
0 引言
地质系统的复杂性常导致地球化学信息表现出模糊性与非线性,而神经网络在处理该类问题方面具有明显的优势。相比于水系沉积物,残坡积土壤的化学成分受物质运移、混合等因素的影响相对较小。因此,采用残坡积土壤化学成分识别基岩类型也是提高浅覆盖区地质填图质量的有效途径之一[8]。王大勇等利用BP神经网络模型对残坡积物覆盖的未知地质体进行了识别,取得了良好的效果[9]。郝立波等采用概率神经网络模型对1:25万多目标地球化学调查土壤数据进行了分析处理,在此基础上对第四系沉积物进行了识别分类,同样取得了良好的效果[10]。为了研究残坡积土壤对浅覆盖区基岩类型识别的可行性,笔者系统采集了大兴安岭北部阿龙山地区不同类型的火山岩及对应的上覆残积土壤样品,尝试采用神经网络模型建立土壤化学成分与基岩类型的关系,识别基岩岩石类型。通过对多种神经网络分类模型效果的对比研究,提出了利用土壤化学成分识别基岩岩石类型的多层感知器神经网络分类模型,以期为提高浅覆盖区地质填图质量提供一种有效的方法。
1 方法原理
1.1 多层感知器神经网络模型
多层感知器神经网络模型由输入层、隐藏层和输出层构成(图1),其中,X1、X2…Xn是输入;F是非线性激活函数;Y1、Y2…Yn是输出,可根据实际情况确定输出个数;W0、W1、W2…Wn是权重;bias是偏置。权重在初始时是随机分配的,偏置通常设为1。输入层、隐藏层、输出层之间连接的每一条线都有权重分配。
图1
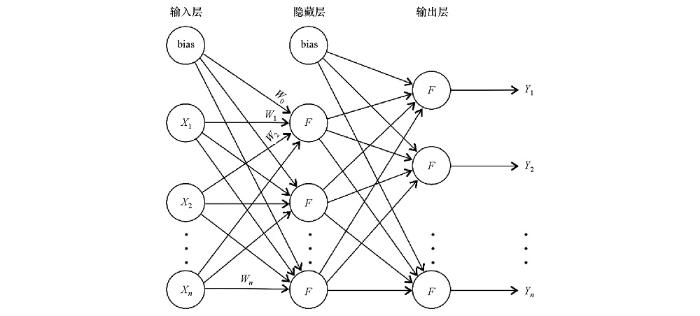
当样本和期望都已知时,称作有监督的训练模式,这时样本从输入层传入,经隐藏层传递到输出层。若实际输出与期望值不符,可将误差通过反向传播算法传递回输入层,调整权重。如此反复,直到符合期望,模型建立完成[11]。本例中,隐藏层的激活函数为
式中x为输入值,经过公式处理后向下一层传递。激活函数种类繁多,如Sigmoid函数、双曲正切函数等,实际应用中可根据实际情况进行选择。地球化学数据间多存在非线性关系,激活函数可把非线性关系引入模型。
建立土壤化学成分与基岩岩石类型对应关系的多层感知器神经网络模型是将岩石类型已知的土壤样本作为训练样本进行学习,得到一个基岩岩石分类标准模型。标准模型的建立是基于神经网络的非线性分类能力。标准模型建立后,可将未知土壤样本数据输入模型进行准确识别,以确定所属岩石类型。
1.2 土壤样本数据归一化处理
为了消除土壤地球化学数据量纲不一致的影响,在进行神经网络运算之前,需要将数据进行归一化处理。数据归一化处理的公式为
式中:xi为土壤元素i的测量值,xi,min为所有土壤样本中元素i的最小值,xi,max为所有土壤样本中元素i的最大值,yi为经过归一化处理后的值。
1.3 分类元素选取原则
分类元素应选择可以反映岩性变化(在不同岩石类型中含量差异大)、在表生作用中活动能力弱,且受矿化程度影响小的常量及微量元素。在实际应用中可选取常量元素和亲石微量元素,如SiO2、Al2O3、Fe2O3、FeO、CaO、MgO、Na2O、K2O、Li、Rb、Be、Sr、Ba、V、Ti、Sc、Cr及Zr等。例如Fe2O3、FeO、MgO、Cr等富集于超基性岩中;CaO、Ti、V、Sc等富集于基性岩中;SiO2、Na2O、K2O、Li、Rb、Be、Sr等富集于酸性岩中。
1.4 算法的实现
算法的实现主要在于建立土壤化学成分及其对应基岩岩石类型间的关系。首先,将土壤化学成分数据进行归一化处理;随后,选取一部分岩石类型已知的土壤样本作为训练样本,一部分作为预测样本;然后,将归一化后的训练土壤样本地球化学数据输入多层感知器神经网络模型中,通过神经网络的自我学习得到一个分类模型,当分类模型对训练样本的判别正确率较高时(一般在95%),则认为建立的分类模型较为合理;最后,使用预测样本检验模型的泛化能力,当泛化能力较强时,可以判断模型是有效的。
