

0 引言
地层岩石岩性是储层表征和资源评价的关键因素,它的准确识别是油气成藏评价工作的基础。除岩石手标本观察之外,测井数据分析是岩石岩性识别的又一途径。传统基于测井数据的岩石岩性识别方法主要有:交会图法[1]、概率统计法[2]和聚类分析类法[3-4]。尽管如此,面对复杂地下地质环境,建立测井数据与地层之间高纬度的映射关系,找出海量测井数据之间潜在的非线性关系仍是测井亟待解决的关键问题。近年来,随着人工智能的快速发展,以机器学习为代表的先进算法为解决这一传统问题提供新的可能,例如使用长短期记忆神经网络(LSTM)补全测井缺失曲线[5]、基于决策树方法的砾岩油藏岩石岩性识别[6]。与传统岩石岩性识别方法相比,机器学习在数据处理方面更具优势,面对复杂问题时可以增强分类性能的信息融合来获得精确的决策。目前常用于测井岩性识别的机器学习方法包括:决策树、随机森林、XGBoost、多层感知等。
决策树的主要优势在于其直观可解释性以及对不同数据类型的适用性,且无需开展复杂数据预处理。随机森林作为一种强大的集成学习方法,具备处理高维数据的优秀能力。该方法通过整合多个决策树,有效地降低了过拟合的风险[7]。相较之下,XGBoost采用正则化技术,成功地抑制了过拟合的发生。在训练和预测的过程中,XGBoost表现卓越,特别在面对大规模数据集时更为出色。另外,XGBoost还具备自动处理缺失值的功能,无需进行额外的数据处理。相较之下,多层感知机(MLP)则展现出学习复杂非线性关系的出色能力,尤其适用于解决复杂问题和处理多变的数据。通过多层感知机的隐藏层,MLP能够有效地捕捉输入数据的抽象表示,从而有助于发现其中的有用特征。它们分别在处理数据和解决问题时具有不同的优势,决策树操作简单直观,随机森林强调模型的稳定性,XGBoost注重性能,而MLP适用于复杂非线性问题。本文利用上述4种模型对挪威海测井数据开展岩性识别,对比分析它们在岩石岩性识别方面的优劣,为岩石岩性识别方法的选择提供有益参考。
1 基本原理
1.1 分类方法的基本原理
1.1.1 决策树
决策树(decision tree,DT)是由Quinlan[8]于1986年提出的一种模型,由节点(nodes)和边(edges)构成。在该结构中,树的顶部节点为根节点,根节点连接一系列内部节点,内部节点连接叶子节点,信息以递归方式自顶向下传递。决策树在决策时根据数据特征值逐步沿树进行分支,使用信息增益、Gini系数等指标进行评判,直至到达叶子结点,其类别即为预测的类别。为了防止过拟合,决策树在剪枝阶段会减去不必要的节点和分支,以提高泛化能力。
决策树的优势在于对于一些特定的数据集表现出色,且能够处理混合数据类型。然而,在应对复杂问题时,决策树可能变得过于复杂,容易发生过拟合现象。此外,决策树对数据中的噪声和异常值较为敏感,微小的数据变化可能导致树的结构发生显著改变。
1.1.2 随机森林
随机森林(random forest)是一种集成学习算法。通过构建多个决策树组成森林,每棵树生成预测结果,最终通过投票决定整体结果。算法步骤如下:①随机选择样本(有放回),使每棵树的训练集可能不同;②每次节点分裂时仅考虑部分特征,而非全部特征,以减少特定特征对模型的影响;③按照以上步骤构建单颗决策树;④集成多个决策树,每棵树都是独立构建的,最终结果由多颗树投票决定。随机森林引入随机性的思想旨在降低过拟合风险,以提高模型的泛化能力。在面对高纬度数据分类问题时,随机森林表现良好,Bagging算法[9]弥补了单个决策树对噪声敏感的问题,有效降低了过拟合可能带来的负面效应。
1.1.3 多层感知机
图1
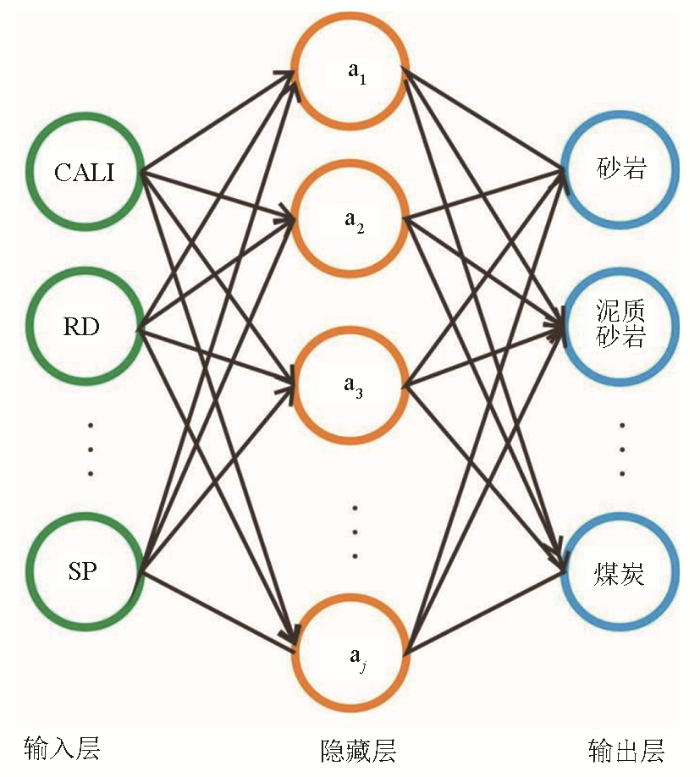
MLP的每一个神经元都与之前的每个神经元有相关联的权重,这些权重控制信息传递到下一层。此外,每个神经元还携带一个偏差。MLP激活函数负责决定神经元输出的非线性关系,这使得MLP能够学习并适应非线性函数。
1.1.4 XGBoost
