{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
利用自组织特征映射神经网络和K-means聚类算法挖掘区域化探数据中的地质信息
引用本文
陈军林, 彭润民, 李帅值, 陈喜财. 利用自组织特征映射神经网络和K-means聚类算法挖掘区域化探数据中的地质信息[J]. 物探与化探, 2017,41(5): 919-927.
CHEN Jun-Lin, PENG Run-Min, LI Shuai-Zhi, CHEN Xi-Cai. Self-organizing feature map neural network and K-means algorithm as a data excavation tool for obtaining geological information from regional geochemical exploration data[J]. Geophysical and Geochemical Exploration, 2017,41(5): 919-927.
Doi:10.11720/wtyht.2017.5.19
Permissions
CHEN Jun-Lin, PENG Run-Min, LI Shuai-Zhi, CHEN Xi-Cai. Self-organizing feature map neural network and K-means algorithm as a data excavation tool for obtaining geological information from regional geochemical exploration data[J]. Geophysical and Geochemical Exploration, 2017,41(5): 919-927.
Doi:10.11720/wtyht.2017.5.19
Copyright©2017, 物探与化探编辑部
《物探与化探》编辑部
利用自组织特征映射神经网络和K-means聚类算法挖掘区域化探数据中的地质信息
作者简介: 陈军林(1988-),男,博士研究生,研究方向为矿产资源勘查与评价。
摘要
区域化探数据包含丰富的地质信息,从区域化探数据中挖掘出这些信息,对于区域地质研究具有重要意义。笔者提出了一种利用自组织特征映射网络和K-means聚类算法挖掘区域化探数据中地质信息的方法,将标准化之后的元素含量数据作为模型输入值,通过自组织神经网络进行聚类,再通过K-means算法进行二次聚类,从聚类结果中分析其中包含的地质信息。以英格兰西南部某区水系沉积物区域化探数据为例,进行实例研究以检验该方法的实际效果。实例结果表明:①利用该方法得出的聚类结果图很好地响应了地质体的空间分布,可用于推断地质体的分布特征;②地质信息隐藏在每个聚类类型的地球化学特征之中,通过对这些特征进行分析和解释,可以挖掘出其中所包含的信息;③基于SOM网络和K-means聚类的区域化探数据挖掘方法是一种有效的地质信息获取方法,对于传统区域地质研究可以起到补充和增强的作用。
关键词:
区域化探; 自组织特征映射; K-means; 聚类分析; 地质信息; 数据挖掘
中图分类号:P632
文献标志码:A
文章编号:1000-8918(2017)05-0919-09
Self-organizing feature map neural network and K-means algorithm as a data excavation tool for obtaining geological information from regional geochemical exploration data
Abstract
Regional geochemical data contain abundant geological information.The excavation of useful information from regional geochemical data is of important significance for the study of regional geology.In this paper,a model based on the self-organizing feature map and K-means algorithm is applied as a data excavation tool to discover hidden geological information from regional geochemical exploration data.For each data point,the raw data of each element is transformed by data normalization as the input value of the model.By means of SOM clustering and K-means clustering as the second step,the input data points can be divided into different groups,and then geological information can be acquired by analyzing the clustering results.Stream sediment survey data from southwest England is used as an example to test the performance of this model.The case study results demonstrate that:First,the clustering maps generated by the model agree well with the geological spatial distribution pattern.Accordingly,they can be used to predict the spatial distribution of geological bodies;Second,geological information is concealed in each cluster member.By analyzing and interpreting these geochemical characteristics, the geological information concealed in geochemical data can be discovered;Third,regional geochemical data excavation approach based on SOM network and K-means clustering is an effective geological information acquisition method,which can be used as a supplementary and strengthening way for conventional regional geology research.
