

0 引言
CNN网络能够提取地震图像的局部特征,GRU网络能够提取地震数据的低频趋势,两者构成混合深度学习网络,可以完整地反演地震EI全频信息。CNN-GRU混合深度学习反演弹性阻抗(EI)取得了较好的反演效果[13]。CNN模型无法对所有数据集进行最佳泛化[14],混合深度学习模型也面临同样的问题,所以在对新的数据集进行混合深度学习方法时,必须选取合适的超参数。而混合深度学习中,超参数可以分为网络内部参数和网络外部参数,内部参数包含网络层数、每一层的激活函数、每个网络层卷积核尺寸、偏置项的尺寸,网络的不同链接方式、群组归一化尺寸、反卷积尺寸等,外部参数包括学习率、训练轮次(Epoch)、批尺寸(batch_size)、正则化参数及参与网络训练的测井个数等。这些参数即使对于小型的深度学习网络,总体参数个数也可能达到上千个,对于特定的数据集,我们可以采用穷举的方式,获得一套能够充分发挥深度学习网络性能的超参数,但这样无疑会耗费大量人工和机器运行时间。从文献调研结果来看,国外学者对学习率这个超参数进行了研究,并利用线性循环迭代可变学习率在图像处理领域取得了较好的应用效果[15]。Breuel探讨了MNIST手写数字识别问题中超参数对CNN神经网络训练的影响,主要研究了批尺寸、学习率与训练误差、测试误差的关系[16]。在混合深度学习地震反演领域,不同类型的超参数对网络性能及计算速度影响尚缺乏系统性研究,直接影响了反演精度和推广应用。
因此,本文在混合深度学习反演弹性阻抗基础上[13],重点探讨 Epoch、batch_size、正则化参数、参与网络训练的测井个数、学习率等5个超参数对网络性能及计算速度的影响,为深度学习地震反演超参数选取提供依据。
1 数据集及深度学习网络框架
为了研究超参数对反演结果的影响,选取Marmousi 2模型[17]作为深度学习的数据集。Marmousi 2模型是Marmousi合成模型的弹性扩展,整个模型宽度为17 km,深度为3.5 km,垂直分辨率为1.25 m。根据研究需要,我们选取了整个二维地震剖面的中间部分,共计2 720道,其时间域地震剖面如图1所示。对选取的地震道集重新进行数据集划分,即把数据集重新划分为训练集、测试集和验证集,这样划分的好处是可以验证混合深度学习网络的泛化性能。GRU-CNN混合深度学习采用Motaz在2019年提出的网络框架[13]。由于该网络总体参数达到上千个,难以对其全部进行研究,因此本文在内部网络参数保持不变情况下,重点研究5个外部超参数。
图1
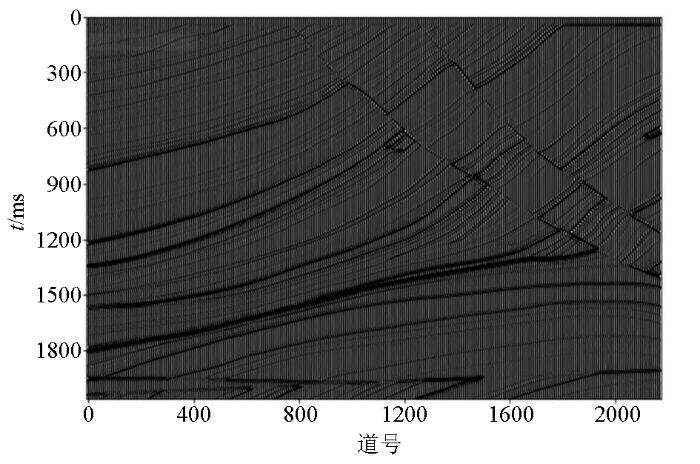
图1
Marmorsi2模型时间域地震剖面(局部)
Fig.1
Time domain seismic profile of marmorsi2 model(local)
2 不同网络模型反演效果及效率对比
图2a对比了混合深度学习与卷积深度学习两种弹性阻抗反演方法,反演时长为2 070 ms,从生产上看,长时窗地震反演会增加反演的难度。整体上看,混合深度学习反演结果与测井弹性阻抗拟合较好,低频趋势合理,局部地层反演达到预设要求,探究其原因,主要是混合深度学习反演方法在算法中有机结合了卷积神经网络(CNN)及门控循环单元(GRU)两种深度学习方法,而卷积神经网络能够对小套地层进行特征提取,门控循环单元(GRU)深度学习则可以对地震长时间序列进行低频信息的提取。从图2a中可以看出,在0~400ms和1 800~2 100 ms两个时窗范围内,绿线较大程度地偏离了测井弹性阻抗结果,说明反演误差较大,主要原因是卷积深度学习对低频信息提取能力较差。图2b对比了两种反演方法计算时间,CNN用时197.64 ms,CNN+GRU混合反演用时263.8 ms,混合反演用时略高,其原因是在混合深度学习反演中,当地震数据流向CNN网络时,同时地震数据也流向了GRU网络,而每一部分的数据流均会耗费GPU计算时间。这造成两种反演方法的耗时差异。图2c对比了两种反演方法的相关系数,统计时窗是图2a中的整条曲线时窗,统计方法采用R2相关方法,这种相关方法的优点是考虑了两条曲线的均方误差。卷积深度学习的相关系数代表图2a中卷积深度学习反演结果(绿线)与测井弹性阻抗(红线)的相关系数,混合深度学习的相关系数代表图2a中黑线与红线的相关系数,图2c表明,混合深度学习的相关系数明显高于卷积深度学习反演方法。