XGBoost是由GBM(gradient boosting machine)梯度提升机器方法发展而来。它同随机森林算法一样,也是一个集成算法;但不同的是,GBM每个决策树都尝试纠正前一个树的错误以达到提升模型性能的目的。GBM模型也容易出现过拟合,对异常值敏感,调整参数复杂等问题。在天池大赛中,Chen等[11]通过改进GBM提出XGBoost算法,不仅在性能上相较于GBM有显著提升,而且对于GBDT(gradient boosting decision trees)模型也有明显改善。引入并行计算数据特征进一步提高了XGBoost模型计算效率。
XGBoost的模型表达式为[12]:
式中:
正则项为:
式中:T为叶子结点数量;
XGBoost的目标函数包括损失函数和正则项,损失函数为
进行t次迭代后,为了使目标函数最小,对式(3)进行泰勒展开[13]:
式中:
2 建模与应用
2.1 数据来源与处理方法
本文所使用的数据源自2020年FORCE机器学习竞赛提供的岩石岩性以及相应的测井、地震数据集 [14]。该数据集由来自挪威海的118口钻井数据组成,而本文选取其中5口钻井数据。这些钻井数据涵盖了多种岩石类型,包括砂岩、泥质砂岩、页岩、泥岩、白云岩、石灰岩、白垩岩、盐岩、凝灰岩、煤炭(表1)[15-16]。本研究使用的5口钻井的测井数据包含共计52 211组数据样本。为构建模型借助Python第三方包pytorch作为平台,建立了决策树、随机森林、多层感知机(MLP)、XGBoost等模型。通过使用Sklearn库中的train_test_split语句,按照7∶3比例将数据划分为训练集和测试集。为保证研究的科学性,必须对训练集数据和测试集数据进行严格的区分。在机器学习模型的准确率评估中,测试数据集扮演着至关重要的判别角色,通常不建议在初期工作中对其进行分析。
表1 不同岩性的测井数据
Table 1
| 岩性 | 统计量 | CALI/ (ft·s-1) | RD/ (Ω·m) | RHOB/ (g·cm-3) | GR/ (API) | CN/% | PEF/ (mV) | DTC/ (m·s-1) | SP/ (mV) | 样本总数 |
|---|---|---|---|---|---|---|---|---|---|---|
砂岩 | 平均值 | 11.51 | 1.86 | 2.20 | 37.96 | 0.30 | 5.29 | 101.91 | 71.49 | 5837 |
| 最小值 | 7.45 | 0.12 | 1.49 | 10.61 | 0.06 | 1.12 | 57.04 | 15.39 | ||
| 最大值 | 23.70 | 87.51 | 2.84 | 94.13 | 0.76 | 34.19 | 158.18 | 132.99 | ||
泥质 | 平均值 | 9.62 | 1.35 | 2.32 | 58.98 | 0.28 | 4.71 | 94.34 | 92.82 | 3338 |
砂岩 | 最小值 | 7.45 | 0.31 | 1.56 | 25.40 | 0.08 | 1.16 | 62.60 | 24.44 | |
| 最大值 | 22.28 | 11.72 | 2.77 | 146.75 | 0.73 | 27.35 | 171.05 | 135.48 | ||
页岩 | 平均值 | 13.26 | 1.08 | 2.10 | 75.38 | 0.44 | 4.10 | 132.66 | 69.11 | 32491 |
| 最小值 | 5.94 | 0.33 | 1.43 | 24.85 | -0.05 | 1.32 | 7.41 | 28.90 | ||
| 最大值 | 25.71 | 84.12 | 2.95 | 804.29 | 0.80 | 39.77 | 230.43 | 137.08 | ||
泥岩 | 平均值 | 10.20 | 3.16 | 2.46 | 34.51 | 0.19 | 4.10 | 80.03 | 99.51 | 1512 |
| 最小值 | 7.32 | 0.70 | 1.62 | 8.05 | 0.07 | 1.32 | 60.18 | 22.89 | ||
| 最大值 | 16.80 | 13.33 | 2.64 | 81.83 | 0.46 | 39.77 | 110.39 | 122.81 | ||
白云岩 | 平均值 | 9.53 | 5.06 | 2.45 | 42.59 | 0.15 | 4.18 | 71.61 | 102.21 | 98 |
