

0 引言
利用测井数据预测煤层工业组分和发热量是弥补煤样分析不足的重要方法,孟召平等[4]以河南新郑矿区赵家寨井田为依托,通过试验和统计分析建立了煤的工业分析指标与测井参数的相关关系及模型,邵先杰等[5]采用枚举法标定出了煤样的工业组分含量、孔隙度、含气量以及密度和声波速度等参数,潘和平等[6]利用体积模型法和回归分析法建立了煤储层固定碳、灰分、水分和挥发分的测井解释模型,也有一些研究工作者采用神经网络等方法建立了煤质测井解释模型[7⇓⇓⇓⇓-12]。但前人的研究多以煤层气勘探开发为研究载体,测井参数多、数据质量高,多集中于利用单一来源数据对特定煤层的煤质定量解释。以往以煤层定厚解释为目的的测井实际生产中,测井参数少,也较少有人利用仪器校验资料对数据进行适时校正并计算岩石密度,难以利用该测井数据进行定量解释评价。
以宁夏宁东煤田某井田延安组含煤地层为研究对象,利用详查、勘探阶段取得的数字测井和煤质化验数据,通过统计分析等方法研究了煤质特征。对测井响应特征进行了研究,分析了研究区测井响应的主要影响因素。建立了样本集中测井响应特征提取方法和数据预处理流程。在此基础上,建立了多源测井数据预测煤层工业组分和发热量的深度神经网络模型,通过对测试数据预测结果和试验分析结果对比分析,验证了模型有效性。
1 研究区地质概况
研究区位于宁夏回族自治区宁东煤田,井田内地形起伏不大,大部分为沙丘覆盖,多系风成垄状及新月形流动沙丘,间有被植被固定、半固定沙丘。
井田地表无基岩出露,根据钻孔揭露井田地层由老至新依次为:三叠系上统上田组(T3s);侏罗系中统延安组(J2y)、中统直罗组(J2z)、上统安定组(J3a);古近系渐新统清水营组(E3q)和第四系(Q)。井田含煤地层为侏罗系中统延安组(J2y),据钻孔揭露最小厚度262.85 m,最大厚度341.59 m,平均厚度295.79 m,含煤层25层,平均总厚度31.01 m,其中可采煤层19层。含煤地层沉积环境呈以河流作用为主的湖泊三角洲特征。
2 煤层煤质特征
研究区可采煤层以不粘煤为主,少量长焰煤,属低灰、低硫、低磷、中高挥发分的高热值煤。如图1所示,研究区原煤试验煤样水分的质量分数(Mad)总体在1.73%~19.29%,各煤层平均为6.23%~9.40%;干燥基灰分的质量分数(Ad)总体在3.28%~36.73%,各煤层平均为8.45%~13.15%;干燥无灰基挥发分的质量分数(Vdaf)总体在25.44%~43.34%,各煤层平均为31.57%~35.47%;干燥基固定碳的质量分数(FCd)在38.56%~70.70%,各煤层平均为54.62%~61.55%;发热量(Qgr,d)总体在19.86~31.90 MJ/kg,各煤层平均为26.82~28.83 MJ/kg。
图1
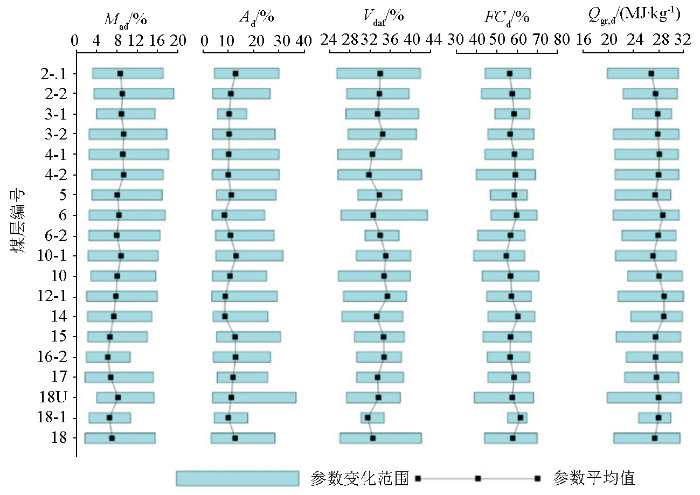
图1
研究区可采煤层煤质特征
Fig.1
The characteristic map of coal quality of mineable coal seams in the study area
