

0 引言
煤层气勘探是近年来非常规油气资源开发的重点研究方向,准确评价煤层气含量对煤层气井单井产量预测与煤层气产能评估及勘探开发尤为关键[13]。煤层气资源作为非常规油气资源,储集与渗流机理与常规天然气差异较大[4],且煤层气含量受控于多因素,机理复杂,例如与其埋深、层厚,煤体结构及变质程度,以及储层压力、温度等地质因素均有一定关系[57]。评价煤储层气含量一直是煤层研究的重、难点,煤层气含量评价方法最为直接的是对煤层取心样本直接进行解吸测量,这一方法最为准确,但由于煤层大多较薄且机械强度差易破碎,导致煤层取心率低,对应煤心解吸实验资料较少[8]。国内外学者针对这一问题,结合煤层气储集机理与实验等,提出了一系列方法:从KIM法将储层因素与水分等工业组分相关联,后基于这一方法将工业组分引入并对其分析得到KIM改进方程[9,10];后有学者通过实验建立等温吸附模型,利用等温吸附线对煤层气含量进行预测,并基于这一理论提出兰氏煤阶方程进行评价预测[11,12]。
上述实验方法虽能评价煤层气含量,但多为对样本点进行评价,难以应用到整口井或整个区块,因此通过地球物理测井方法评价煤层气含量等煤层参数逐渐成为研究热点。相较于成本较高的取心方法,测井手段连续性强,性价比与可靠性均较高,将两者结合评价煤层气含量成为了接受度更高,使用更广泛的方法。利用地球物理测井资料预测煤层气含量的方法主要可概括为:原理法、数学地质法及数学统计法。原理法多为直接基于煤层测井资料,通过理论方法形成煤层气含量预测模型,例如将测井体积模型用于评价煤层气含量[13],或利用背景值法[14]计算煤层气含量,但两种方法中参数的选择对结果影响较大,且该类方法泛化性差,只能用于单井或单层评价。也有部分数学地质方法被用于煤层气含量预测,田敏等[15]将灰色系统理论结合实验数据对煤层气含量建立灰色多变量静态模型,随后郭建宏等[16]基于此将灰色多变量静态模型与测井曲线相结合将这一方法泛化性增强,能连续且准确地评价出整段煤层的气含量曲线,这类方法更多从数据上出发,得到的结果不一定能与理论完全相符。相比之下,数学统计法在煤层气含量预测中应用的更为广泛。由于煤层的复杂性,测井响应与煤层气含量间的关系也复杂多样,可能为线性亦或非线性关系,因而统计法多以回归分析及机器学习算法为主。回归分析法即是通过研究测井曲线与目标气含量的相关关系找到与煤层气含量敏感的测井曲线,利用最小二乘法计算出煤层气含量回归评价模型,这一方法简单且效果稳定,被广泛应用于煤层气含量评价。梁亚林等[17]利用测井曲线建立多元回归方程预测气含量并以此为基础对相应区块进行气含量预测,结果与地质情况相吻合;黄兆辉等[18]与金泽亮等[19]针对沁水盆地将多元线性回归法与兰氏方程相结合,建立煤层气含量评价模型,结果准确度较高,具有有效性。当线性关系难以表征煤层气含量与测井曲线间的关系时,可利用机器学习等方法进行预测,这类方法非线性逼近能力强,以神经网络方法为主,已有许多学者对此进行研究,将特征参数与目标参数通过神经网络进行训练形成网格模型,对测试集进行泛化性测试,以此评价模型的实用性。上述方法对存在潜在联系但无法直接用表达式展示的问题有明显优势,例如将煤层气含量与测井曲线资料通过BP神经网络进行训练,后对区块其他井进行验证发现这一方法预测煤层气含量精度高[20-21];随后支持向量机[22]等更多算法被引入到煤层气含量预测中。
在实际应用中,各类方法均受到不同程度的限制,体积模型法等原理传统方法受参数选择影响大且泛化性差而无法被推广使用;多元回归法由于各测井曲线对气含量响应的灵敏度不同使得结果会出现偏差,且这类方法对数据量要求大,与煤层取心率低样本少的特点相冲突;BP神经网络训练的复杂性大,参数选择对模型影响大且对样本量有一定要求,使用局限性明显;支持向量机回归对小样本适用性强但容易过拟合;随机森林算法可利用袋外数据直接检测泛化性,且可利用有放回抽样解决样本数据少的问题[23],因此也被应用于复杂储层参数预测中[24],相比其他传统机器学习方法,随机森林算法更适合解决煤层小样本参数预测问题。基于此,笔者将斜率关联度法与随机森林相结合,基于测井曲线对煤层气含量进行斜率关联度分析,剔除冗余数据,即通过斜率关联法筛选出与煤层气含量敏感的测井曲线作为特征向量,并基于分析结果结合随机森林算法进行决策树个数优选,建立模型对煤层气含量进行预测,并用实际数据来验证本文方法的有效性与实用性。