| 最小值 | 8.47 | 0.90 | 1.52 | 21.10 | 0.06 | 2.81 | 54.73 | 38.61 | ||
| 最大值 | 15.07 | 13.13 | 2.90 | 82.36 | 0.40 | 7.67 | 117.03 | 121.94 | ||
石灰岩 | 平均值 | 11.52 | 3.65 | 2.45 | 22.24 | 0.18 | 5.56 | 76.26 | 85.46 | 6222 |
| 最小值 | 7.48 | 0.39 | 1.52 | 5.59 | 0.001 | 1.97 | 40.76 | 17.69 | ||
| 最大值 | 23.71 | 66.42 | 2.90 | 126.06 | 0.62 | 166.99 | 167.77 | 120.68 | ||
白垩岩 | 平均值 | 11.70 | 4.12 | 2.53 | 16.03 | 0.12 | 8.20 | 66.47 | 104.60 | 1924 |
| 最小值 | 7.75 | 1.15 | 1.51 | 5.78 | 0.03 | 3.56 | 54.26 | 83.06 | ||
| 最大值 | 14.22 | 14.04 | 2.63 | 33.26 | 0.33 | 86.82 | 81.83 | 116.41 | ||
盐岩 | 平均值 | 11.13 | 13.45 | 1.91 | 49.80 | 0.16 | 15.95 | 60.81 | 127.01 | 20 |
| 最小值 | 8.67 | 2.61 | 1.60 | 15.79 | 0.008 | 11.99 | 51.28 | 121.07 | ||
| 最大值 | 12.66 | 41.02 | 2.28 | 78.28 | 0.6 | 21.35 | 73.23 | 130.41 | ||
凝灰岩 | 平均值 | 14.01 | 0.81 | 2.19 | 45.77 | 0.41 | 4.12 | 118.26 | 62.12 | 719 |
| 最小值 | 12.23 | 0.38 | 1.57 | 21.31 | 0.29 | 2.73 | 61.40 | 36.35 | ||
| 最大值 | 23.31 | 1.41 | 2.36 | 78.12 | 0.65 | 9.67 | 149.06 | 97.41 | ||
煤炭 | 平均值 | 8.56 | 11.22 | 1.81 | 46.55 | 0.48 | 2.64 | 114.47 | 120.64 | 49 |
| 最小值 | 8.18 | 2.32 | 1.42 | 26.14 | 0.26 | 1.29 | 77.18 | 113.24 | ||
| 最大值 | 9.38 | 27.73 | 2.58 | 67.76 | 0.60 | 7.01 | 127.48 | 128.37 |
钻井的测井曲线包括补偿声波测井(CALI)、电阻率(RD)、密度(RHOB)、自然伽马(GR)、中子孔隙度(CN)、光电吸收截面指数(PEF)、压缩波速度(DTC)、自然电位(SP)。因为原始数据掺杂了许多干扰异常值,而在机器学习训练过程中数据对模型预测的精准度有很大响应,因此需要对原始数据进行预处理:
1)异常值处理[17]。若原始测井数据的首尾两端数据存在异常数值,可根据经验直接删除;同时可将数据进行标准化或者归一化变换,使异常数值对模型的影响减小,同时保留正常数据的分布特性。
2)填补缺失值。对于测井数据内部的异常数值,通常采用插值进行补充;如果选择直接删除异常数据,可能会影响模型对数据的敏感度而降低预计准确度。
2.2 评价指标
图2
混淆矩阵是在每一个单元格(i, j)真实的值和预测值的表示,例如,在二分类中有真阳性(true positive,TP)、假阳性(false positive,FP)、假阴性(false negative,FN)、真阴性(true negative,TN),用于描述分类或方法的性能,主对角线上的观测值数量的增加被视为性能的优势,而非主对角线上的数值则越少越有利[20]。精确度(Precision)是指模型在正类别样本中正确识别为正类别的能力。召回率(Recall)衡量了模型正确识别正类别的比例。F1分数是精确度和召回率之间的平衡度量,用于综合评估模型的性能,分数越高表示模型性能越好[21]。精确度、召回率、F1分数的计算公式如式(6)所示,精确度由真阳性除以真阳性与假阳性之和。召回率是由真阳性除以真阳性与假阴性之和。F1分数是由两倍的精确度乘以召回率除以精确度与召回率之和。