2 实际应用
2.1 研究区概况
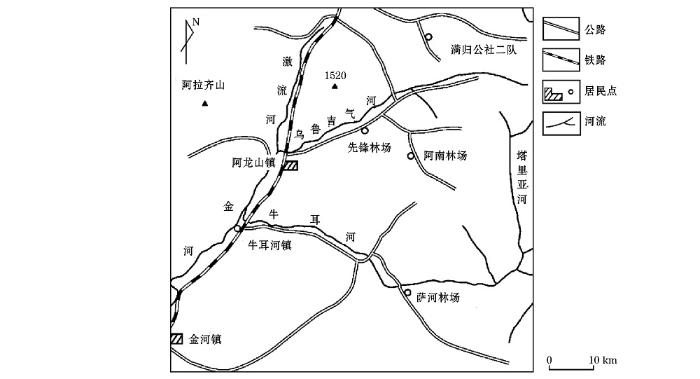
研究区位于大兴安岭以北的阿龙山地区(图2),大地构造位置上属于中亚造山带东部额尔古纳地块与兴安地块的结合带,地势北高南低,属于中低山地形地貌。研究区气候属于寒温带大陆性气候,夏季短暂,温暖湿润,而冬季漫长,寒冷干燥。研究区内永久冻土较为发育。研究区内主要发育中生代火山岩,岩石风化以物理风化为主,化学风化较弱。火山岩风化形成的土壤中含有大量的石英、长石和云母等矿物。研究区覆盖严重,基岩露头少。
图2
2.2 样品采集与分析
土壤样品及对应的基岩样品取自阿龙山地区公路附近的中生代火山岩分布区。样品采样点均布置于地形较平坦的山腰或半山腰处,以保证土壤样品为残积物。采用人工点槽方式采样,采集B层土壤样品167件及其对应下伏基岩样品167件。
土壤样品按照土壤地球化学测量规范处理,自然风干后,去除植物根系和岩石碎屑等杂物。岩石与土壤样品均粉碎至粒径小于200目(74 μm)。样品分析由吉林大学测试科学实验中心完成。分析项目共23项,包括常量元素SiO2、Al2O3、TFe2O3、K2O、Na2O、CaO、MgO和微量元素Ti、Mn、P、Cu、Pb、Zn、Co、Ni、V、Rb、Sr、Ba、Nb、Zr、Y、Th。氧化物和微量元素含量均采用粉末压片X射线荧光光谱法测试。主要分析步骤如下:用粉碎机将样品研磨至200目以下,经充分混匀后准确称取4.00 g,采用硼酸镶边垫底,在30 MPa压力下压制成直径为40 mm的样片,然后采用X射线荧光光谱仪进行测试。测试过程中采用国家标准样进行质量监控。常量元素分析相对误差小于5%,微量元素分析相对误差小于10%。
2.3 神经网络分类模型构建
2.3.1 分类元素的确定
在选取分类元素的过程中,首先剔除了可能受矿化影响的Cu、Pb、Zn等元素,然后,选择能够充分反映岩性变化的常量及微量元素。经多次实验,确定了SiO2、TFe2O3、CaO、MgO、Na2O、K2O、Ti、Co、Ni、V、Rb、Sr、Ba、Nb作为分类元素,并对其含量进行了归一化处理,作为神经网络分类模型的输入值。
2.3.2 激活函数的选择
在隐藏层中,常用的激活函数有双曲正切函数和Sigmoid函数。对比了这两种激活函数的应用效果,结果表明应用双曲正切函数时的样本预测正确率明显高于Sigmoid函数。因此,隐藏层中的激活函数选取了双曲正切函数。输出层的激活函数选择了适合于多分类问题的Softmax函数。
2.3.3 算法的选择
在分类模型的构建过程中,算法通常有标度共轭梯度法、梯度下降法和集成算法(如Boosting算法、Bagging算法等)。实验表明,集成算法在精度上明显优于标度共轭梯度法和梯度下降法,且以Boosting算法的精度最高,因此本文选择了Boosting算法。
2.3.4 构建模型及识别结果
表1 阿龙山地区岩石分析结果统计
| 指标 | 玄武岩类(n=21) | 安山岩类(n=47) | 英安岩类(n=38) | 流纹岩类(n=61) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 最小值 | 最大值 | 平均值 | 最小值 | 最大值 | 平均值 | 最小值 | 最大值 | 平均值 | 最小值 | 最大值 | 平均值 | |
| SiO2 | 43.04 | 53.82 | 49.38 | 54.12 | 66.90 | 60.60 | 67.04 | 71.78 | 69.22 | 72.09 | 86.25 | 75.52 |