图2
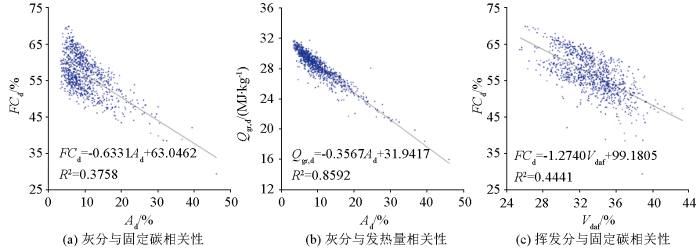
图2
研究区煤质数据线性相关性
Fig.2
The linear correlation diagram of coal quality data in the study area
研究区夹矸Ad平均为55.70%~87.07%,远高于煤层的Ad值。因采取的部分煤芯样混入了夹矸,导致部分煤层Ad偏高,相应Qgr,d偏低。在统计分析中,Ad平均值显得偏“小”,Qgr,d平均值显得偏“大”(图1)。混入夹矸的煤芯样煤质多具有“离群值”特征,可以用统计检验等方法剔除,降低其影响。
3 煤层测井响应特征及主要影响因素
3.1 煤层测井响应特征
研究区含煤地层的岩层随岩石粒度由细变粗,岩石泥质含量逐渐减少,测井响应表现为:自然伽马数值逐渐减小,电阻率值逐渐增大,人工伽马数值逐渐增大,自然电位由零向负方向变化。
煤层相对围岩具有低密度、低放射性、中—高电阻率的特点,在人工伽马和视电阻率曲线上为明显高值异常反应,自然伽马曲线为显著低值异常,自然电位多为负异常。但不同区域的沉积环境不同,同一煤层的结构、顶底板岩性、物理性质、工业组分等要素存在差异,测井曲线形态、特征、幅值等方面也会不一致(图3),这也就是利用测井数据预测煤层工业组分和发热量的物理基础。
图3
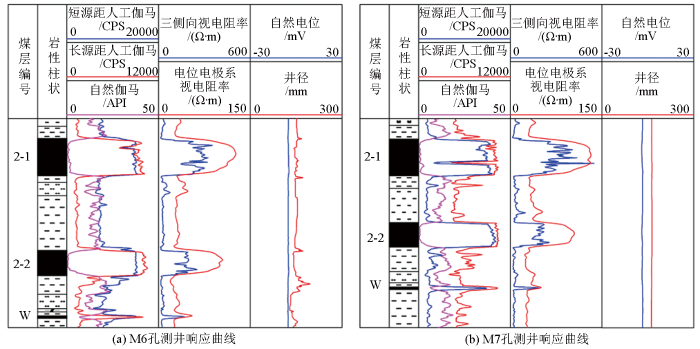
图3
研究区煤层测井响应特征
Fig.3
The logging response characteristics of coal seams in the study area
3.2 测井响应主要影响因素
测井响应是地层、钻孔、仪器等多种因素叠加的综合反映,所以在研究测井响应特征与煤层工业组分和发热量的关系时,研究测井响应的影响因素是必要的。
3.2.1 测量方法对测井响应的影响
测量方法对测井响应的影响主要是电极排列方式、极距、收发距等因素不同造成测井响应差异。如图3所示,两种人工伽马方法因源距不同,造成曲线特征有较大差异;两种视电阻率测量方法(三侧向测井、A0.1M电位电极系法)因装置类型不同,产生的视电阻率曲线响应特征明显不同。在实际生产研究中,正是利用了不同测量方法的响应差异,针对性地解决了不同地质问题,如三侧向电阻率纵向分辨率较高、探测深度大,但电位电极系法对厚层划分更有利;补偿密度法正是利用了长、短源距间响应差异,是一种精度更高的测量岩石密度方法。因此,测井方法使用目的不同,响应也存在明显差异,所有测井曲线均应作为定量预测的依据。
3.2.2 数据多源性特征的影响
图4
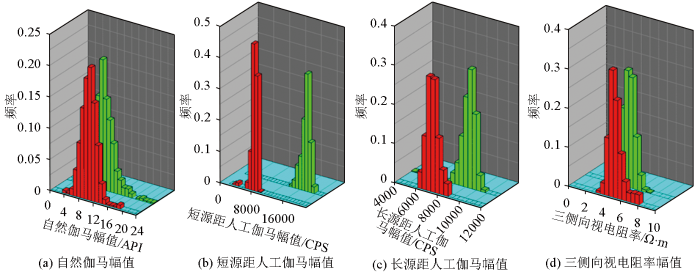
图4
研究区典型测井曲线幅值频率直方对比
Fig.4
The amplitude frequency histogram of typical logging curves in the study area
表1 研究区典型测井曲线幅值特征统计
Table 1