Keyword:
regional geochemical exploration; self-organizing feature map; K-means; cluster analysis; geological information; data excavation
0 引言
区域地球化学数据包含丰富的地质信息, 而元素空间分布与地质体空间分布有一定的对应关系, 因此可以利用区域地球化学数据推断地表或近地表地质体的空间分布情况及其地质特征[1]。与传统的通过地质调查获取地质体信息的方法相比, 利用区域地球化学数据推断地质体的方法不受露头情况限制, 而且取得的数据与地质体成分变化直接相关, 对地质体成分变化敏感, 可以很好地反映地质体地球化学特征的空间变化。因此, 区域化探数据在覆盖区填图等方面可以发挥重要作用, 在推断和解释区域地质信息方面有一定的优势, 可以作为地质方法的重要补充。基于此, 很多学者应用区域地球化学数据研究基础地质问题, 如地质填图、地层划分、断层识别等[2,16]。
区域化探数据一般都涉及到几十个元素, 为了更好地挖掘出区域化探数据中的地质信息, 需要考虑多个元素变量, 进行多元统计分析。聚类分析是常用的多元统计分析方法, 在化探数据处理中应用较多 [17,21], 常用的聚类算法有层次聚类、K-means聚类、DBSCAN聚类等, 不同聚类方法的输出结果可能差别很大[22], 选择合适的聚类方法是聚类成功的关键。自组织特征映射(self-organizing feature map, SOM)神经网络是一种非常有效的聚类分析算法, 它是由大量简单的神经元广泛互连形成的复杂非线性系统, 具有很强的自学习、自组织、自适应和非线性映射能力, 特别适用于像化探数据处理这样的因果关系复杂的非线性推理、识别和分类问题。但SOM神经网络无法根据事先指定的精确聚类个数进行聚类, 通过与K-means算法结合起来使用可以克服这个问题, 实现更好的聚类效果。基于此, 笔者提出了利用SOM神经网络和K-means聚类算法挖掘区域化探数据中地质信息的方法, 根据数据点的多元素化探特征将区域化探数据聚成不同的类, 再通过每个类型的地球化学特征探讨各类型的地质类型和地质特征, 并通过实例验证该方法的实际效果, 以探讨该方法在化探数据挖掘中的优势和局限性。
1 方法原理介绍
1.1 自组织特征映射神经网络
自组织特征映射神经网络(简称SOM神经网络)是一种无监督神经网络模型, 由芬兰Helsinki 大学的Teuvo Kohonen于1981年提出[23]。通过自组织映射将高维数据映射到低维, 从而将数据根据其特征相似程度聚集到不同的离散区域, 实现降维和聚类。由于该算法与人脑的自组织特性相类似, 能够通过输入样本自动检测其中的规律以及输入样本之间的关系, 并且根据这些输入样本的信息自适应调整网络, 使网络以后的响应与输入样本相适应, 因此称之为“ 自组织” 神经网络。
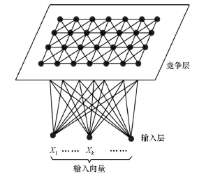
SOM神经网络由节点(又称神经元)构成, 连接它们的是权向量。如图1所示, 网络具两层结构, 下层为输入层, 由输入结点构成, 若输入向量有n个维度, 则输入端共有n个结点, 输入层接受外界信息, 并传递给竞争层; 网络上层为竞争层(输出层), 由输出结点(假设为m个)构成, 按二维形式排成一个等间距的结点矩阵, 每个节点对应一个BMU(最佳匹配节点)向量, 代表一类具有相似特征的数据点集群。竞争层负责对输入模式进行“ 分析比较” , 寻找规律并归类。所有输入结点到输出结点都有权值连接, 输出层的每个神经元同它周围的其他神经元侧向连接。
