地球化学异常识别研究中,应考虑更多的特征融合方法。另外,如何基于区域地球化学数据的特点,更好地构建融合特征的地球化学异常识别模型,辅助指导矿产勘探工作,也是值得深入研究的问题。
5 结语
本文利用闽西南铜锌银成矿区1∶20万水系沉积物数据,通过对比AE、MCAE、FCAE 3种无监督深度学习模型的地球化学异常识别结果,以及3种模型对卷积窗口尺寸变化的敏感度,分析总结了具有不同网络结构的深度学习模型在面向地球化学异常识别时的优缺点及适用范围。AE、MCAE、FCAE 3种模型分别基于提取样本元素的组合结构特征、空间分布特征以及融合前两种特征的混合特征,实现对复杂区域成矿特征的重构,以圈定地球化学异常靶区。本文根据区域具体成矿分布特点,选择合适的深度学习算法进行地球化学异常识别,以辅助矿产勘探提供了有效选择依据。
实验结果表明,AE、MCAE、FCAE 3种深度学习模型都能有效模拟区域矿产分布,其中基于提取样本元素混合特征(FCAE)和空间分布特征(MCAE)的模型,圈定的异常靶区与已知铜矿分布最贴合,同时基于提取样本元素混合特征(FCAE)和组合结构特征(AE)的模型对由观测空间尺度变化或不一致引起的噪声有较强抗干扰能力。采用适合网络结构的深度学习模型能有效提取地质环境中的复杂成矿信息,根据具体区域地质背景选择适合的深度学习算法圈定异常勘探靶区,能有效提高找矿效率。
本文研究区域内已知铜矿点数量较少且分布稀疏,计算规模相对较小,深度学习算法的性能有待进一步发掘,下一步工作可以针对已知矿点数量众多且分布密集地区,探索适合结构的深度学习算法以预测其矿产分布。
参考文献
On the first law of geography: A reply
[J].DOI:10.1111/j.1467-8306.2004.09402009.x URL [本文引用: 1]
Deep learning and its application in geochemical mapping
[J].
DOI:10.1016/j.earscirev.2019.02.023
[本文引用: 1]

Machine learning algorithms have been applied widely in the fields of natural science, social science and engineering. It can be expected that machine learning approaches especially deep learning algorithms will help geoscientists to discover mineral deposits through processing of various geoscience datasets. This study reviews the state-of-the-art application of deep learning algorithms for processing geochemical exploration data and mining the geochemical patterns. Deep learning algorithms can deal with complex and nonlinear problems and, therefore, can enhance the identification of geochemical anomalies and the recognition of hidden patterns. Applied geochemistry needs more applications of machine learning and/or deep learning algorithms.
Machine learning of mineralization-related geochemical anomalies: A review of potential methods
[J].DOI:10.1007/s11053-017-9345-4 URL [本文引用: 1]
卷积神经网络及其在矿床找矿预测中的应用——以安徽省兆吉口铅锌矿床为例
[J].
Application of convolutional neural network in prospecting prediction of ore deposits: Taking the Zhaojikou Pb-Zn ore deposit in Anhui Province as a case
[J].
基于深度学习的钨钼找矿靶区预测方法研究
[J].
DOI:10.12082/dqxxkx.2019.190032
[本文引用: 2]
随着矿产勘查工作由浅部矿向深部隐伏矿、由易识别矿向难识别矿发展,找矿难度日益增大,地质专家越来越重视新理论、新方法、新技术的应用。深度学习作为人工智能的前沿领域/技术,对于实现矿产资源预测“智能化预测评价”具有得天独厚的优势。本文以陕西省镇安县西部钨钼矿集区单元素化探异常原始数据为基础,提出了基于深度学习的钨钼矿产评价方法。该方法以归一化地球化学数据作为模型训练数据,通过深度学习中深度自编码网络方法实现异常值提取进而识别重点成矿有利地段,实现矿产资源找矿远景区定性预测。研究结果表明,在对957条单元素化探异常原始数据分类且做好模型标签后,整个过程在计算机的“黑盒子”中自动完成学习和预测,相较于传统预测研究方法,本文方法具有自动化程度高和客观性强的特征。此外,本文利用已知矿点构建训练数据集,采用随机森林方法对预测区进行矿产资源找矿靶区预测圈定,为进一步缩小找矿靶区范围提供科学依据。
Prediction method of tungsten-molybdenum prospecting target area based on deep learning
[J].