| Al2O3 | 10.21 | 19.24 | 15.95 | 13.82 | 18.78 | 16.63 | 12.64 | 17.83 | 15.83 | 8.77 | 16.03 | 13.26 |
| TFe2O3 | 6.36 | 20.50 | 10.26 | 3.23 | 9.54 | 5.81 | 1.85 | 6.83 | 3.23 | 0.96 | 3.31 | 1.79 |
| K2O | 0.65 | 3.72 | 1.84 | 1.36 | 7.12 | 3.60 | 2.17 | 7.01 | 4.50 | 0.18 | 7.16 | 4.38 |
| Na2O | 1.71 | 4.07 | 3.05 | 1.37 | 7.22 | 4.14 | 0.58 | 5.93 | 4.00 | 0.17 | 8.38 | 3.76 |
| CaO | 1.43 | 12.64 | 5.92 | 0.13 | 6.01 | 2.63 | 0.10 | 3.66 | 0.74 | 0.07 | 17.0 | 0.53 |
| MgO | 1.08 | 16.72 | 4.86 | 0.27 | 6.29 | 2.01 | 0.09 | 2.00 | 0.70 | 0.03 | 0.85 | 0.31 |
| Ti | 2248 | 29451 | 10552.7 | 2699 | 9704 | 5938.4 | 1460 | 4565 | 3170.2 | 474 | 3503 | 1536.3 |
| Mn | 555 | 3131 | 1404.3 | 402 | 2588 | 939.2 | 230 | 2052 | 809.5 | 93.8 | 1439 | 475.8 |
| P | 173 | 4922 | 2083.3 | 211 | 3155 | 1613.0 | 138 | 1514 | 726.7 | 62.4 | 797 | 242.9 |
| Cu | 0.52 | 63.6 | 22.2 | 0.48 | 69.6 | 14.8 | 0.70 | 8.63 | 21.6 | 0.18 | 13.1 | 2.9 |
| Pb | 2.85 | 31.0 | 11.7 | 1.69 | 80.8 | 20.4 | 9.08 | 50.3 | 21.6 | 5.71 | 201 | 28.6 |
| Zn | 59.7 | 100 | 103.6 | 34.2 | 143 | 82.5 | 42.0 | 159 | 67.3 | 18.4 | 105 | 49.1 |
| Co | 15.6 | 62.0 | 36.3 | 4.26 | 33.2 | 17.6 | 0.21 | 13.3 | 6.99 | 0.02 | 9.10 | 2.93 |
| Ni | 2.42 | 102 | 33.25 | 1.05 | 55.8 | 15.79 | 2.03 | 20.7 | 6.32 | 1.98 | 28.40 | 6.41 |
| V | 123 | 414 | 236.2 | 9.22 | 181 | 104.5 | 6.90 | 74.6 | 26.5 | 2.49 | 42.7 | 15.5 |
| Rb | 13.1 | 139 | 59.0 | 21.9 | 294 | 108.9 | 53.6 | 214 | 119.0 | 1.46 | 272 | 141.1 |