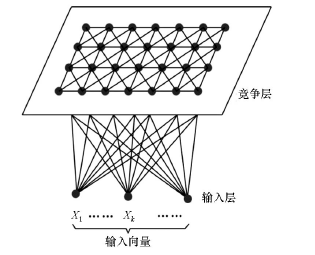 | 图1 SOM神经网络结构 |
当SOM神经网络接收到一个外界输入时, 将自动分为不同的区域, 各区域将自动对输入信息产生不同程度的响应[24]。这种响应会在输出层神经元之间发生竞争, 响应最强烈的神经元为获胜神经元, 又称最佳匹配节点(best matching unit, BMU), 根据BMU即可确定输入样本对应的聚类类型。获胜神经元对其邻近神经元的影响由近及远, 较邻近的神经元互相刺激, 较远的神经元相互抑制。每输入一个样本之后都要对获胜神经及其周围神经元节点的权值进行调整以更加接近输入权值。经过反复的输入训练样本调整网络权值, 稳定后的网络输出就对输入模式生成自然的特征映射, 从而达到自动聚类的目的。
SOM神经网络算法通过R语言程序包“ kohonen” [25]进行具体运算。要构建合适的SOM模型, 首先要确定合理的映射网络形状和尺寸。网络形状分为对称型和不对称型, 不对称型一般不容易受“ 边界效应” (boundary effects)的影响[23]。选择合适的网络尺寸是取得好的聚类效果的关键[26], 通常可根据QE和 TE两个指标来评价网络尺寸选择的优劣[27], 从而确定出最佳映射网络尺寸。QE是量化误差(quantization error), 是每一个数据向量到最佳匹配节点(BMU)的距离平均值, 即数据向量与BMU向量的平均相似程度[28, 29]。TE是拓扑误差(topographic error), 描述的是所有数据向量到第一和第二匹配节点的比率, 用来表示映射过程中维护拓扑结构的精度[30]。此外还需要确定迭代次数、学习率, 邻域半径(radius)等几个重要参数。
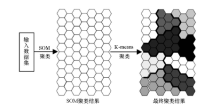
1.2 K-means算法和SOM-K聚类模型
通过SOM聚类得出的BMU个数即为聚类个数, SOM聚类无法像K-means算法那样直接根据指定的聚类个数进行聚类, 而且SOM聚类结果的个数往往较大, 所以还需要进一步聚类。通常可用层次聚类、K-means聚类等方法进行再次聚类[31]。K-means聚类是一种经典的聚类算法, 该算法以事先确定的聚类个数k为参数, 把n个待分对象根据相似度分为k个簇(cluster)[32], 以使得簇内的对象具有较高的相似度, 不同簇中对象的相似度较低。相似度的计算根据簇中对象的平均值来进行。
但该方法存在以下缺点:初始聚类中心的选择对聚类结果影响大, 容易陷入局部最优, 对“ 噪声” 和孤立点数据敏感, 这些缺陷大大限制了它的聚类效果[31]。通过将SOM聚类作为K-means聚类的前端, 利用K-means算法对SOM聚类的结果进行二次聚类, 就能够克服上述缺陷, 同时可以实现对样本根据指定聚类个数进行精确划分[45]。这种结合了SOM和K-means算法的聚类模型简称为SOM-K 聚类模型。