1 基本原理
1.1 斜率关联度计算
一般关联度最早由邓聚龙教授提出,该分析法对样本数量小且分布无明显规律的数据有较强的实用性,计算结果与定性分析符合。一般关联度基本思想为将各序列与目标序列曲线形态进行对比,其几何形状接近,序列间关联度大,反之则小[25]。实际使用时,普通的关联度法存在缺陷,许多学者提出了改进,例如为了克服在规范性与保序性上的不足提出普通斜率关联度法[26],即在不同序列上对比各序列段斜率的接近程度来计算各序列间关联度大小,斜率越接近则关联度越大,反之则越小。后在此基础上进行了改进,对斜率的正负进行了计算[27],使其既能反映正关联也能找到负关联,极大提高了评价的精确性。规定一参考序列x0与一对比序列xi,其形式分别为:
则改进的斜率关联法公式为[28]:
式中:
1.2 随机森林
1.2.1 随机森林原理
即每棵树约有36.8%的样本未被抽取参与建模,将此类数据称为袋外数据(OOB,out of bag)。Bagging思想在随机化建立更多的决策树时还保证其相互独立性。与Bagging思想类似,随机子空间思想可以保证不同树节点与其节点间的特征子集的差异性,以及树的独立性与多样性,即在构建决策树的过程中,每个分裂节点的特征数选取一般为从总特征空间F中随机抽取f(推荐为f=log2F)个特征,并依照Gini指标选取最优特征进行分支生长。因而在随机森林回归中,决策树K与特征数f对模型预测性能存在显著影响。
1.2.2 随机森林泛化误差
以遵循独立同分布的随机向量(X,Y)为例,结合式(5),则h(X)对应均方泛化误差为:
在随机森林回归中,若决策树的个数趋于无穷时,存在:
式中:θk为第k个决策树的随机变量;Eθ对应数学期望;P
式中:
1.2.3 随机森林流程
随机森林回归算法流程为:
1) 应用boostrasp采样随机生成训练数据集,未被抽中的为袋外数据,再随机抽取m个特征进行节点分裂,结合数据集中建模数据构建决策树;
2) 按照上述方法构建K棵回归决策树,令其充分生长,不进行剪枝,形成随机森林;
3) 利用袋外数据误差(OOB error)评价对效果进行评价,公式为:
式中:yi与
4) 利用上述步骤确定的模型对目标数据样本进行预测,随机森林各决策树预测结果的平均为最终预测输出结果。
1.3 煤层气含量评价步骤
结合本文实际内容,实行步骤为:
1) 利用斜率关联度计算各测井曲线与煤层气含量的关联性,并根据实际计算结果筛选出有利于煤层气含量建模的数据;
2) 利用选取出的测井曲线结合随机森林算法进行建模,并探究出合适的回归决策树的数目;
3) 根据探究得到的特征个数与回归子树个数进行建模,并用未参与建模的数据进行预测验证。
2 煤层气含量预测模型
2.1 应用工区概况
图1
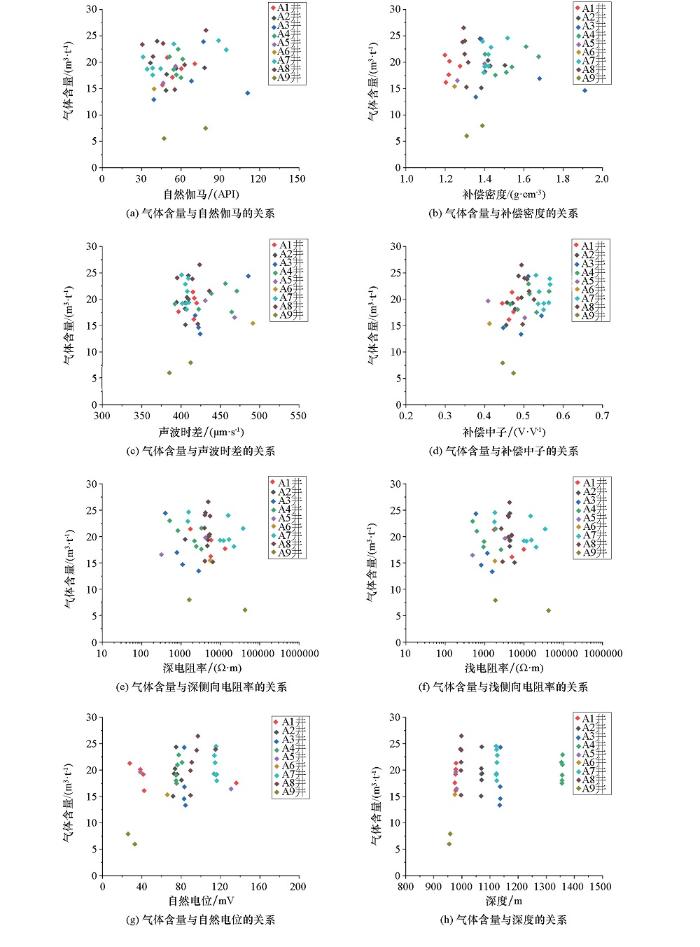
图1
煤层气含量与测井参数间的关系
Fig.1
Relationship between coalbed methane content and logging parameters
表1 3号煤层测井响应范围
Table 1
| 参数 | 测试气量/ (m3·t-1) | 自然伽马/ API | 自然电位/ mV | 补偿密度/ (g·cm-3) | 声波时差/ (μs·m-1) | 补偿中子/ (V·V-1) | 深电阻率/ (Ω·m) | 浅电阻率/ (Ω·m) |
|---|---|---|---|---|---|---|---|---|