| Sr | 128 | 1525 | 570.1 | 20.2 | 1892 | 557.8 | 14.0 | 743 | 249.3 | 9.85 | 336 | 83.2 |
| Ba | 71.7 | 1793 | 625.0 | 122 | 2325 | 945.9 | 119 | 1655 | 933.6 | 48.5 | 1483 | 557.4 |
| Nb | 0.96 | 20.8 | 12.0 | 0.83 | 68.6 | 12.8 | 2.82 | 77.2 | 20.1 | 0.83 | 94.6 | 19.4 |
| Zr | 23.1 | 322 | 193.9 | 85.2 | 1649 | 286.2 | 190 | 1157 | 382.4 | 85.4 | 655 | 257.0 |
| Y | 5.81 | 43.5 | 20.6 | 7.87 | 74.4 | 17.8 | 9.1 | 99 | 25.5 | 3.34 | 129 | 19.4 |
| Th | 0.46 | 12.7 | 6.64 | 1.52 | 28.5 | 14.16 | 8.61 | 37.60 | 19.27 | 4.95 | 39.1 | 24.12 |
注:n为样本数;TFe2O3为全铁分析结果;氧化物质量分数单位为10-2,微量元素质量分数单位为10-6
表2 阿龙山地区基岩上覆土壤分析结果统计
| 指标 | 玄武岩类(n=21) | 安山岩类(n=47) | 英安岩类(n=38) | 流纹岩类(n=61) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 最小值 | 最大值 | 平均值 | 最小值 | 最大值 | 平均值 | 最小值 | 最大值 | 平均值 | 最小值 | 最大值 | 平均值 | |
| SiO2 | 47.70 | 70.05 | 61.09 | 46.88 | 71.64 | 63.83 | 56.74 | 76.30 | 67.53 | 59.13 | 79.58 | 67.83 |
| Al2O3 | 13.89 | 18.82 | 15.90 | 12.08 | 18.50 | 15.52 | 10.10 | 17.37 | 14.77 | 11.03 | 18.85 | 15.15 |
| TFe2O3 | 4.45 | 11.33 | 7.37 | 3.80 | 8.69 | 5.65 | 2.18 | 10.38 | 4.86 | 2.32 | 6.71 | 4.27 |
| K2O | 1.34 | 2.98 | 2.17 | 1.46 | 3.98 | 2.63 | 1.62 | 4.14 | 2.67 | 1.72 | 5.69 | 2.91 |
| Na2O | 1.04 | 2.57 | 1.64 | 1.22 | 3.26 | 1.98 | 0.92 | 3.22 | 1.69 | 0.48 | 4.90 | 1.77 |
| CaO | 0.59 | 5.19 | 1.49 | 0.55 | 4.95 | 1.30 | 0.50 | 1.93 | 0.82 | 0.32 | 1.54 | 0.63 |
| MgO | 0.85 | 4.90 | 2.01 | 0.69 | 4.24 | 1.49 | 0.41 | 1.95 | 1.01 | 0.42 | 1.75 | 0.89 |
| Ti | 4811 | 11009 | 6908.5 | 4007 | 9939 | 5909.7 | 3803 | 7562 | 5457.9 | 1349 | 7901 | 4685.8 |