使用K-means算法聚类的关键是聚类个数k的确定, 决定最佳聚类个数的方法很多, 通常可用Davies-Bouldin(DB)指数[33]、Xie-Beni指数[34]、Dunn指数等[35]评估聚类结果, 确定聚类个数。本次选用DB确定最佳聚类数, DB通过计算类内距离之和与类间距离之和的比值来优化k值的选择[36], DB越小说明聚类效果越好。
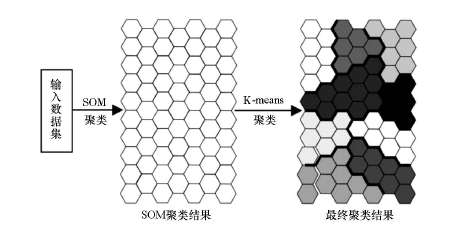 | 图2 SOM-K 聚类模型结构 |
1.3 方法流程
笔者提出的基于SOM和K-means聚类算法挖掘化探数据中地质信息的方法, 具体通过以下步骤实现:
1) 选取合适的元素数据作为输入变量。有些元素无效数据过多, 有些元素受成矿作用和表生作用影响大, 不能如实反映基岩地球化学特征, 对于这类元素要予以剔除, 筛选出能够代表基岩成分特征的元素。
2) 数据标准化。直接以原始数据作为输入数据, 不同元素数据之间往往差别很大, 如主要造岩元素和一些微量元素之间往往差很多倍, 这种数量级的差别会对后续数据处理造成影响, 因此需要进行标准化[22]。具体采用以下公式:
式中, xij为数据点j上元素i的原始含量数据, xi为元素i在整个研究区的含量值, kij为标准化后的值。
3) 通过SOM和K-means算法进行聚类。综合标准化之后的元素含量数据作为输入变量, 选择好参数, 利用R语言“ kohonen” 包和“ cluster” 包进行自组织神经网络聚类和K-means聚类, 从而根据数据点之间的地球化学特征相似程度将数据点划分成不同类型。
4) 对通过聚类划分出的类型根据其地球化学特征进行解释分析和信息挖掘。属于同一聚类类型的数据点具有相近的地球化学特征, 这些地球化学特征包含了丰富的地质信息, 结合相关的地质资料, 对这些地球化学信息进行解释, 将地球化学特征与地质特征联系起来, 挖掘出其中的地质信息。
2 应用实例
2.1 研究区简介及数据说明
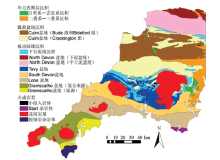
本实例中的水系沉积物测量数据来自于英国地质调查局(British Geological Survey, BGS)G-BASE项目(Geochemical Baseline Survey of the Environment, http://www.bgs.ac.uk/gbase/home.html)公开数据。研究区位于英格兰西南部, 属于华力西造山带(Variscan orogen), 构造演化复杂, 经历了从被动陆缘到碰撞造山再到之后的伸展的多阶段构造运动过程[37]。所有地质单元可归为4类:火成岩类(igneous domains), 被动陆缘沉积(rhenohercynian passive margin sediments), 弧前盆地沉积(carboniferous foreland basin sediments)、华力西期后沉积(post-variscan sediment)。按照岩性、时代、构造演化、沉积盆地边界等进一步划分为16个类型[38], 为了后面方便叙述, 对每个类型采用了简称, 详见表1。
| 表1 英格兰西南部地质单元划分及主要特征[38] |