| 测井方法 | 自然伽马/API | 短源距人工伽马/CPS | 长源距人工伽马/CPS | 三侧向视电阻率/(Ω·m) | ||||
|---|---|---|---|---|---|---|---|---|
| 对比内容 | ||||||||
| 详查阶段 | ||||||||
| 勘探阶段 | ||||||||
3.2.3 煤层厚度对测井响应的影响
受仪器分辨率和体积效应影响,测井信号反映的不是记录点的真实物理性质。当煤层厚度小于仪器分辨率时,测井响应幅值降低,无法呈现真实地层物性特征。地层越薄,影响越明显,如图3中“W”煤层为典型薄煤层测井响应特征。
3.2.4 孔内环境对测井响应的影响
4 预测模型建立
4.1 样本集建立
提取样本数据时,对有煤芯样试验分析的煤层,提取对应煤层深度段测井参数(自然伽马、长源距人工伽马、短源距人工伽马、A0.1M电位电极系视电阻率、三侧向视电阻率、自然电位、井径)的响应特征,与煤层厚度共同组成样本的36个输入特征,分别与煤层工业组分(Mad、Ad、Vdaf、FCd)和发热量(Qgr,d)组成5组初始样本集。不同来源的数据单独建立样本集。
对样本集的数据预处理主要有2个方面:一是利用“箱形图”剔除工业组分和发热量数据中的离群点,减少离群点对数据分布特征影响;二是为了减少同一测井参数的多源性差异和不同参数的量纲差异,对不同来源数据分别进行归一化。数据预处理完成后,合并形成样本集。
为减少煤层宏观结构对煤质和测井数据的影响,本研究仅采用了对单层煤采样的煤质化验结果,与相应测井数据组成样本集。剔除离群值后的样本集数量为938个,如表2所示。
表2 样本集样本数量统计
Table 2
| 数据源 | 初始样本集 样本数量/个 | 剔除离群点后 样本数量/个 |
|---|---|---|
| 详查阶段 | 482 | 453 |
| 勘探阶段 | 521 | 485 |
| 合计 | 1003 | 938 |
4.2 样本数据相关性分析
如图5所示为样本集测井归一化数据与工业组分和发热量线性相关系数热度,其中Mad、FCd和Qgr,d与部分样本特征具有相关性,多数特征线性相关系数在±0.2以上,部分接近±0.5;Ad和Vdaf与测井数据相关性较弱,基本都在±0.1以下。煤质参数间的相关性与前文研究基本一致,Ad与FCd和Qgr,d有强线性相关性;Vdaf和FCd有强相关性,和Qgr,d有弱相关性。
图5
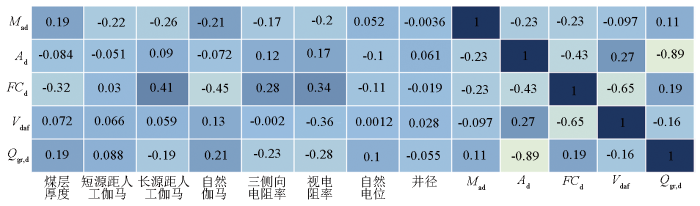
图5
研究区测井归一化数据与煤的工业组分和发热量线性相关系数热度
Fig.5
The linear correlation coefficient heat diagram of normalized logging data and the industrial components and calorific value of coal in the study area
4.3 预测模型建立