| Mn | 392 | 2515 | 966.0 | 269 | 2433 | 853.6 | 280 | 5625 | 919.9 | 219 | 4432 | 687.9 |
| P | 368 | 2971 | 864.7 | 315 | 3052 | 961.5 | 285 | 2560 | 768.7 | 152 | 1177 | 507.3 |
| Cu | 5.64 | 62.0 | 18.3 | 6.32 | 31.8 | 15.7 | 4.10 | 21.8 | 10.5 | 1.62 | 50.3 | 10.1 |
| Pb | 8.78 | 37.7 | 21.3 | 3.14 | 125 | 26.4 | 4.43 | 127 | 26.0 | 6.53 | 338 | 35.3 |
| Zn | 69.6 | 189 | 113.2 | 44.4 | 162 | 98.9 | 57.1 | 494 | 115.0 | 48.7 | 736 | 112.9 |
| Co | 10.4 | 34.3 | 21.9 | 8.8 | 60.5 | 18.2 | 6.33 | 22.5 | 13.0 | 0.54 | 17.7 | 10.1 |
| Ni | 2.56 | 62.4 | 21.5 | 2.51 | 33.9 | 17.2 | 4.60 | 1403 | 52.2 | 3.43 | 33.8 | 14.7 |
| V | 60.6 | 380 | 141.1 | 18.0 | 164. | 97.6 | 31.5 | 128 | 75.2 | 14.4 | 113 | 65.1 |
| Rb | 62.8 | 143 | 103.8 | 52.1 | 201 | 116.3 | 11.0 | 165 | 118.1 | 61.2 | 221 | 128.8 |
| Sr | 119 | 431 | 233.0 | 141 | 884 | 306.5 | 66 | 384 | 178.5 | 34 | 268 | 131.6 |
| Ba | 471 | 704 | 600.7 | 475 | 964 | 658.3 | 444 | 1006 | 662.9 | 108 | 997 | 579.9 |
| Nb | 7.40 | 36.3 | 18.8 | 2.16 | 64.3 | 20.2 | 8.53 | 56.5 | 21.1 | 9.12 | 55.9 | 22.1 |
| Zr | 95.5 | 430 | 263.3 | 180 | 371 | 277.8 | 167 | 978 | 309.8 | 190 | 589 | 309.9 |
| Y | 5.52 | 45.0 | 21.2 | 9.85 | 41.2 | 18.9 | 12.8 | 54.2 | 22.6 | 12.6 | 43.2 | 21.1 |
| Th | 0.61 | 19.1 | 10.6 | 1.95 | 28.1 | 12.4 | 2.27 | 35.3 | 12.5 | 5.86 | 21.8 | 14.1 |
注:n为样品数,TFe2O3为全铁分析结果,氧化物质量分数单位为10-2,微量元素质量分数单位为10-6
随机选取97件土壤样品作为训练样本,其余70件样品作为预测样本,其中,玄武岩类土壤训练样本15件,安山岩类土壤训练样本30件,英安岩类土壤训练样本22件,流纹岩类土壤训练样本30件。然后对挑选出的分类元素的含量进行归一化处理,并将归一化后的值作为多层感知器神经网络模型的输入值,采用Bootsing算法进行计算。计算结果表明,分类结果与实际岩石类型重合率为100%。