,
。
支持度是指各个类别测试样本的数量;准确度是模型对所有类别分类预测的准确性;宏平均表示每个类别权重相等;加权平均是指计算所有类别性能平均值,根据每个类别的支持度加权计算,便于考虑不平衡类别分布。
2.3 模型训练结果比较
经过模型训练和参数调试后得出最优的结果,从图3中可以得出决策树对各个岩性的分布情况,页岩9 695个样本成功识别样本个数为9 296,召回率约为96% ;白垩岩608个样本成功识别样本个数为536,召回率约为88%;石灰岩1 915个样本成功识别样本个数为1 667,召回率约为87%;砂岩1 702个样本成功识别样本个数为1 426,召回率约为84%;泥岩452个样本成功识别样本个数为348,召回率约为77%;凝灰岩220个样本成功识别样本个数为154,召回率约为70%;泥质砂岩1 022个样本成功识别样本个数为701,召回率约为69%;白云岩30个样本成功识别样本个数为19,召回率约为63%;煤炭13个样本成功识别样本个数为8,召回率约为62%;盐岩6个样本成功识别样本个数为3,召回率约为50%。从高到低排序为:页岩96%、白垩岩88%、石灰岩87%、砂岩84%、泥岩77%、凝灰岩70%、泥质砂岩69%、白云岩63%、煤炭62%、盐岩50%。相对而言,随机森林对10种岩性的召回率从高到低为页岩99%、白垩岩93%、砂岩92%、泥岩88%、石灰岩87%、泥质砂岩79%、盐岩75%、凝灰岩、煤炭69%、白云岩53%。从数据上,两个模型对白云岩和页岩有两极化的响应,对白云岩两个模型都表现不佳,与之对应的页岩决策树和随机森林模型表现良好。主对角线上的10种岩性表示正确的预测结果,而非对角线上的岩性则代表错误的预测,从预测效果方面随机森林模型优于决策树模型(图3、图4)。
图3
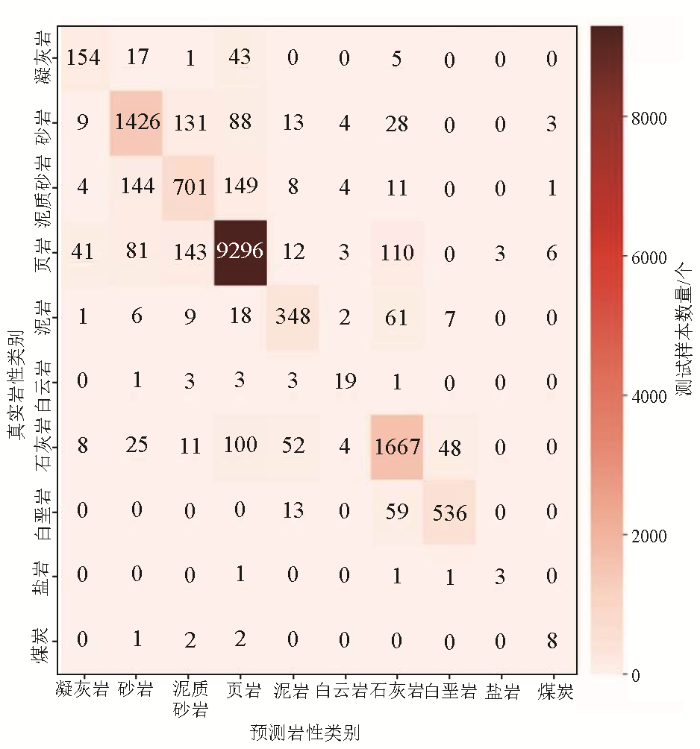
图3
决策树模型分析岩性混淆矩阵
Fig.3
Decision tree modeling analysis of lithology confusion matrix
图4
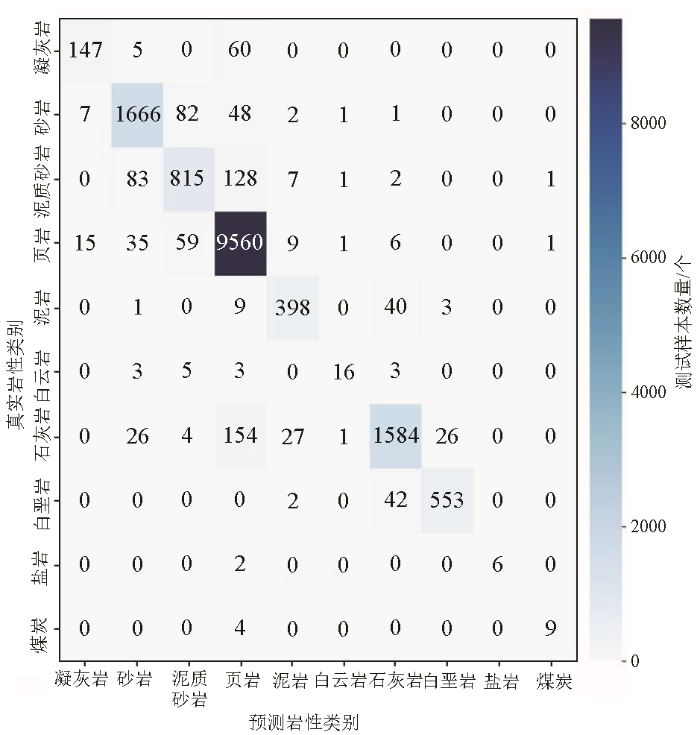
图4
随机森林模型分析岩性混淆矩阵
Fig.4
Random forest modeling analysis of lithological confusion matrix
通过对决策树和随机森林模型的预测结果进行分析(表2),发现随机森林模型对石灰岩和白垩岩两种岩性的预测F1值分别为94%和95%,比决策树模型高出约5%。在凝灰岩和白云岩两种岩性的精确度方面,决策树表现较低,分别为71%和53%,而随机森林分别为87%和80%。然而,决策树模型在凝灰岩和白云岩的召回率分别为70%和63%,而随机森林为69%和53%,导致两种模型的F1值相差7%和6%。对于砂岩岩性的预测,两种模型的F1值相差8%,而在泥岩和泥质砂岩预测中,F1值的差异达到12%。决策树对煤炭的岩性预测精确度、召回率和F1值均低于随机森林模型,尤其是F1值相差23%。与随机森林相比,决策树对盐岩岩性的预测精确度、召回率和F1值与其分别相差50%、25%和36%。随机森林整体识别准确度达到94%,而决策树模型的准确度仅为90%。这表明在岩性分类任务中,随机森林模型相对于决策树表现更出色。
表2 决策树和随机森林模型分类报告
Table 2
| 岩性 | 决策树模型 | 随机森林模型 | ||||||
|---|---|---|---|---|---|---|---|---|
| 精确度 ×100/% | 召回率 ×100/% | F1值 ×100/% | 支持度 | 精确度 ×100/% | 召回率 ×100/% | F1值 ×100/% | 支持度 | |
| 凝灰岩 | 0.71 | 0.70 | 0.70 | 220 | 0.87 | 0.69 | 0.77 | 212 |