| 范围 | 5.91~26.07 | 30.4~109.4 | 26~134 | 1.19~1.89 | 384~489 | 0.41~0.56 | 165~33766 | 470~18355 |
| 平均值 | 18.83 | 55.3 | 82 | 1.39 | 419 | 0.49 | 4845 | 4428 |
理论上,煤层埋深一定程度上决定了煤岩产生的气体能否有效储存,在埋深较浅处,煤层气含量随深度增加而增大。孔隙度测井系列包含补偿密度测井、声波时差测井及补偿中子测井。由于煤的基质密度较低,煤层密度值随其致密程度的增加而增大,相应的孔隙度及气含量会降低,因而随着煤层气含量的增加,对应煤的体积密度减小,在补偿密度测井资料上补偿密度测井响应值与煤层气含量理论上应呈负相关关系;煤岩分子结构相对松散,声波时差测井曲线的响应为时差值较高,且其对储层含气性敏感,遇气层会明显增大或出现周波跳跃现象[32],理论上在声波时差测井资料上两者呈正相关关系;煤储层由碳、氢、氧组成且煤层气中含有甲烷,导致含氢指数高,使补偿中子测井资料呈现出一种虚高假象,而实际孔隙度通常较低。岩性测井系列提供了自然伽马测井曲线和自然电位测井曲线。由于煤的自然放射性通常较弱,煤的天然放射性多取决于成煤过程中的外来矿物质,粘土矿物会通过影响煤的吸附性能进而影响煤层气储集,煤层中粘土矿物增多,对应自然伽马测井响应增大,但煤层气含量由于有效孔隙降低而使得气含量减少,即在自然伽马测井资料上呈现出两者为负相关关系;在自然电位测井上,煤层的岩性相对更纯且导电性差,煤岩与泥浆间的化学作用和动电学作用弱,对应自然电位响应较低。电阻率测井系列提供了深、浅侧向电阻率曲线:煤岩电阻率受多因素影响,从煤层气含量考虑,气含量越大,电阻率测井响应越大。
从理论上分析后结合实际交会图进行判断,3号煤层深度范围为953~1 350 m间,每口井实验样本数大多在4~7组,从交会图1h中可发现不同井3号层深度相近,与气含量无明显关联,总体上随深度增加煤层气含量增大。分析煤层气含量与孔隙度测井系列曲线的交会图,结合图1b及补偿密度测井资料得到的响应范围,3号煤层补偿密度测井资料反映煤层的响应区间为1.19~1.89 g/cm3,但纯煤密度较低,若煤层中含泥岩夹矸则会使得补偿密度侧向响应值增大,将A4井中补偿密度过高值与A9井中气含量过低值剔除,则可发现煤层补偿密度测井值与煤层气含量呈负相关关系。图1c与图1d能看出声波时差测井曲线资料中的响应值与煤层气含量趋势上为正相关,但关系较差,补偿中子测井曲线资料上其响应值与煤层气含量呈正相关且关系相对明显,即3号煤层由于煤层气的存在将使得补偿中子测井资料的“虚高假象”更为突出。对应图1a与图1g分析,不同井自然伽马基线存在差异,每口井中存在自然伽马测井响应高值,这一原因多为煤层中泥岩夹矸所致,由于煤层中含泥岩夹矸段会导致自伽马测井响应异常增高进而直接影响了两者相关性;自然电位测井响应与煤层气含量总体上为正相关,但每口井中自然电位测井响应与煤层气含量无明显关系。煤岩电阻率受多方面因素影响,其变质程度、煤体结构、矿物质含量及分布等均会对电阻率测井响应值产生影响,通过图1e与1f分析,煤层气含量与深侧向电阻率总体上无相关关系,仅单井部分样品存在相关性,且煤层气含量与浅侧向电阻率相对深侧向电阻率存在差异,单井来看趋势也并不明显,多因煤层受泥浆侵入影响或扩径导致其表征的并非为原状地层。
综上分析可以看出,煤层气含量与地球物理测井曲线响应间的关系极为复杂,测井响应受多方面因素影响,煤岩本身以及夹矸存在等均会使得煤层段测井曲线响应出现变化。煤层取心率低,样本少,简单数据清洗会使得样本数据减少,且趋势也不一定能准确找到,而传统交会图分析对样本数据量有一定要求且容易受异常值的影响,因而靠交会图难以准确得到适合随机森林算法的特征参数。基于此,本文通过斜率关联度进行相关性分析,这一方法对实验数据具有更好的隐性挖掘能力,且受异常值影响相对小,能对样本数据总体与目标数据进行综合分析,不会由于单个异常点对结果产生较大影响。