图2
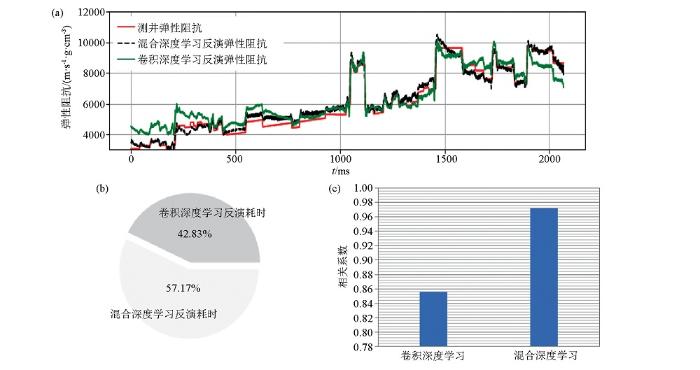
图2
卷积深度学习与混合深度学习反演效率效果对比
a—反演结果对比;b—耗时对比;c—相关系数对比
Fig.2
Comparison of inversion efficiency and result between convolution deep learning and hybrid deep learning
a—inversion results comparison;b—time consmption comparison;c—correlation coefficient comparison
3 超参数对反演影响
3.1 batch-size对反演影响
图3为不同batch-size对相关系数及计算时间的影响。图3a为batch_size测试图,纵轴表示整个地震剖面上反演的EI道与实测EI的总相关系数,从图中可以看出,整体上相关系数在0.96 ~0.98之间,随着batch_size逐渐变大而呈现出非规律性的相关系数变化,这也说明如果想取得最佳的反演效果,需要进行多次的batch_size参数测试。 图3b为不同batch_size情况下反演耗时分布,为保证具有可对比性,每次batch_size测试,反演均包含模型训练与模型测试两部分,深度学习程序在GPU上运算,除了batch_size参数不同,其余实验参数均相同,除了batch_size=50时运行时间有突变,随着batch_size的增加,实验耗时逐渐递增。因此结合图3,综合时间成本及相关系数,选取batch_size参数为33次为适宜参数。
图3
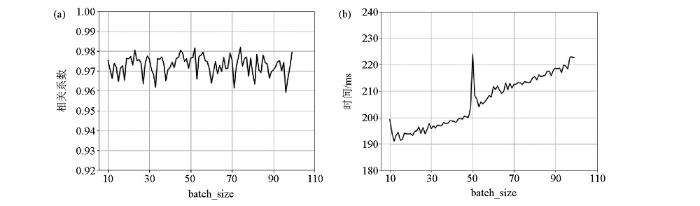
图3
Batch-size对相关系数(a)及计算时间(b)的影响
Fig.3
Batch-size effect on correlation coefficient(a) and calculation time(b)
3.2 测井个数(标签数量)对反演影响
图4
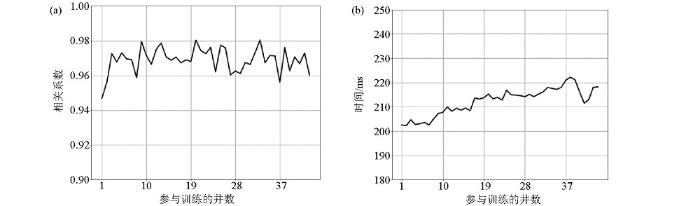
图4
参与训练的井数对相关系数(a)、计算时间(b)的影响
Fig.4
Influence of number of wells participating in the training on correlation coefficient(a) and calculation time(b)
在相同超参数情况下,将深度学习网络分别运行在CPU和GPU上,其CPU型号是intel i7-8550U,主频是1.8 GHz,GPU显卡型号是NVIDIA GeForce GTX1050独立显卡,参与反演的地震道是2 720道,深度学习网络在CPU运行时间是6 746 ms,在GPU上运行时间是381 ms,CPU耗时将近是GPU耗时的18倍。其饼状图如图5所示。可见,对于深度学习反演算法,利用GPU运算更加具有实用性。
图5
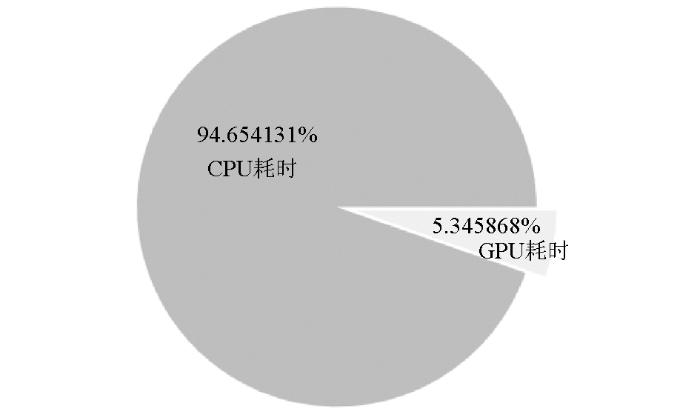
图5
相同超参数情况下GPU运算与CPU运算耗时比较
Fig.5
Comparison of operation time between GPU and CPU with the same hyper-parameters
3.3 训练轮次对反演影响