| 砂岩 | 0.84 | 0.84 | 0.84 | 1702 | 0.92 | 0.92 | 0.92 | 1807 |
| 泥质砂岩 | 0.70 | 0.69 | 0.69 | 1022 | 0.84 | 0.79 | 0.81 | 1037 |
| 页岩 | 0.96 | 0.96 | 0.96 | 9695 | 0.96 | 0.99 | 0.97 | 9588 |
| 泥岩 | 0.78 | 0.77 | 0.77 | 452 | 0.89 | 0.88 | 0.89 | 451 |
| 白云岩 | 0.53 | 0.63 | 0.58 | 30 | 0.80 | 0.53 | 0.64 | 30 |
| 石灰岩 | 0.86 | 0.87 | 0.86 | 1915 | 0.94 | 0.87 | 0.91 | 1822 |
| 白垩岩 | 0.91 | 0.88 | 0.89 | 608 | 0.95 | 0.93 | 0.94 | 597 |
| 岩盐 | 0.50 | 0.50 | 0.50 | 6 | 1.00 | 0.75 | 0.86 | 8 |
| 煤炭 | 0.44 | 0.62 | 0.52 | 13 | 0.82 | 0.69 | 0.75 | 13 |
| 准确率 | 0.90 | 15663 | 0.94 | 15663 | ||||
| 宏平均 | 0.72 | 0.75 | 0.73 | 15663 | 0.90 | 0.80 | 0.85 | 15663 |
| 加权平均 | 0.90 | 0.90 | 0.90 | 15663 | 0.94 | 0.94 | 0.94 | 15663 |
经过对XGBoost和MLP模型进行交叉验证后,两种模型对测试样本的岩石岩性分类结果见图5和图6。鉴于XGBoost模型和MLP模型需要为测试样本的岩石岩性种类(标签)赋予数字符号,因此,我们将其表示为:0(凝灰岩),1(砂岩),2(泥质砂岩),3(页岩),4(泥岩),5(白云岩),6(石灰岩),7(白垩岩),8(盐岩),9(煤炭)。综合表3的数据,对于岩石岩性分类任务,我们对XGBoost模型和MLP模型的性能进行了全面的比较和分析。在凝灰岩和白垩岩两种岩性的预测中,XGBoost模型展现出显著优越性,其精确度分别达到91%和95%,远高于MLP模型的76%和86%。页岩岩性方面,两者的性能相近,XGBoost模型的精确度、召回率和F1值分别为97%、99%和98%,略高于MLP模型的精确度、召回率和F1值(96%、97%和96%)。对于石灰岩,虽然精确度上两者相差3%,但XGBoost模型在召回率和F1值上分别为90%和91%,明显优于MLP模型的82%和86%。在煤炭岩性的表现上,MLP模型的精确度为86%,稍低于XGBoost模型的精确度93%。然而在召回率上,MLP模型为79%,略高于XGBoost模型的74%。总体而言,MLP模型在煤炭岩性的综合性能略优,其F1值为83%,稍大于XGBoost的82%。至于白垩岩岩性,两者的召回率相等,均为89%。但XGBoost模型的精确度为95%,明显高于MLP模型的86%,导致XGBoost模型的F1值为92%,优于MLP模型的88%。对于砂岩、泥质砂岩、凝灰岩、泥岩、白云岩和盐岩这6种岩性,XGBoost模型在精确度、召回率和F1值方面均优于MLP模型(表3)。这些综合结果明确显示,XGBoost模型在岩石岩性分类任务中表现更为出色,具有更高的准确性和综合性能。
图5
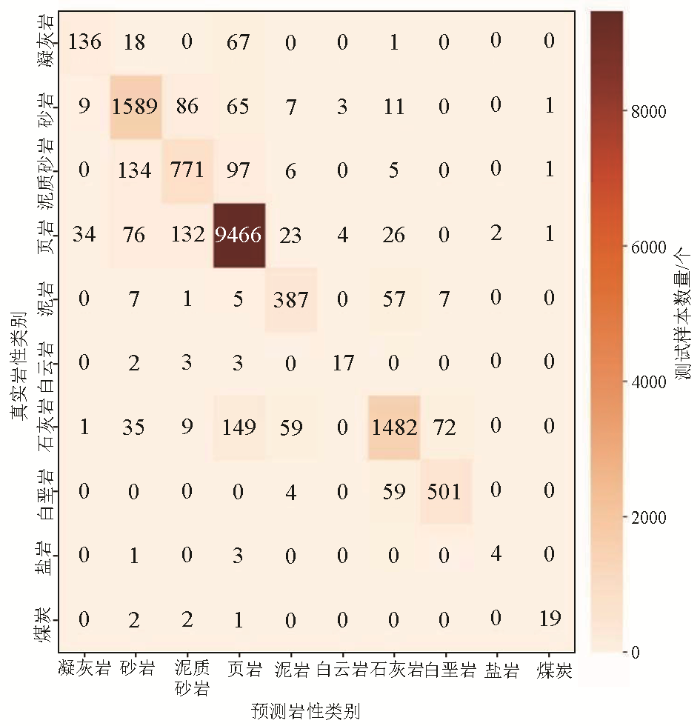
图6
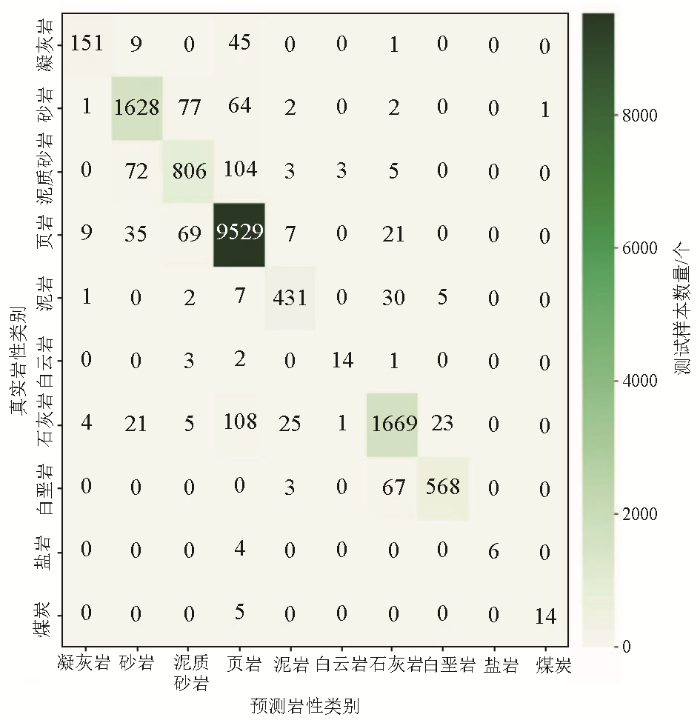
图6
XGBoost模型分析岩性混淆矩阵
Fig.6
Confusion matrix of lithology analyzed by the XGBoost model
表3 MLP和XGBoost模型分类报告
Table 3
| 岩性 | 编号 | MLP模型 | XGBoost | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 精确度/% | 召回率/% | F1值/% | 支持度 | 精确度/% | 召回率/% | F1值/% | 支持度 | ||