水系沉积物测量于2002和2012年进行, 采样 3 745 个, 平均2.5 km2一个样, 采样于一级和二级水系, 采集的沉积物粒径小于150 μ m。共测量元素52个, 测试方法为X-射线荧光光谱法(X-ray fluorescence spectrometry), 52个元素数据中公开发布的有27个(表2), 其中Ag、Cd等无效数据(低于检出限) 所占比例较大, 会对后续处理产生不利影响, 对这些元素予以剔除。根据Kirkwood等对52个元素的聚类结果[38], 其中As、Cu、Pb、Sb、Sn、W、Zn等受成矿作用影响大, 由于没有详细的区域矿产资料, 所以笔者不探讨其与成矿作用有关的问题; 而那些容易受成矿作用影响的元素, 会对分析解释带来不便, 根据聚类结果将其剔除; Ca和Sr容易受表生作用的影响, 也予以剔除。最后筛选出与成岩作用关系密切的Ba、Ce、Cr、Hf、Fe、Mn、Mo、Ni、K、Sm、Se、Si、Th、Ti、U、Zr共16个元素用于本次研究。BGS公开数据中提供了这些元素的插值栅格文件, 采用反距离加权插值, 单元格大小为500 m× 500 m。从这些栅格文件中提取出数据, 形成一个由39 197个像素点、16个变量组成的数据集。
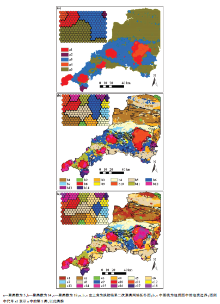
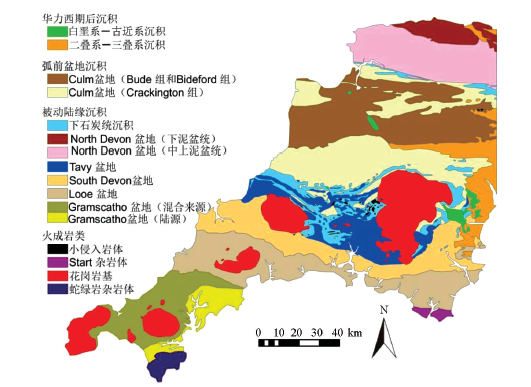 | 图3 英格兰西南部地质简要(据文献[38]修改) |
| 表2 元素数据列表 |
2.2 数据处理
对筛选出的16个元素的含量数据进行标准化, 以标准化之后的数据作为聚类输入值。综合考虑QE和TE 两个指标, 确定出最佳的SOM神经网络为18× 14的不对称网络, TE指数为1.155, QE指数为1.959。根据反复试验确定其他参数的最佳取值, 选择随机初始化, 学习速率的初始值选0.1, 随着训练时间的增加逐渐减少到0.0001 后不再减小, 邻域距离(radius)的初始值设为45, 根据这些参数使用R语言“ kohonen” 包建立SOM模型进行聚类。
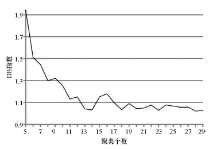
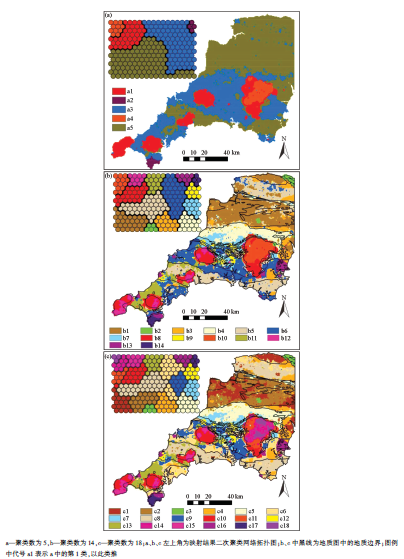
SOM聚类的总共类型个数为252个, 相对于地质图中的16类划分的太细了, 因此还需要进一步聚类, 用前文提到的K-means算法对SOM聚类结果进行二次聚类。二次聚类的聚类个数k根据DB指数结合实际聚类效果确定。如图4所示, 随着聚类个数的增加, DB指数总体呈减小趋势, 聚类个数为14时的DB指数最小, 为最佳聚类数。但由于不同聚类个数下的聚类结果表达的信息有所不同, 为了从不同尺度上挖掘出更多的地质体空间变化信息, 还选择了5、18两个聚类数。
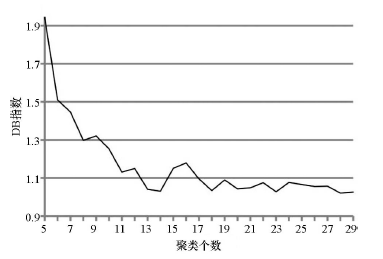 | 图4 DB指数变化曲线 |
2.3 结果与讨论
图5为聚类结果图, 从聚类结果图与地质图的对比可以看出, 聚类结果图很好地响应了地质体的空间变化, 这说明笔者提出的聚类方法可以用于推断地质体的空间分布。聚类图中同一类型内的观测数据点在地球化学特征上相似, 根据这些地球化学信息能够得到许多有价值的地质信息。对于火成岩类, 可以通过聚类单元中的地球化学特征探讨其岩性、岩相变化; 对于沉积岩类, 其地球化学特征与岩性、物质来源、形成时的沉积环境有关, 通过某些对沉积环境变化敏感的元素(如B、Sr、Ba、Ca、V、Ni、Fe、Mn、Th、U、Mo等)及其比值 [39,40,41], 可以推断地质体形成时的沉积环境、古盐度、氧化还原条件等很多重要信息, 进而根据这些信息推测出聚类结果中沉积岩的地质类型及其地质特征。下面以聚类数为5时的聚类结果(图5a)为例, 通过各类型的地球化学特征进行地质信息挖掘。