随后,将70件土壤预测样本数据输入建立的分类模型中,计算结果显示预测正确率达到了90%,其中玄武岩类正确率为100%,安山岩类为94%,英安岩类为100%,流纹岩类为84%,说明该神经网络模型具有较强的泛化能力,可以用于浅覆盖区火山岩基岩岩石类型识别。
3 讨论
在多层感知器神经网络分类模型构建过程中,选择不同的分类元素,采用不同的激活函数和算法都会对模型的效果产生较大影响。笔者详细对比研究了不同分类元素、不同激活函数及不同算法对模型分类结果的影响。
在分类模型运算过程中,有些元素的缺失会影响分类效果,如CaO、TFe2O3等。去除CaO后,模拟输出重合率虽然也是100%,但模型对预测样本的判别正确率却只有63%,泛化能力较差,因此不宜舍弃CaO。对于TFe2O3,当不选取TFe2O3时,在分类中会把一个安山岩样本和一个流纹岩样本错误地识别为英安岩,使训练样本的模拟输出重合率降为90%,还会使预测样本的判别正确率降为60%,说明TFe2O3对样本的分类起重要影响,也不宜舍弃。而有些元素选用后反而会降低模型的分类能力,如Al2O3、Cu、Pb、Zn等。分析表明,Al2O3在各类岩石中的含量变化较小,在分类中没有起到重要的作用,因此不宜选用。对于Cu、Pb、Zn等可能会受矿化影响的元素,会影响基岩分类,因此也不宜选用。
选择不同的算法,对模型的应用效果也有较大的影响。当选择Boosting算法时,模型的应用效果较好。该算法的基本思想是先用不同的分类方式对目标进行分类,形成多个基本模型,然后调整其中错误项的权重,最后将调整后的子模型整合形成分类模型[17]。而其他算法的应用效果稍差,如标度共轭梯度法的模拟输出重合率为67%,预测样本正确率为71%;梯度下降法的模拟输出重合率为81%,预测样本正确率为76%。在集成算法中,Bagging算法的模拟输出重合率也较高,达到了91%,但其预测样本正确率却只有64%。Bagging算法为了保证采样的均匀性,采取了随机取样方式,不同于Boosting算法的根据错误率取样方式。通常情况下,Bagging算法虽然缩短了训练时间,但分类精度要低于Boosting算法[18,19]。但在某些数据集中的样本中,采用Bagging算法的分类效果可能要好于Boosting算法,因此还需根据实际情况进行具体判断。
综上所述,在实际应用中应根据实际情况进行多次试验,确定最优分类元素、激活函数及分类算法,进而得到最优分类模型。
4 结论
1) 基于土壤化学成分建立的多层感知器神经网络模型对大兴安岭浅覆盖区火山岩基岩类型有很好的识别能力,利用土壤化学成分识别基岩类型是可行的。
2) 多层感知器神经网络模型具有训练快捷、使用方便、正确率高等优点,能较好地处理非线性对应关系,对提高浅覆盖区地质填图的精度有重要意义。
3) 不同激活函数、不同算法和分类元素的选择都会对多层感知器神经网络分类模型的效果产生影响。在使用过程中需要反复试验,确定最优分类模型。
参考文献
区域化探在森林沼泽区地质填图应用初探
[J].
DOI:10.3969/j.issn.1000-8918.2004.03.006
URL
Magsci
[本文引用: 1]

<p>通过对大兴安岭浅覆盖区1:20万小二沟幅区域化探特征元素Fe、Mg、Si、K、Sb、Hg、U等地球化学背景场分布规律的研究,对浅覆盖区地质体界线、断裂、隐伏岩体等基础地质问题进行了有益的探讨。经野外验证,在该区应用区域化探特征元素研究基础地质问题是有效的。而且对今后在浅覆盖区开展区域地质填图和提高地质填图质量、速度都将发挥重要作用。</p>
利用水系沉积物地球化学数据判别浅覆盖区岩性与构造—欧氏距离法
[J].