| 凝灰岩 | 0 | 0.76 | 0.61 | 0.68 | 222 | 0.91 | 0.73 | 0.81 | 206 |
| 砂岩 | 1 | 0.85 | 0.90 | 0.87 | 1771 | 0.92 | 0.92 | 0.92 | 1775 |
| 泥质砂岩 | 2 | 0.77 | 0.76 | 0.76 | 1014 | 0.84 | 0.81 | 0.82 | 993 |
| 页岩 | 3 | 0.96 | 0.97 | 0.96 | 9764 | 0.97 | 0.99 | 0.98 | 9670 |
| 泥岩 | 4 | 0.80 | 0.73 | 0.81 | 464 | 0.92 | 0.91 | 0.91 | 476 |
| 白云岩 | 5 | 0.71 | 0.68 | 0.69 | 25 | 0.78 | 0.70 | 0.74 | 20 |
| 石灰岩 | 6 | 0.90 | 0.82 | 0.86 | 1807 | 0.93 | 0.90 | 0.91 | 1856 |
| 白垩岩 | 7 | 0.86 | 0.89 | 0.88 | 564 | 0.95 | 0.89 | 0.92 | 638 |
| 岩盐 | 8 | 0.67 | 0.50 | 0.57 | 8 | 1.00 | 0.60 | 0.75 | 10 |
| 煤炭 | 9 | 0.86 | 0.79 | 0.83 | 24 | 0.93 | 0.74 | 0.82 | 19 |
| 准确率 | 0.92 | 15563 | 0.95 | 15663 | |||||
| 宏平均 | 0.81 | 0.78 | 0.79 | 15663 | 0.91 | 0.82 | 0.86 | 15663 | |
| 加权平均 | 0.92 | 0.92 | 0.92 | 15663 | 0.95 | 0.95 | 0.95 | 15663 | |
经过详细分析图5和图6,我们可以明显看出XGBoost模型在主对角线上的整体预测结果数量明显多于MLP模型,即XGBoost模型的正确预测结果数量更多。在页岩、白云岩、白垩岩、砂岩和泥质砂岩这几种岩性的预测召回率上,两者相差不大,约为5%。然而,在石灰岩和岩盐这两种岩性的预测中,XGBoost模型相较于MLP模型分别高出8%和10%。相对而言,在凝灰岩和泥岩这两种岩性的预测中,XGBoost模型在召回率上相较MLP模型分别高出12%和18%。然而对于煤炭岩性,MLP模型则优于XGBoost模型5%。总体来看,XGBoost模型的整体识别准确度为95%,而MLP模型整体识别准确度为92%,因此XGBoost模型相对于MLP模型更为优越。
表4呈现了各类岩性的预测F1值,从中可以观察到,在4种模型中,对于白云岩岩性的预测效果相对较弱。具体而言,决策树的F1值为58%,随机森林为64%,MLP为69%,而XGBoost为74%。同时,决策树模型对盐岩、煤炭、泥质砂岩3种岩性的F1值在4种模型中处于最低水平,分别为50%、52%、69%。相较之下,随机森林在这3种岩性上的表现相对一致,分别为86%、75%、81%。XGBoost模型在这些岩性上的F1值为75%、82%、82%。MLP模型在这3种岩性上的表现相对较差,F1值分别为57%、83%、76%。具体而言,MLP模型对盐岩和凝灰岩的预测效果不佳,其F1值分别为57%和68%;然而,在煤炭岩性方面,MLP模型表现最佳,F1值为83%。对于砂岩、页岩、泥岩、石灰岩和白垩岩等岩性,4种模型的F1值大小排序为:XGBoost > 随机森林 > MLP > 决策树。这一综合分析清晰展示了不同岩性在4种模型中的预测性能差异。
表4 各类岩性F1值
Table 4
| F1值(综合性能) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 凝灰岩 | 砂岩 | 泥质砂岩 | 页岩 | 泥岩 | 白云岩 | 石灰岩 | 白垩岩 | 盐岩 | 煤炭 | |
| 决策树 | 70% | 84% | 69% | 96% | 77% | 58% | 86% | 89% | 50% | 52% |