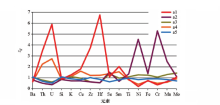
为了表示每个聚类类型中各元素含量平均值相对于整个研究区的富集程度, 引入zij这个比值, zij计算公式如下:
其中aij表示元素i在类别j中的含量平均值; ai表示元素i在所有类别中的含量平均值。
图5a中各聚类类型zij值变化曲线如图6所示, 从该图中可以看出, 类别a1中的U、Th、Zr、Hf富集程度最高, Fe、Cr、Ni、Mn富集程度很低, 研究区内最符合这些特征的是花岗岩, 因此a1对应的岩性是花岗岩。a4的曲线形态与a1特别相似, 在聚类结果拓扑图(图5a的左上角图)中与a1邻近, 说明二者地球化学特征非常相近, 其元素特征也符合花岗岩的特征, 只是U、Th、Zr、Hf的富集程度低于后者。a1最富集U、Th、Zr、Hf, 说明其分异程度高, 可能有一定量的碱性岩组分[42]。从地质图上可以看出, a4分布于岩体的中心, a1分布于岩体的边缘, 这一划分结果是岩相变化的反映, 与相关文献[43]中对这几个岩体的划分大致吻合。这相当于对地质体进一步作了划分, 这个细分的过程是一个知识发现的过程, 可以对地质体进行详细解剖从而挖掘出更多有价值的信息。a2与a1、a4的元素平均衬度曲线形态正好相反, 在聚类结果的拓扑图中与a1、a4距离较远, 说明二者地球化学差别很大, 其基性组分富集程度最高, 酸性组分富集程度最低, 对应于区内的基性侵入岩, 包括最南部的蛇绿岩杂岩体和局部的一些小的基性侵入岩体。
 | 图6 聚类数为5时每个类型中各元素含量平均值与整个研究区各元素含量平均值之比值(zij)变化曲线 |
a3和a5明显不同于其他3类, 在图6中元素平均衬度变化幅度整体较小, 在聚类结果中的拓扑图上占据了大部分节点, 对应于地质图中面积大、成分多变的类型, 即沉积岩类。a3富集Se、Mn、Mo, 而Si、U、Th、Zr、Hf含量低于这几个元素的全区平均含量值。Mn富集指示搬运较远、细粒沉积、泥质较多; Mo、Se富集指示还原环境, 有机质含量高; Zr、Hf富集程度低说明锆石和其他在搬运过程中比较稳定的晚期分选矿物较少, 指示搬运距离远[38, 41]。据此推测a3形成于水深较大、搬运较远的还原环境, 岩性以泥岩、页岩等细粒沉积岩为主。这与其在空间上对应的地质图中的TB、SDB、LCS、GB1、GB2、CB2的特征吻合[44]。a5相对其他类型各元素平均衬度的变化幅度最小, 都在1左右变动, 各元素平均含量接近背景值, 说明其地球化学组成接近于区内各地质单元的平均水平, 指示多物质来源, 地球化学成分没有经过较高程度的分化。此外a5具有Ce、Se、Mn、Mo含量较低的特点, 说明其形成环境有一定程度的氧化。综合以上特征推断a5属于陆相或浅海相沉积, 岩性以细碎屑岩为主, 这与其在空间上对应的PTS、NDB1、NDB2、LB、CB1几个单元的特征吻合[38, 44]。