DOI:10.3969/j.issn.1001-1749.2004.03.013
URL
[本文引用: 1]
针对浅覆盖区地质调查困难,缺少可对比已知资料的实际问题,这里以大兴安岭阿龙山地区1:250 000水系沉积物资料为例,给出了浅覆盖区岩性和构造识别的一种方法.该方法依据水系沉积物对原岩的继承性,以不同岩性所对应的典型土壤为已知样品,采用欧氏距离作为分类指标,将研究区划分为不同的岩性类.得到的区域地球化学分类图反映了一定的岩性分布及构造特点,为区域地质调查提供了线索.
Semi-hierarchical correspondence cluster analysis and regional geochemical pattern recognition
[J].
DOI:10.1016/j.gexplo.2006.10.002
URL
[本文引用: 1]
Semi-hierarchical correspondence cluster analysis (SHCCA), firstly developed in this paper, extracts the main advantages of correspondence analysis, hierarchical and non-hierarchical cluster analysis, and unifies the R- and Q-mode cluster analysis of large data set. A systemic program to recognize the regional geochemical patterns is built up based on this method. With this program, the complex tasks for data interpretation can be achieved by simple processes, and important geochemical information can be displayed by a single diagram, i.e. the multivariate regional geochemical image. As one of the applied examples of this program, the regional geochemical pattern recognition for a shallow covered area around Tahe in Heilongjiang Province is introduced. The results show that many hidden geochemical patterns related to the lithologies, structures, ore-forming conditions and prospecting targets etc are revealed by the geochemical image, and that the main geochemical patterns are related with certain geological and gravitational patterns. By finding contrasts between geochemical patterns and geological or gravitational patterns, the SHCCA results assist the geological mapping in this area. Geochemical data obtained in Chinese regional geochemical exploration provides useful information regarding geology and minerals, and the method described in this paper provides a new way to examine this type of resource.
区域化探数据在浅覆盖区地质填图中的应用方法研究
[J].
DOI:10.3969/j.issn.1000-3657.2007.04.022
URL
[本文引用: 1]
区域化探数据包含丰富的地质信息,可用于浅覆盖区区域地质填图。笔者系统研究了浅覆盖区水系沉积物化学成分与基岩化学成分的关系,利用水系沉积物氧化物成分,以区域岩石化学成分为约束,提出了基岩化学成分推断方法;根据水系沉积物与其矿物化学成分间质量平衡关系,提出了基岩矿物组成推断方法。在此基础上提出了地球化学推断地质图的编制方法,并在典型森林-沼泽浅覆盖区进行了试验,地质调查和钻探工程验证了该方法的有效性。充分利用区域化探资料,提取地质填图信息,是提高浅覆盖区地质填图质量的有效途径。
因子分类法在黑龙江塔河地区地质填图中的应用
[J].
DOI:10.3969/j.issn.1671-5888.2008.05.030
URL
[本文引用: 1]
利用因子分类法在黑龙江塔河地区进行地球化学单元识别,根据各单元的理论地球化学意义及其与地质单元的对应关系,进行浅覆盖区地质填图研究。充分提取区域化探资料中的地球化学信息,将研究区识别为具有特定地质、地球化学意义的5个地球化学单元。其中:Be、Nb、Sn、Y、Rb单元主要反映研究区古生代花岗岩和中生代酸碱性火山岩的分布;Co、TFe、Cr、Ni、V、Ti、MgO单元主要反映研究区早元古代侵入岩、变质岩和古生代基性岩体的分布;SiO2、K2O、Na2O单元反映的地质单元主要为古生代侵入岩、中生代酸碱性火山岩和沉积岩;Al2O3、Li、F单元主要反映中生代火山岩的分布;CaO、Sr、Ba单元反映的是中生代沉积岩,可能与生物沉积作用有关,代表比较稳定的沉积环境。同时,根据不同单元的分布形态和边界走向,识别和推断了研究区的北东、北西、南北及东西向断裂构造。
Origin of skewed frequency distribution of regional geochemical data from stream sediments and a data processing method
[J].DOI:10.1016/j.gexplo.2018.07.007 URL [本文引用: 1]
化探资料在地质填图中的应用
[J].