| 随机森林 | 77% | 92% | 81% | 97% | 89% | 64% | 91% | 94% | 86% | 75% |
| MLP | 68% | 87% | 76% | 96% | 81% | 69% | 86% | 88% | 57% | 83% |
| XGBoost | 81% | 92% | 82% | 98% | 91% | 74% | 91% | 92% | 75% | 82% |
3 结论
利用机器学习方法建立包括砂岩、泥质砂岩、页岩、泥岩、白云岩、石灰岩、白垩岩、盐岩、凝灰岩、煤炭在内的10种岩性,以及补偿声波测井(CALI)、电阻率(RD)、密度(RHOB)、自然伽马(GR)、中子孔隙度(CN)、光电吸收截面指数(PEF)、压缩波速度(DTC)、自然电位(SP)8种测井特征曲线之间的非线性映射关系。
对挪威海地区的5口井进行测井数据的岩性预测,建立并比较了决策树、随机森林、MLP和XGBoost 4种模型。XGBoost模型在损失函数上添加了正则项和二阶泰勒展开,同时在底层采用了多线性并行运行,因而在整体的识别准确度方面表现卓越,达到了95%。与之相比,其他模型的性能依次为随机森林模型94%、MLP模型92%、决策树模型90%。
参考文献
利用交会图法识别国外 M 油田岩性与流体类型的研究
[J].
Research on the identification of the lithology and fluid type of foreign oilfield by using the crossplot method
[J].
利用概率统计方法判断岩性
[J].
Determination of lithology through probability statistics
[J].
聚类和判别分析在测井岩性识别中的应用
[J].
The application of cluster and discriminant analyses in logging lithology recognition
[J].
基于交会图和贝叶斯聚类分析法的岩性识别方法
[J].
Method of lithologic identification based on crossplot and Bayesian cluster analysis algorithm
[J].
基于长短期记忆神经网络补全测井曲线和混合优化XGBoost的岩性识别
[J].
Lithology identification based on LSTM neural networks completing log and hybrid optimized XGBoost
[J].
基于决策树方法的砾岩油藏岩性识别——以克拉玛依油田六中区克下组油藏为例
[J].
Lithological identification of conglomerate reservoirs base on decision tree method
[J].
基于随机森林的K-近邻算法划分火成岩岩性
[J].
DOI:10.3969/j.issn.1006-6535.2021.06.008
[本文引用: 1]

针对火成岩油气藏火成岩岩性划分难,岩性划分准确率受薄片鉴定样本数量影响大的问题,利用随机森林(RF)算法分析不同的测井曲线与火成岩岩性相关性,再利用K-近邻(KNN)算法划分小样本薄片鉴定情况下的火成岩岩性。将研究成果应用于川西地区二叠系火成岩地层,结果表明:测井曲线与岩性相关程度从高到低依次为GR、R<sub>t</sub>、DEN、CNL、AC;KNN算法划分火成岩岩性,k取值受分类数量和训练样本数量2个因素控制,样本数量较小时后者影响程度大于前者;k为3时,24个火成岩训练样本(5种岩性)KNN法回判准确率为87.5%,14个火成岩(5种岩性)测试样本测试准确率为92.5%。对比图版划分火成岩岩性,KNN算法受人为影响小,参数调节简便。该研究对小样本情况下火成岩岩性划分有重要指导意义。
Classification of igneous rock lithology with K-nearest neighbor algorithm based on random forest (RF-KNN)
[J].