2.2 斜率关联度计算
表2 3号煤层斜率关联度计算样本
Table 2
| 样号 | 测试气量/ (m3·t-1) | 深度曲线/ m | 自然伽马/ API | 自然电位/ mV | 补偿密度/ (g·cm-3) | 声波时差/ (μs·m-1) | 补偿中子/ (V·V-1) | 深电阻率/ (Ω·m) | 浅电阻率/ (Ω·m) |
|---|---|---|---|---|---|---|---|---|---|
| A1-1 | 17.32 | 972.94 | 52.96 | 134.34 | 1.21 | 395.9 | 0.47 | 11946 | 9024 |
| A1-2 | 18.93 | 975.28 | 59.63 | 41.22 | 1.27 | 418.5 | 0.44 | 5121 | 3892 |
| A1-3 | 15.90 | 976.00 | 45.51 | 42.10 | 1.20 | 415.1 | 0.46 | 5224 | 4563 |
| ︙ | ︙ | ||||||||
| A9-2 | 7.81 | 956.55 | 77.90 | 25.93 | 1.38 | 411.0 | 0.44 | 1514 | 88 |
表3 3号煤层斜率关联度计算结果
Table 3
| γ(x0,x1) 深度曲线 | γ(x0,x2) 自然伽马 | γ(x0,x3) 自然电位 | γ(x0,x4) 声波时差 | γ(x0,x5) 补偿密度 | γ(x0,x6) 补偿中子 | γ(x0,x7) 深电阻率 | γ(x0,x8) 浅电阻率 | |
|---|---|---|---|---|---|---|---|---|
| 关联度 | 0.134 | 0.056 | -0.049 | 0.163 | 0.183 | 0.168 | 0.196 | -0.076 |
| 关联序 | 5 | 6 | 7 | 4 | 2 | 3 | 1 | 8 |
通过表3可以得到6条与煤层气含量正关联的测井曲线,自然电位与浅侧向电阻率为负关联,正关联曲线中,均能找到理论支撑。在正关联曲线中,自然伽马曲线关联度相对其他测井曲线较低,为了验证这一曲线是否适合用于煤层气含量预测,利用随机森林中袋外误差曲线进行求证。如图2所示,将随机森林决策树个数选定为600个,共作出3条曲线,曲线1为在斜率关联度计算后筛选出的曲线基础上去掉了自然伽马曲线得到的袋外误差数据,曲线2为斜率关联度计算筛选出的曲线得到的袋外误差数据,曲线3为未经斜率关联度计算的全曲线得到的袋外误差数据。经分析可发现,曲线3初始袋外误差大且收敛速度慢但相对稳定,经特征筛选后的袋外误差数据初始误差相对较小且收敛速度慢,曲线1与曲线2均在收敛过程中出现震荡,但很快趋于稳定,且最终曲线2袋外误差最低,即斜率关联度计算结果具有可靠性,包含自然伽马曲线的曲线特征组袋外误差相对低且收敛相对更快。因而证明斜率关联度能更深地发掘与煤层气含量相关的测井曲线,计算结果准确且与理论相符。
图2
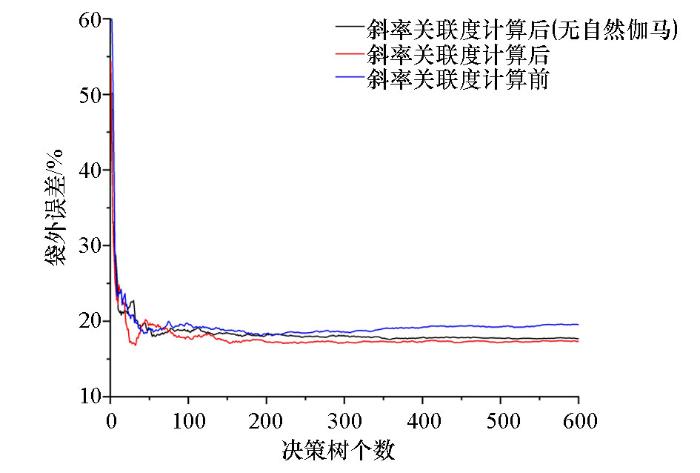
图2
斜率关联度计算前后随机森林袋外误差结果
Fig.2
Results of random forest out of bag error before and after slope correlation calculation
2.3 随机森林决策树优选