由于地质图中的单元划分是综合考虑了岩性、构造、地层、时代等地质特征进行划分的, 而聚类方法划分出的类型是以样品的化学成分数据为依据的, 两者划分的标准不同, 所以划分结果必定会有不一致的地方, 这从地质图和聚类结果图的对比中不难看出。此外, 下面几个原因也是造成这种不一致的重要原因:①聚类图中的地质体分布受聚类个数的控制, 不同聚类个数下各类型空间分布会有很大不同。聚类个数变大, 那些类内有差异的类型就会分裂为多个类型; 聚类个数变小, 那些相似的类型就会合并为一类。如区内的5个花岗岩体, 在地质图中属于同一类型, 在聚类图中, 被根据地球化学特征在不同聚类数下分成了多个类型; 再如图幅中部的TB和图幅南部的SDB, 对应于图5c中的c9和c6, 二者在地球化学性质上差别较小, 从图5c中左上角的拓扑图中也可以看出, 二者邻近, 说明地球化学特征非常相似, 根据相关文献[38], 此二者主要岩性都是板岩, 形成的沉积环境相近, 所以在图5b中被划分成了同一类型。②采样密度决定了聚类结果的精度, 采样密度越小, 形成的数据越不能反映细节特征, 对于较小的地质体就越缺乏辨识能力。此外, 样品的迁移性也会影响到聚类结果的精度, 水系沉积物样品相对于其对应的基岩有一定的位移, 根据这些有位移的样品数据得出的聚类图与地质图就会存在不一致, 尤其是在地质边界和较小的地质体上有明显的体现。③采样介质的地球化学成分在后期演化中经历了地表表生作用等的改造, 相对于其来源基岩发生了元素迁移, 并不能完全代表基岩的成分, 因此用这些数据聚类的结果就会与真实的基岩分布存在差异。④聚类模型输入变量和参数的选取对于结果影响很大, 变量和参数选取不当会造成聚类类型空间分布的偏差。
地质、物探、化探等不同方法是从各自的角度对地质现象的描述, 不同方法获取信息的方式不同, 获取的信息会有所不同, 这些信息相互补充, 才能形成对地质现象的全面描述, 有些地质信息只有通过化探方法才能获取到。因此, 聚类结果与地质图中存在不一致现象并不意味着其就是错误的, 而是可能反映了一些地质图中没有的信息, 这些信息对于认识区域地质可以起到补充作用, 有助于更好地了解区域地质现象。
3 结论
通过实例研究表明, 基于SOM-K模型和区域化探数据的地质信息挖掘方法应用效果理想, 比较合理和准确地划分出了研究区内的主要地质单元, 很好地反映了区域内各地质单元的地球化学特征在空间上的变化, 可以作为地质填图的辅助手段, 从而更好地认识地质体的空间变化规律。在聚类的基础上总结每个类型的地球化学特征, 能够从中发现很多有价值的地质信息, 诸如岩石类型、沉积环境、物质来源等重要信息, 这些信息可以为区域地质研究提供印证和补充, 有助于更好地理解和解释区域地质现象。
同时, 基于SOM-K模型和区域化探数据的地质信息挖掘方法还存在以下几个方面的局限性:①聚类图的精度和准确度很大程度上取决于采样密度, 采样密度越大, 识别精度越高; ②采样介质脱离母岩后在地表风化搬运过程中某些元素容易发生迁移, 会对地质信息的提取造成干扰; ③选择不同的元素变量及参数, 对于聚类结果影响很大; ④地球化学特征只能反映地质体的一个侧面, 为了更加全面的认识地质现象, 还需要增加其他如地质以及物探方面的信息。
The authors have declared that no competing interests exist.
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|