Simplifying decision trees
[J].DOI:10.1016/S0020-7373(87)80053-6 URL [本文引用: 1]
基于改进随机森林算法的不平衡数据分类方法研究
[J].
Research on imbalanced data classification method based on improved random forest algorithm
[J].
基于多层感知机网络的薄储层预测
[J].
Characterization of thin sand reservoirs based on a multi-layer perceptron deep neural network
[J].
XGBoost:A scalable tree boosting system
[C]//
基于XGBoost的测井曲线重构方法
[J].
Reconstruction of well logs based on XGBoost
[J].
基于集成学习的松辽盆地砂岩型铀矿地层岩性自动识别研究
[J].
DOI:10.7538/yzk.2023.youxian.0101
[本文引用: 1]
地层岩性的准确识别与砂岩型铀矿层的圈定密切相关,岩性组合的正确分析对于开展砂岩型铀矿的勘查与异常识别具有重要意义。本文针对传统测井岩性识别方法与机器学习类方法中存在的问题,以北方松辽盆地砂岩型铀矿为研究对象,采用两种典型的集成算法模型(XGBoost和SMOTE随机森林)开展地层岩性自动识别研究,并将识别结果与K最近邻分类算法(KNN)、梯度提升决策树算法(GBDT)等典型机器学习算法进行对比。结果表明,XGBoost和SMOTE随机森林两种集成算法模型对砂岩型铀矿地层岩性识别的准确率都在95%以上,且较KNN模型和GBDT模型的准确率有明显提高。XGBoost模型用于控制过拟合的正则项和节点分裂时支持特征多线程进行增益的计算,显著提高了运算效率,SMOTE合成少数过采样技术解决了样本数据不平衡的问题。基于集成算法的优化过程可为砂岩型铀矿岩性分类问题提供理论依据与技术支撑。
Automatic lithology identification of sandstone-type uranium deposit in Songliao basin based on ensemble learning
[J].
DOI:10.7538/yzk.2023.youxian.0101
[本文引用: 1]
The accurate identification of stratigraphic lithology is closely related to the delineation of sandstone-type uranium deposits. In the face of complex stratigraphic structure, the correct analysis of lithology combination is of great significance to the exploration and anomaly identification of sandstone-type uranium deposits. In uranium exploration, geophysical logging data, as a bridge between the change of geophysical properties and the underground geological environment, is an effective and irreplaceable method to understand the underground rock structure and reservoir characteristics. Conventional lithology identification methods such as crossplot method, probability statistic method, cluster analysis method and conventional machine learning class method have some defects, such as low accuracy, identification efficiency and generalization ability. Ensemble learning is a method of achieving consensus in predictions by integrating significant attributes of two or more models, making the final learning framework more comprehensive than that of a single component model, reducing errors and other factors. Compared with ordinary machine learning algorithms, integrated learning algorithms have more advantages in data processing. In this paper aiming at the problems existing in traditional logging lithology identification methods and machine learning methods, the sandstone-type uranium ore in Songliao basin in north China was taken as the research object, and the original data were analyzed and pretreated. Combined with previous studies, two typical integrated algorithm models (XGBoost and SMOTE random Forest) were used to carry out automatic lithology identification of sandstone-type uranium ore in Songliao basin, and the recognition results of the two integrated algorithm models were compared with K-Nearest Neighbor (KNN), Gradient Boosting Decision Tree (GBDT) and other typical machine learning algorithm models were also compared. The results show that the accuracy of XGBoost and SMOTE stochastic forest integrated algorithm model for lithology identification of sandstone-type uranium ore is above 95%, and the accuracy of KNN model and GBDT model is significantly improved. In order to solve the problem of overfitting in operation, XGBoost algorithm model was used to control the regular term of overfitting and node splitting, and support characteristic multithreading to calculate the gain, which improves the operation efficiency and ensures the reliability of the integrated algorithm model. SMOTE synthetic minority oversampling technique solves the problem of sample data imbalance in the random forest algorithm model. The optimization process based on integrated algorithm model provides a theoretical basis for lithology classification of sandstone-type uranium deposits, and provides technical support for strategic breakthrough in uranium exploration.
基于深度学习岩性分类的研究与应用
[J].
Research and application of lithology classification based on deep learning
[J].
Performance analysis of text classification algorithms using con-fusion matrix
[J].
基于深度学习的测井岩性识别方法研究与应用
[J].
Research and application of logging lithology identification based on deep learning
[J].
基于LSTM循环神经网络的岩性识别方法
[J].
Lithology identification based on LSTM recurrent neural network
[J].
基于梯度提升决策树算法的岩性智能分类方法
[J].
Intelligent lithology classification method based on GBDT algorithm
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}