为了使随机森林建立的模型具有可靠性和对煤层气含量预测的有效性,需对随机森林的参数进行探究。在优选特征个数的基础上,还需确定决策树的个数。就随机森林这一算法而言,决策树个数的选择能直接影响模型的性能与精度,决策树过少,建立的模型精度低,数据利用不充分,模型效果发挥不充分,决策树过多会导致模型成型慢且增加过拟合发生的风险。由于煤层取心率低且数据稀少,为有效利用数据,将已有的40组数据随机分成4份,每组10个数据,其中1份为测试集,不参与随机森林建模,另外3份数据用于交叉验证以确定决策树的优选范围。具体做法为将3份原始数据中选取两组数据作为训练集对随机森林模型进行训练,再用另外一组数据进行验证,对验证集中的数据进行预测,以验证集中预测值与实验值的MSE作为判别指标。在4组分布中,为保证交叉验证的有效性,煤层气含量分布相对平均,除测试集外,另外3组数据中利用其中两组数据进行训练得到模型,预测另一组样本,通过观测预测结果随决策树个数变化来判断每组合适的决策树个数,结合3组结果进行判断。如图3所示,通过交叉验证,随着决策树个数不断增加,3个组分别作为验证集时的预测值与实验值的均方误差逐渐稳定,在决策树为500个时,3组验证集均方误差趋于稳定且达到低值,因而确定决策树个数为500。如图4所示,以上述3组数据为训练集对随机森林进行训练得到模型,决策树个数设为500,观察其袋外误差, 发现500个决策树时袋外误差已达到最低值且稳定,因而证明上述探究结果有效。
图3
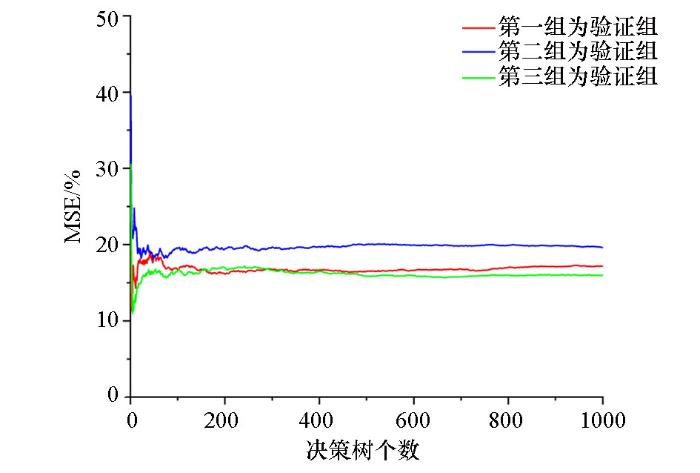
图3
交叉验证探究决策树范围结果
Fig.3
Cross validation to explore decision tree range results
图4
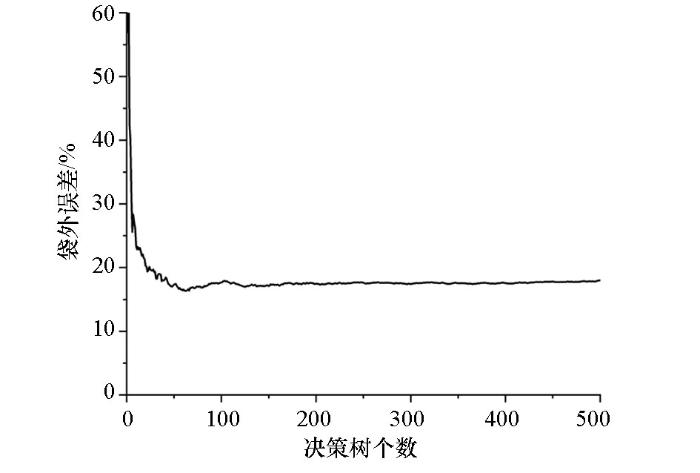
图4
决策树个数为500时袋外误差
Fig.4
Out of bag error when the number of decision trees is 500
2.4 随机森林预测煤层气含量
基于上述对测井曲线特征的优选和对决策树个数的选择,利用上述3组训练集训练得到的随机森林模型预测测试集煤层气含量,结果如图5及表4所示。随机森林计算得到的模型在训练集回判相对误差为19%,针对测试集预测,平均相对误差在 11.1%,并以此为基础对该区块单井3号煤层进行评价预测,以A7井为例,结果如图6所示。随机森林训练得到的模型在测试集上表现稳定,能有效预测煤层气含量,并能以此为基础对区块各井3号煤层进行煤层气含量曲线预测,且预测结果与实验结果相符合,说明该算法对训练集有效且泛化性强,能有效抗过拟合。此外,为了进行对比还对数据进行多元回归拟合,用同样曲线回归拟合出的模型在训练集与测试集上的平均相对误差分别为21%和19%,误差均大于本文算法预测的结果,也说明本文方法相对应用较为广泛的多元回归法能进一步提升预测精度。在预测结果中,发现当煤层气含量为低值时的预测结果都存在较大误差,即含气量低值预测结果相对偏高,针对这一问题,笔者进行了分析。
图5
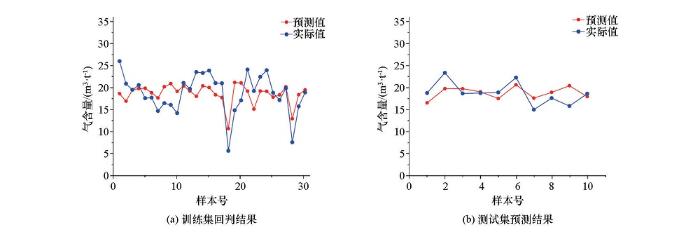
图5
斜率关联度—随机森林预测煤层气含量结果
Fig.5
Slope correlation degree-prediction of coalbed methane content by random forest
表4 3号煤层测试集预测结果
Table 4
| 测试气量/(m3·t-1) | 预测气量/(m3·t-1) | 绝对误差/(m3·t-1) | 相对误差/% | |
|---|---|---|---|---|
| A1-2 | 18.93 | 16.67 | 2.26 | 0.12 |
| A7-5 | 23.53 | 18.93 | 4.60 | 0.20 |
| A7-3 | 18.83 | 19.90 | 1.07 | 0.06 |
| A7-2 | 18.91 | 19.19 | 0.28 | 0.01 |
| A2-6 | 19.07 | 17.66 | 1.41 | 0.07 |
| A8-5 | 22.44 | 20.79 | 1.65 | 0.07 |
| A6-2 | 15.14 | 17.77 | 2.63 | 0.17 |
| A4-2 | 17.76 | 19.08 | 1.32 | 0.07 |