在深度学习中,由于数据集一般都很庞大,而每个数据单元都可能需要计算梯度,在这种情况下,一次性将全部数据加入计算机内存是不可能的,笔者尝试开辟虚拟内存空间,依然会存在内存爆满(内存利用率100%)的情况,影响深度学习效率。图6a表示不同Epoch数量与相关系数关系,纵轴表示整个地震剖面上反演的EI道与实测EI的总相关系数;图6b表示反演耗时与Epoch数量选择的变化关系。可以看出,Epoch数量增加导致计算耗时近似线性增加。当Epoch<70时,相关系数变化剧烈,对照图6b,此时虽然计算耗时较少,但可以认为反演结果不稳定;当Epoch数量为280~700时,相关系数趋于稳定;随着Epoch数量增加,耗时呈现近似线性增加;综上,可以优选Epoch=280作为较好的超参数选择。
图6
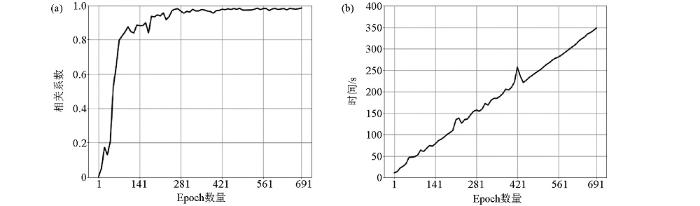
图6
轮次(Epoch)与相关系数(a)、计算耗时(b)的关系
Fig.6
Relation diagram of Epoch vs the correlation coefficient(a) and time consumption(b)
3.4 正则化参数对反演的影响
图7是α参数与相关系数、计算耗时关系图,反映了两个正则化参数α、β之间的比例关系,其中,α代表了弹性阻抗EI在整个损失函数中所占的权重,β代表了地震在整个损失函数中所占的权重。α,β两个正则化参数的内涵是,相当于在地震反演中更加认同地震数据还是更加相信测井数据。为了完备讨论这个问题,一般α、β都需要给定各自的范围,之后两两组合,再进行反演试算。本文为了达到上述效果,简化了表征方式,即取α∈[0.1,2.0],步长为0.1,同时针对每一个α取值,β取值均为1,相当于α∶β∈[0.1,2.0],步长为0.1,特别说明,这里面也包含了α∶β=1∶1情况,即地震与测井所占权重相等(两者同等重要)。从图7a可以看出当α∶β≤0.5∶1,相关系数变化剧烈,最小相关系数仅为0.75;当α∶β≥0.6∶1时,相关系数大于 0.95。图7a整条曲线表明,地震非监督与测井监督部分的比例关系对于最终的反演结果是有影响的,这说明,深度学习虽然可以通过网络的正向传播及反向梯度自动求导,从而寻求得到最佳的网络参数,但是,超参数的选取依然是值得关注的问题,尤其对于实际的生产项目,应该有必要做好这部分的测试工作,从而全面发挥深度学习网络的超强性能。从图7b可以看出,当α∈[0.1,2.0],整个耗时在200 s和205 s之间,当α∶β=1.2∶1时耗时出现突变。这说明,对于三维大工区,要结合图7的相关系数及时间消耗图综合选取正则化参数。
图7
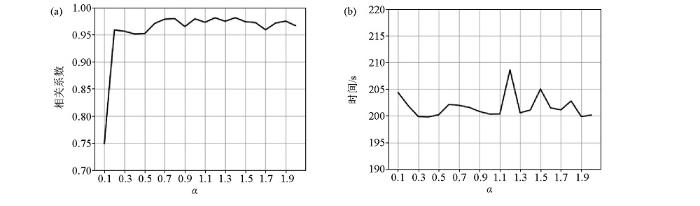
图7
正则化参数α与相关系数(a)、计算耗时(b)关系
Fig.7
Relation diagram of regularization parameter α vs correlation coefficient(a) and time consumption(b)
3.5 学习率对反演的影响
在最原始的梯度更新算法[13]中:
式中:ωt为当前权值参数;
图8
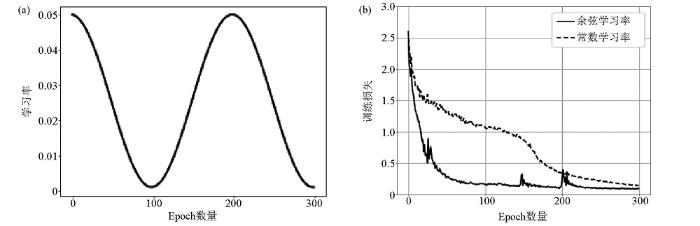
图8
学习率曲线及改进方法
a—余弦学习率曲线;b—常数学习率与余弦学习率损失曲线对比
Fig.8
Learning rate curve and improvement method
a—cosinc learning rate curve;b—loss curve comparison between constant learning rate and cosinc learning rate
4 结论
1)对于深度学习反演,超参数选取是值得探讨的内容。在生产项目中一般依靠经验进行参数选择,难以对反演精度进行准确量化。本文的模拟结果表明,选取不同的超参数,虽然深度学习算法都能使深度学习网络收敛,但最终的反演结果及反演耗时是有优劣之分的。
2)本文为深度学习反演提供了一个可行的超参数选取思路,即通过挑选典型的二维测线,利用深度学习算法在GPU上的快速运算技术,快速提取正则化参数α、Epoch、batch_size、参与网络训练的井数等参数与相关系数、时间关系图,从而为深度学习超参数选取提供科学依据。
3)关于超参数的完全自动化选取及深度学习的自我进化机制研究是未来进一步研究方向。
致谢:
感谢审稿专家和编辑老师对本文提出的宝贵意见和建议,感谢成都理工大学陈学华教授对论文初稿提出的宝贵意见。
参考文献
基于卷积神经网络识别重力异常体
[J].
The identification of gravity anomaly body based on the convolutional neural network
[J].
Image net large scale visual recognition challenge
[J].DOI:10.1007/s11263-015-0816-y URL [本文引用: 1]
优化卷积神经网络在道编辑中的应用
[J].
Application of optimized convolutional neural network in Dao editing
[J].
基于深度学习卷积神经网络的地震数据随机噪声去除
[J].
Deep learning convolutional neural networks for random noise attenuation in seismic data
[J].
基于深度学习的地震岩相反演方法
[J].
Seismic rock inversion method based on deep learning
[J].
无监督与监督学习下的含油气储层预测
[J].
Prediction of petroleum reservoirs under unsupervised and supervised learning
[J].
Fault net 3D:Predicting fault probabilities,strikes,and dips with a single convolutional neural network
[J].DOI:10.1109/TGRS.36 URL [本文引用: 1]
SEG technical program expanded abstracts 2018
[M].
基于LSTM循环神经网络的储层物性参数预测方法研究
[J].
Research on prediction method of reservoir physical property parameters based on LSTM recurrent neural network
[J].
基于循环神经网络的测井曲线生成方法
[J].
Logging curve generation method based on cyclic neural network
[J].
一种基于LSTM的合成语音自然度评价方法的研究
[J].
Research on an evaluation method of naturalness of synthesized speech based on LSTM
[J].
基于SARIMA-LSTM的门诊量预测研究
[J].
Research on outpatient forecast based on SARIMA-LSTM
[J].
AlRegib G.Semisupervised sequence modeling for elastic impedance inversion
[J].
基于改进贝叶斯优化算法的CNN超参数优化方法
[J].
Hyper-parameter optimization of CNN based on improved Bayesian optimization algorithm
[J].
Cyclical learning rates for training neural networks
[C]//
The effects of hyperparameters on SGD training of neural networks
[EB/OL].
Marmousi2:An elastic upgrade for marmousi
[J].DOI:10.1190/1.2172306 URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}