A spatially constrained multi-autoencoder approach for multivariate geochemical anomaly recognition
[J].DOI:10.1016/j.cageo.2019.01.016 URL [本文引用: 1]
A multi-convolutional autoencoder approach to multivariate geochemical anomaly recognition
[J].DOI:10.3390/min9050270 URL [本文引用: 3]
A spatial-compositional feature fusion convolutional autoencoder for multivariate geochemical anomaly recognition
[J].
成矿元素相态对地球化学异常识别的作用
[J].
The role of the phase state of metallogenic elements in the recognition of geochemical anomalies
[J].
地球化学异常识别的两种机器学习算法之比较
[J].
Comparison of two machine learning algorithms for geochemical anomaly detection
[J].
Learning representations by back propagating errors
[J].DOI:10.1038/323533a0 URL [本文引用: 1]
基于自动编码器组合的深度学习优化方法
[J].
DOI:10.11772/j.issn.1001-9081.2016.03.697
[本文引用: 1]
为了提高自动编码器算法的学习精度,更进一步降低分类任务的分类错误率,提出一种组合稀疏自动编码器(SAE)和边缘降噪自动编码器(mDAE)从而形成稀疏边缘降噪自动编码器(SmDAE)的方法,将稀疏自动编码器和边缘降噪自动编码器的限制条件加载到一个自动编码器(AE)之上,使得这个自动编码器同时具有稀疏自动编码器的稀疏性约束条件和边缘降噪自动编码器的边缘降噪约束条件,提高自动编码器算法的学习能力。实验表明,稀疏边缘降噪自动编码器在多个分类任务上的学习精度都高于稀疏自动编码器和边缘降噪自动编码器的分类效果;与卷积神经网络(CNN)的对比实验也表明融入了边缘降噪限制条件,而且更加鲁棒的SmDAE模型的分类精度比CNN还要好。
Deep learning algorithm optimization based on combination of auto-encoders
[J].
DOI:10.11772/j.issn.1001-9081.2016.03.697
[本文引用: 1]
In order to improve the learning accuracy of Auto-Encoder (AE) algorithm and further reduce the classification error rate, Sparse marginalized Denoising Auto-Encoder (SmDAE) was proposed combined with Sparse Auto-Encoder (SAE) and marginalized Denoising Auto-Encoder (mDAE). SmDAE is an auto-encoder which was added the constraint conditions of SAE and mDAE and has the characteristics of SAE and mDAE, so as to enhance the ability of deep learning. Experimental results show that SmDAE outperforms both SAE and mDAE in the given classification tasks; comparative experiments with Convolutional Neural Network (CNN) show that SmDAE with marginalized denoising and a more robust model outperforms convolutional neural network.
一种基于卷积自动编码器的推荐系统攻击检测方法
[J].
Recommendation system attack detection method based on convolutional autoencoder
[J].
基于栈式自动编码器的高分辨率遥感影像分类
[J].
High resolution remote sensing image classification based on stacked autoencoder
[J].
Page segmentation of historical document images with convolutional autoencoders
[C]//
基于卷积降噪自编码器的地震数据去噪
[J].
Seismic noise suppression based on convolutional denoising autoencoders
[J].
基于卷积自编码器的地震数据处理
[J].
Seismic data processing based on convolutional autoencoder
[J].
Variational autoencoder based anomaly detection using reconstruction probability
[J].
Recognition of geochemical anomalies using a deep autoencoder network
[J].DOI:10.1016/j.cageo.2015.10.006 URL [本文引用: 1]
Data space reduction, quality assessment and searching of seismograms: Autoencoder networks for waveform data
[J].DOI:10.1111/j.1365-246X.2012.05429.x URL [本文引用: 1]
An introduction to ROC analysis
[J].DOI:10.1016/j.patrec.2005.10.010 URL [本文引用: 1]
Pearson correlation coefficient [G]// Noise reduction in speech processing
Application of continuous restricted Boltzmann machine to identify multivariate geochemical anomaly
[J].DOI:10.1016/j.gexplo.2014.02.013 URL [本文引用: 1]
Graph neural networks: A review of methods and applications
[J].
利用样本排序方法比较化探异常识别模型的效果
[J].
Comparison of different models for anomaly recognition of geochemical data by using sample ranking method
[J].DOI:10.3799/dqkx.2009.038 URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}