| A3-1 | 15.96 | 20.59 | 4.63 | 0.29 |
| A4-3 | 18.77 | 18.10 | 0.67 | 0.04 |
| 平均值 | 2.05 | 11.10 |
图6
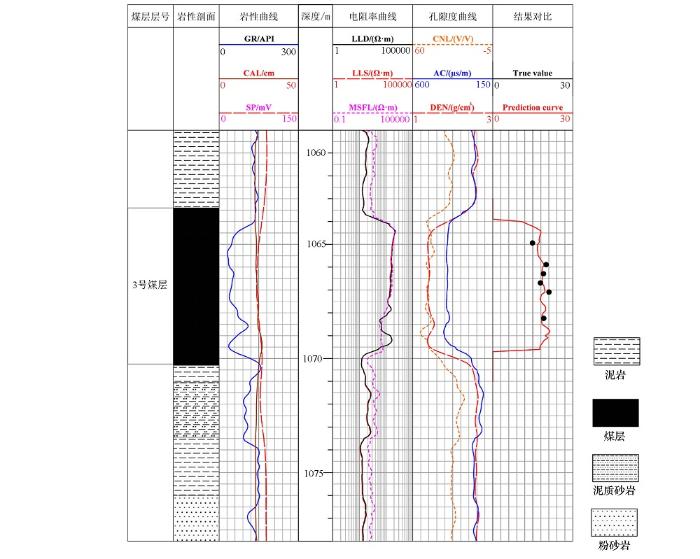
图6
A7井3号煤层气含量预测成果
Fig.6
Prediction results of No.3 coalbed methane content in A7 well
2.5 误差异常值分析
如图7所示,以A3井为例,对比该井3号煤层测井响应值,发现煤层中下段部分存在响应异常值,7号样本自然伽马测井响应值与补偿密度测井响应值明显偏高,深侧向电阻率测井响应值相对较浅部分减小且补偿密度测井响应值超出煤岩最大密度范围,结合柿庄北区综合柱状图发现,该区3号层存在泥岩或炭质泥岩岩性的夹矸,理论上自然伽马测井响应值增加,密度测井响应值增加与深侧向电阻率测井响应值减小理论上表征的应为煤层气含量减小,而A3井7号样本实验结果表明取心处气含量仅略低于其他处且与3号样本持平,这一现象会导致针对该样本的预测结果远低于实际实验情况,即夹矸的存在对煤层气含量预测结果造成了影响。综合分析,夹矸的存在对煤层测井响应会产生较大影响,自然伽马值与补偿密度值异常增高且泥岩电阻率低会使得电率测井资料响应值出现减小波动,所以对应夹矸深度段用于预测煤层气含量的测井资料响应会受到干扰,使得夹矸段气含量评价结果相对异常,而煤层取样难度大,样本量小,受夹矸影响的实验样本少,多元回归法或机器学习法都难以单独对这类情况进行建模评价,随机森林法对该类样本预测误差相对该算法对其他层段预测误差较大,为38.4%,多元回归法对该井夹矸处气含量预测的相对误差为54.8%,相比之下虽然随机森林算法预测误差相对略低,但预测效果均较差,两种方法都无法准确预测。因而随机森林算法能有效预测煤层非夹矸段气含量值,夹矸段难以准确预测,总体对生产上能进行准确指导,对煤层气含量预测评价提供了一种新的思路方法。
图7
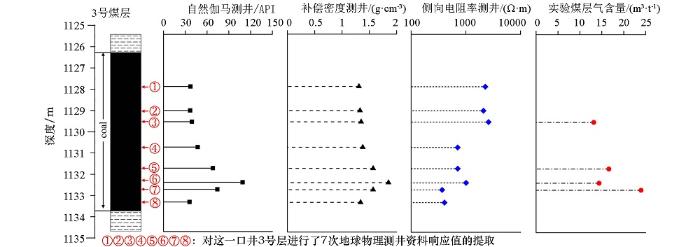
图7
A3井3号煤层响应与实验值分析
Fig.7
Response and experimental value analysis of No.3 coal seam in well A3
3 结论
1) 斜率关联度算法能更好发掘测井资料与煤层气含量间的关系,通过对各条测井曲线与煤层气含量值进行斜率关联度计算分析,对于煤层气含量预测问题,自然伽马、补偿密度、声波时差、补偿中子、深侧向电阻率及深度与煤层气含量为正关联,利用上述测井曲线相对其他曲线组合能降低随机森林算法的袋外误差,提升该算法在煤层气含量预测能力上的泛化性。
2) 针对随机森林算法的超参数中的决策树个数选择中,利用交叉验证计算得到决策树个数为500时,该算法学习效率达到稳定且能充分发挥算法性能,训练出的模型准确且强健。
3) 通过实际计算分析,利用斜率关联度—随机森林法能有效预测煤层气含量,计算精度相对多元回归法更高,但在煤岩夹矸段煤层气含量预测效果欠佳,总体上能有效评价区块煤层气含量。
综上,利用斜率关联度—随机森林法能有效预测煤层气含量,构建出的模型强健且泛化性强,实际应用价值突出,对煤层气勘探开发可提供帮助。
参考文献
中国煤层气地质特征及勘探新领域
[J].根据中国石油天然气股份有限公司煤层气10年勘探经验教训,借鉴国外成功实例,总结了中国煤层气生气、成因、成藏模式,进行了煤层气勘探目标评价参数分类;提出了不同煤阶区的煤层气勘探新认识;梗概阐述了利用以上理论认识发现沁水煤层气田和大宁含气区的基本地质条件。最后分析了煤层气未来勘探新领域。
Geological features of the coalbed methane in China and its new exploration domains
[J].