煤的工业组分和发热量由煤层自身性质决定,与煤层宏观结构没有直接关系。测井响应不仅与煤层自身的性质有关系,还与煤层宏观结构及孔内环境有关系。因此煤层工业组分和发热量与测井响应之间的关系比较复杂,利用测井数据预测煤层工业组分和发热量,需优先采用非线性预测方法更好,本文采用在人工智能领域应用较广泛的深度神经网络算法进行预测。
本文构建深度神经网络模型使用多层全连接层构建,全连接层每一神经元节点都与上一层的所有节点连接,可以有效地提取前一层特征。如图6所示为深度神经网络结构,网络结构共有7层,即:输入层1层,输入层的节点数为36个,为样本对应深度7条测井曲线的特征值(每条曲线5个,即最大幅值、最小幅值、平均值、中间值、均方根)和煤层厚度倒数组成。隐藏层5层,其中的4层隐藏层均为全连接层,激活函数为线性整流函数(rectified linear unit,简称“ReLU”),节点数均为36个;为减少过拟合问题,在模型中设置了1层随机失活(Dropout)层,失活率为0.3。输出层1层,输出层的节点数为1个,为煤层工业组分和发热量参数,即对每个参数独立建立模型、独立预测。
图6

通过大量不同参数的预测结果进行对比分析,获得了适合于研究区的模型训练和预测参数,如表3所示。
表3 深度神经网络主要配置参数
Table 3
| 预测参数 | 优化算法 | 损失函数 | 批大小 | 训练次数 |
|---|---|---|---|---|
| Mad | Adam | mae | 16 | 2000 |
| Ad | Adam | mae | 8 | 2000 |
| Vdaf | Adam | mae | 8 | 2000 |
| FCd | Adam | mae | 8 | 2000 |
| Qgr,d | Adam | mae | 8 | 2000 |
表4 煤层Ad、Vdaf预测多元线性回归模型
Table 4
| 参数 | 预测方程 |
|---|---|
| 灰分 | Ad=-0.2256×FCd-1.9919×Qgr,d+79.1617 |
| 挥发分 | Vdaf=-0.3574×FCd-0.0162×Qgr,d+54.2128 |
数据预处理、模型建立与数据预测均以Anaconda3环境下的Spyder为开发平台,以Python为开发语言,以TensorFlow、Keras等深度学习框架和工具辅助完成,功能丰富,接口方便,便捷性明显[26]。
5 预测效果验证
对样本集中的938个样本按照一定比例随机分为训练集、验证集和测试集,其中训练集656个,占69.94%;验证集197个,21.00%;测试集85个,占9.06%。训练集和验证集参与模型训练,测试集完全不参与模型训练。
图7
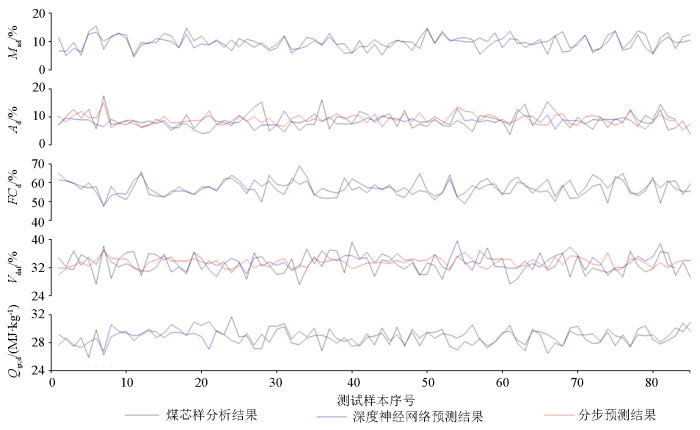
图7
测试集样本预测结果与煤芯样试验分析结果对比
Fig.7
The comparison diagram of prediction results of test set samples and analysis results of coal core samples