DOI:10.11720/wtyht.2015.3.03
URL
Magsci
[本文引用: 1]
<p>根据多年工作实践,总结了应用土壤地球化学资料解决基础地质问题的实例,其中包括判断下覆岩性、圈定构造、地层对比划分等问题,阐述了在解决地质问题中的地球化学原理和应用条件,介绍了如何利用残积晕在浅覆盖区、干旱草原区、热带雨林区扩大地质填图的基岩出露面积,识别推断下覆地层岩性;通过残积晕和上置晕推断隐伏构造;通过地球化学建造晕进行地层划分和对比。认为在矿产地质调查中充分利用地质调查区的化探资料,是可以提高地质填图质量的,并有助于解决常规地质工作中遇到的问题。地质与化探的结合也可以提高化探异常的地质解释能力。</p>
人工神经网络在识别浅覆盖区地质体中的应用
[J].利用水系沉积物资料识别浅覆盖区地质体,对于提高区域地质填图质量具有重要意义。神经网络为解决此问题提供了新的途径。依据浅覆盖区基岩和其对应的水系沉积物在化学成分上的继承关系,以内蒙古四子王旗浅覆盖区为例,阐述了运用BP神经网络模式识别地质体的原理和方法,并识别出了化学成分相近的浅覆盖层下地质体。该方法可广泛应用于浅覆盖区地质填图。
利用多目标地球化学数据识别第四纪沉积物类型——基于概率神经网络方法
[J].
DOI:10.3969/j.issn.1671-5888.2008.06.029
URL
[本文引用: 1]
针对利用多目标地球化学数据研究第四纪沉积物类型问题,提出了基于概率神经网络的分类识剐模 型,井给出地球化学特征指标选取、指标归一化、神经网络设置和训练的具体方法、步骤。在吉林省中西部松嫩平原应用表明,该方法识别出8类不同成因的第四纪 沉积物,较好地解决了该区第四纪沉积物成因归属问题。概率神经网络模型对第四纪沉积物类型的识别能力远高于常规多元统计方法,且结构简单、训练快捷。
浅覆盖区土壤化学成分与基岩化学成分的关系及其意义——以大兴安岭北部地区为例
[J].
DOI:10.3969/j.issn.1000-3657.2005.03.018
URL
[本文引用: 2]
以大兴安岭北部地区为例,研究了浅覆盖区土壤与基岩化学成分的关系。指出浅覆盖区残积型土壤主要造岩元素组合继承了基岩元素组合特征;在岩石风化成土过程中,元素再分配和迁移使土壤中大多数元素(氧化物)含量产生明显的“均一化”。在此基础上,对土壤地球化学异常的识别与评价问题进行了讨论并提出了建议。
神经网络信息传输函数Sigmoid与tanh比较论证
[J].
DOI:10.3963/j.issn.2095-3844.2004.02.044
URL
[本文引用: 1]
人工神经网络中的信息传输函数采用Sigmoid函数,但这种函数存在缺陷,为克服其不足,在构建的神经网络计算机中央处理器利用率的系统中采用tanh函数取代Sigmoid函数.实践证实tanh函数的采用,提高了计算机中央处理器利用率的预测精确度.
Neural network approaches for prediction of pistachio drying kinetics
[J].
Boosting using neural networks
[G]//
集成学习: Boosting算法综述
[J].
DOI:10.3969/j.issn.1003-6059.2004.01.010
URL
[本文引用: 1]
Boosting是近年来机器学习领域中一种流行的、用来提高学习精度的算法,本文首先以AdaBoost为例对Boosting算法进行简单的介绍,并对Boosting的各种不同理论分析进行概括,然后介绍了Boosting在回归问题中的理论研究,最后对Boosting的应用以及未来的研究方向进行了讨论。

{kind=link}
{kind=link}
{kind=link}
{kind=link}