煤层含气量预测的BP神经网络模型与应用
[J].
Prediction models of coal bed gas content based on BP neural networks and its applications
[J].
煤层含气量的主控因素及定量预测
[J].从煤层的生气潜能和储气能力两个方面分析影响煤层含气量的主控因素,认为煤层的储气能力是造成现今煤层含气量差异分布的主要因素;结合影响工区煤层含气量差异分布的主要地质因素分析,以现有的钻测资料为依据,选取相应的参数,建立适当的BP神经网络模型,对工区的煤层气含量进行预测分析.预测结果与实测资料对比分析表明:预测的煤层气含量与实测的煤层气含量之间的误差较小,且明显优于线性回归预测的结果.
Main controlling factors analysis and prediction of coal bed gas content
[J].
影响煤层气井产量的因素分析
[J].煤层甲烷在煤储层中的储集及渗流与常规天然气大不相同,其影响因素多样而复杂。 影响煤层气产量的主要因素是煤层渗透率、煤层厚度及含气量。大量煤层气井生产实践证明,含气量是影响产量的物质基础,而渗透率是影响产量大小的控制性因素。煤层含气量与煤层厚度及埋深一般有正相关关系,而渗透率一般随埋深增加而减小。用产气潜能与产气能力将更全面地反映含气量及渗透率对煤层气井产量的影响。把含气量引入达西流产量公式也许能更真实地反映甲烷气体在煤储层中流动产出的特征。
Factors of influencing production of coal bed gas wells
[J].
煤层气富集高产的主控因素
[J].对煤岩的生储气能力、煤储层渗透率、煤层气保存条件等影响煤层气高产富集的主控因素进行了分析。煤岩组分和煤变质程度是影响煤层生储气能力的主控因素。煤层的储气能力与温度、压力、灰分及水分含量等亦有关。煤层的渗透率取决于煤层本身的裂隙系统,而裂隙的发育程度又与煤变质程度及构造活动的强弱相关。煤层气的保存则取决于顶底板的封盖能力、构造活动、水动力环境等条件。煤层气成藏条件是煤层气基础地质研究中的核心问题,应加强研究。
Main controlling factors analysis of enrichment condition of coalbed methane
[J].
煤层气储层异常压力的成因机理及受控因素
[J].在煤层气储层压力的内部和外部成因分析的基础上,重点从生烃条件﹑保存及封盖条件、水动力条件3方面分析了煤储层异常压力的形成机理及控制因素.根据沁水盆地煤炭开采阶段收集的大量地层压力资料,研究了影响该地区煤层气储层异常压力的主要控制因素及其时空匹配,分析了压力封闭和泄露的地质条件,重点对沁水盆地的异常压力的成压机理进行了探讨,得出造成沁水地区异常低压的主要原因是生烃作用停止以及构造抬升造成煤层气大量逸散.
The formation mechanisms of abnormal pressure and factor in control of the coal bed gas in Qinshui Basin
[J].
水文地质条件对煤层气赋存的控制作用
[J].
Controlled characteristics of hydrogeological conditions on the coalbed methane migration and accumulation
[J].
基于测井信息的韩城地区煤体结构的分布规律
[J].韩城地区煤层受多期构造破坏,煤体结构复杂,煤层气井出粉较为严重,目前对区内煤体结构分布规律研究尚且不足,制约了区内煤层气产能提高。通过对韩城地区测井资料与钻井取芯样品进行对比分析,总结出了不同煤体结构的深侧向电阻率测井、双井径测井及自然伽马测井曲线组合特征,并利用测井曲线组合特征识别煤体结构及分层定厚,进一步通过对研究区24口煤层气井测井资料的分析,揭示3号、5号和11号煤层煤体结构平面分布规律及其与区域构造的关系。研究表明:① I类煤(块煤)扩径轻微,电阻率偏高;II类煤(块粉煤)扩径严重且差异扩径现象明显,电阻率偏低;III类煤(粉煤)扩径严重且部分出现轻微差异扩径现象,电阻率偏低。② 边缘浅部隆起构造带、龙亭构造带、东泽村构造带和龙骨岭构造带控制了区内3号、5号和11号煤层煤体结构分布,II类煤和III类煤基本沿着构造带走向展布,同一构造带对不同煤层的破坏程度不同。
The distribution of coal structure in Hancheng based on well logging data
[J].