表5 测试集中预测结果与样品分析结果对比误差
Table 5
| 煤质参数 | 样品分析结果 ( | 预测结果 ( | 均方根 误差/% | 平均绝 对误差/% | 平均相对 误差/% | 备注 |
|---|---|---|---|---|---|---|
| Mad/% | 2.14 | 1.62 | 18.34 | |||
| Ad/% | 3.06 | 2.41 | 26.89 | 分步预测 | ||
| 3.61 | 2.62 | 29.55 | ||||
| FCd/% | 3.66 | 2.88 | 5.08 | |||
| Vdaf/% | 2.90 | 2.30 | 6.89 | 分步预测 | ||
| 3.42 | 2.58 | 7.78 | ||||
| Qgr,d/(MJ·kg-1) | 1.18 | 0.90 | 3.14 |
对于预测的5项煤质参数,Mad均方根误差2.14%,平均绝对误差1.62%,平均相对误差18.34%;Ad均方根误差3.06%,平均绝对误差2.41%,平均相对误差26.89%;FCd均方根误差3.66%,平均绝对误差2.88%,平均相对误差5.08%;Vdaf均方根误差2.90%,平均绝对误差2.30%,平均相对误差6.89%;Qgr,d均方根误差1.18%,平均绝对误差0.90%,平均相对误差3.14%。所有预测结果均可满足生产需要。
对不同参数预测结果横向对比,Ad预测结果相对较差。其原因为研究区煤层属于低灰分煤,部分夹矸不规律地混入煤芯样后,使试验分析结果与真实结果出现较大的不规律差异。通过剔除离群值等数学方法也不能完全消除其影响。测井数据虽是煤层原位状态下的响应,但通过样本训练的方式并不能消除煤样中混入夹矸对煤层灰分的影响,所以用测井数据预测Ad时的误差较大。
6 结论
1)研究区以不粘煤为主,属低灰、低硫、低磷,中高挥发分,高热值煤。煤质数据中,Ad与FCd、Qgr,d均呈显著线性负相关关系,Vdaf与FCd呈显著线性负相关关系。因煤芯采样时混入夹矸影响,出现部分Ad偏高、Qgr,d偏低现象。
2)利用深度神经网络等大数据技术预测煤层工业组分时,提取测井数据的最大幅值、最小幅值、平均值、中间值和均方根值作为测井响应特征是一种有效方法。将各测井方法响应特征和煤层厚度倒数共同组成样本特征效果较好。
3)在数据预处理中,对煤质数据通过“箱形图”剔除离群数据是一种较有效方法。
4)对差异性较大的多源测井数据,对不同数据源分别进行归一化处理后,再合并成样本集,能有效消除多源数据引起的测井响应差异。
5)利用深度神经网络预测煤层工业组分和发热量是一种有效方法,对于和测井响应线性相关性较高的Mad、FCd和Qgr,d,采用深度神经网络预测效果较好。
6)对于与测井数据线性相关性较低的Ad和Vdaf,先建立Ad、Vdaf与FCd、Qgr,d间的多元线性回归模型,然后基于Mad、FCd和Qgr,d的预测结果和多源线性回归模型再预测
参考文献
利用测井资料评价煤层煤质及含气量的方法研究——以和顺地区为例
[J].