基于多元逐步回归分析的煤储层含气量预测模型——以沁水盆地为例
[J].
A predictive model of gas content in coal reservoirs based on multiple stepwise regression analysis: A case study from Qinshui Basin
[J].
Estimating methane content of bituminous coal beds from adsorption data
[R].
煤岩参数测井解释方法——以韩城矿区为例
[J].
Logging interpretation of coal petrologic parameters: A case study of Hancheng mining area
[J].
煤层煤质和含气量的测井评价方法及其应用
[J].根据辽河油田东部凹陷煤储层的地质特征以及实际煤岩芯分析资料和测井资料,利用回归分析方法得出了计算煤层各组分含量和煤阶的方法;通过分析煤层气特征,利用兰氏方程、吸附等温线和煤层气层中子背景值导出了煤层含气量的计算公式,并通过辽河油田东部凹陷实际煤储层测井资料的处理解释验证了方法的有效性。
The logging evaluation method for coal quality and methane
[J].
灰色系统理论在煤层气含量预测中的应用
[J].
Application of grey system theroy in prediction of coalbed methane content
[J].
基于灰色系统与测井方法的煤层气含量预测及应用
[J].
Prediction and application of coalbed methane content based on grey system and logging method
[J].
测井预测煤层气含量及分布规律——以山西省沁水煤田为例
[J].
The prediction of the content and distribution of coalbed gas: A case study in the Qinshui coalfield based on logging
[J].
沁水盆地南部TS地区煤层气储层测井评价方法
[J].煤层气是一种自生自储于煤岩地层的非常规天然气资源,其储层测井评价内容及方法不同于常规天然气,在煤层气勘探开发过程中更关注于有关煤岩工业分析组分、基质孔隙度、裂缝渗透率及煤层含气量等一系列关键的储层参数。针对沁水盆地南部TS地区煤层气勘探目标层,分析了各种测井响应特征,采用回归分析法计算煤岩工业分析组分;针对煤层气含量影响因素众多且较为复杂的特点,结合相关地区煤岩样品实验分析结果,利用基于等温吸附实验的兰氏煤阶方程估算煤层含气量参数;通过煤岩孔隙结构的分析,采用变骨架密度的密度孔隙度计算公式求取煤岩总孔隙度,利用迭代逼近算法计算裂缝孔隙度;根据煤岩裂缝中面割理发育而端割理不甚发育的特点,以简化的单组系板状裂缝模型计算煤岩裂缝渗透率。通过对TS-A井进行实际计算,结果表明,煤岩工业分析组分和煤层含气量计算结果精度高,总孔隙度一般在55%左右,而裂缝孔隙度则大多小于05%,裂缝渗透率主要分布在0001×10-3 ~10×10-3 μm2之间,孔渗参数计算结果与相邻井区现有资料相符。采用测井方法可以快速、系统地对煤层气储层多种参数进行准确评价。
Coal bed methane reservoir evaluation from wireline logs in TS District, southern Qinshui Basin
[J].
煤层气储层测井评价技术及应用
[J].
Technology for evaluation of CBM reservoir logging and its application
[J].
煤层含气量测井解释方法探讨
[J].
Discussion on the interpretation method of coalbed methane content
[J].
煤层气测井评价的神经网络技术
[J].
Neural network of coal bed gas logging evaluation
[J].
基于支持向量机回归的煤层含气量预测
[J].
Prediction of coal bed gas content based on support vector machine regression
[J].
利用随机森林回归算法预测总有机碳含量
[J].
Predicting total organic carbon content by random forest regression algorithm
[J].
灰色关联度计算的改进及其应用
[J].
A modified computation method of grey correlation degree and its application
[J].
一种相似性关联度公式
[J].构造了一种新的关联度计算公式 ,其基本思想与斜率关联度相同 ,它克服了斜率关联度的缺点 ,而保持了其优点 ,它适用于进行因素分析.
A formula of similarity correlation degree
[J].
灰色关联度新判别准则及其计算公式
[J].
A new descriminant byelaw for grey interconnet degree and its calculation formulas
[J].
灰色关联度计算方法比较及存在问题分析
[J].
Comparison between computation modles of grey interconnet degree and analysis on their shortages
[J].
Random forests
[J].
DOI:10.1023/A:1010933404324
URL
[本文引用: 2]

Random forests are a combination of tree predictors such that each tree depends on the values of a random vector sampled independently and with the same distribution for all trees in the forest. The generalization error for forests converges a.s. to a limit as the number of trees in the forest becomes large. The generalization error of a forest of tree classifiers depends on the strength of the individual trees in the forest and the correlation between them. Using a random selection of features to split each node yields error rates that compare favorably to Adaboost (Y. Freund & R. Schapire, Machine Learning: Proceedings of the Thirteenth International conference, ***, 148–156), but are more robust with respect to noise. Internal estimates monitor error, strength, and correlation and these are used to show the response to increasing the number of features used in the splitting. Internal estimates are also used to measure variable importance. These ideas are also applicable to regression.]]>
The random subspace method for constructing decision forests
[J].
中国非常规油气资源与勘探开发前景
[J].
Unconventional hydrocarbon resources in China and the prospect of exploration and development
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}