Logging evaluation for coal quality and gas content:A case study in Heshun region
[J].
煤层工业组分的测井评价方法研究及应用
[J].
Research and application of logging evaluation method for industrial components of coalbed
[J].
煤工业分析指标与测井参数的相关性及其模型
[J].
Relationship between approximate analysis of coal and log parameters and its models
[J].
煤岩参数测井解释方法——以韩城矿区为例
[J].
Logging interpretation of coal petrologic parameters:A case study of Hancheng Mining Area
[J].
煤层煤质参数测井解释模型
[J].
Log interpretation model of determining coalbed coal quality parameters
[J].
DOI:10.3390/geosciences12120447
URL
[本文引用: 1]

The French region adjacent to the Mediterranean basin is vulnerable to hydrological risks generated by convective precipitation in the form of heavy rainfall and conditioned by the configuration of the relief. These risks are driven by the increase in sea water temperature over the last half century, which itself has been more pronounced since 1990. The statistical analysis on the frequency of rainfall intensity in a 24 to 48 h interval, correlated with the NAO, WMOI and SSTMED indices shows a recrudescence of rainfall amounting to more than 100 mm, which leads to the genesis of floods and flash floods. Furthermore, there has been a higher frequency of floods and disasters in this period. The intensity of material and human damage recorded following such local Cévennes-type phenomena is also due to urban development and population growth.
煤质工业分析测井解释及三维建模研究
[J].
Study on well logging interpretation and 3D modeling for coal quality industry analysis
[J].
沁水盆地和顺15#煤层煤质参数的测井响应预测
[J].
Logging response prediction of 15# coalbed coal quality parameters in Heshun area Qingshui Basin
[J].
任家庄煤矿煤层煤质测井响应及其预测模型
[J].
Log response of coal quality and its prediction model in Renjiazhuang Coal Mine
[J].
利用测井资料计算煤层含气量及工业组分方法研究
[J].
The method of calculating gas content and industrial components of coalbed by using well logging data
[J].
应用BP神经网络预测煤质参数及含气量
[J].
Applying back-propagation artificial Neural Networks to predict coal quality parameters and coalbed gas content
[J].
遗传神经网络在煤质测井评价中的应用
[J].
Application of genetic neural network to coal quality evaluation based on log data
[J].
基于Hilbert-Huang变换的测井曲线自动分层方法
[J].
Automatic stratification of well logging curves with Hilbert-Huang Transform
[J].
薄层电阻率的测井响应校正方法研究
[J].
Research on log response correction method of sheet resistivity
[J].
测井数据井眼干扰误差校正方法
[J].
Correction method of borehole interference error in logging data
[J].
基于深度学习的中心回线瞬变电磁全区视电阻率计算
[J].
The calculation of full-region apparent resistivity of central loop TEM based on deep learning
[J].
基于深度神经网络的重力异常反演
[J].
Inversion of gravity anomalies based on a deep neural network
[J].
基于深度神经网络的水文频率分析
[J].
Hydrological frequency analysis based on deep neural networks
[J].
Reducing the dimensionality of data with neural networks
[J].
DOI:10.1126/science.1127647
PMID:16873662
[本文引用: 1]
High-dimensional data can be converted to low-dimensional codes by training a multilayer neural network with a small central layer to reconstruct high-dimensional input vectors. Gradient descent can be used for fine-tuning the weights in such "autoencoder" networks, but this works well only if the initial weights are close to a good solution. We describe an effective way of initializing the weights that allows deep autoencoder networks to learn low-dimensional codes that work much better than principal components analysis as a tool to reduce the dimensionality of data.
深度学习的昨天、今天和明天
[J].
Deep learning:Yesterday,today,and tomorrow
[J].
深度学习研究综述
[J].
Overview of deep learning
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}