


{kind=link}
{kind=link}
{kind=link}
地球化学勘查数据迭代处理的可视化及结果分析
引用本文
高艳芳, 李俊英, 陈军威, 张玉领, 王文君. 地球化学勘查数据迭代处理的可视化及结果分析[J]. 物探与化探, 2016,40(5): 1021-1025.
GAO Yan-Fang, LI Jun-Ying, CHEN Jun-Wei, ZHANG Yun-Ling, WANG Wen-Jun. The visualization of iteration processing of geochemical exploration data and an analysis of the result[J]. Geophysical and Geochemical Exploration, 2016,40(5): 1021-1025.
Doi:10.11720/wtyht.2016.5.28
Permissions
GAO Yan-Fang, LI Jun-Ying, CHEN Jun-Wei, ZHANG Yun-Ling, WANG Wen-Jun. The visualization of iteration processing of geochemical exploration data and an analysis of the result[J]. Geophysical and Geochemical Exploration, 2016,40(5): 1021-1025.
Doi:10.11720/wtyht.2016.5.28
Copyright©2016, 物探与化探编辑部
© 《物探与化探》编辑部
地球化学勘查数据迭代处理的可视化及结果分析
作者简介: 高艳芳(1965-),女,教授级高级工程师,主要从事GIS技术的应用和软件开发工作。
摘要
地球化学勘查中,为了获得准确、客观的背景值并由其推断异常下限,需要对不服从正态分布的化探数据进行剔除离群值的迭代处理。为了深入剖析这个较复杂的过程,引用实测数据,利用“特异值检查”迭代自动化功能模块,重点研究了设置不同参数时对结果的影响和取对数迭代结果的可靠性。结果显示:根据化探数据迭代的目的和正态分布的3 σ法则,认为
关键词:
迭代处理; 自动化; 可视化; 背景值; 异常下限; 真值; 标准离差
中图分类号:P632
文献标志码:A
文章编号:1000-8918(2016)05-1021-05
doi: 10.11720/wtyht.2016.5.28
The visualization of iteration processing of geochemical exploration data and an analysis of the result
Abstract
To get accurate background value and anomaly threshold, it is necessary to iterate abnormally distributed geochemical data for deleting outliers in geochemistry. To analyze deeply the complex iteration procedure, actual data and “outliers check” the authors used iteration procedure to detect the effect of different parameters and reliability of logarithm transformation. Some conclusions have been reached: According to the goal and 3 σrule of normal distribution, in
Keyword:
iteration processing; automation; visualization; background value; anomaly threshold; true value; standard deviation
元素的背景值和异常下限值是化探数据的重要参量[1]。背景值和异常下限值确定的准确与否直接影响异常的解释与评价[2, 3], 从而影响最终的调查结果。因此, 元素背景值的确定和异常下限值的获得, 是化探数据处理中最基本、最重要的问题[4, 5, 6]。多年来, 通过化探工作者不断的努力, 涌现出了众多求解背景值和异常下限的方法。但是目前应用最广的仍然是算数平均值加标准离差这一传统方法[7, 8]。此方法的应用原理是[9]:只有在元素值集合的概率分布服从正态或近似正态分布的前提下, 该集合的算数平均值才可以作为元素背景的取值, 此背景值可用来计算异常下限。为了满足这一条件, 化探数据处理过程中引入了迭代处理。
1 化探数据的迭代过程
迭代是数学上的一种求解方程的方法, 也叫逐次逼近法, 是一种通过求近似根的序列收敛, 最终得到较为精确解的过程[10]。迭代过程是不断重复的, 每一次对过程的重复即称为“ 迭代” , 每次迭代是为了逼近所设目标, 且每一次迭代的初值不同[11, 12]。迭代过程的复杂性, 使得人们更加依赖于运算速度快、适合做重复性操作的计算机去实现。迭代过程需要确定变量和迭代结束的条件。
化探数据处理过程中, 为了使不服从正态分布的元素数据集合呈现正态或接近于正态分布, 采用了迭代剔除(替换)。在此过程中, 迭代变量为元素(值), 迭代规则为:剔除>
1) 计算初始数据集中某元素的算数平均值(
2) 将>
3) 检查有无>
4) 求出最终数据集的均值(
剔除方式可以换作替代, 即将离群值用
由上可见, 化探数据的迭代过程是一个有限次的线性迭代。
2 迭代过程的自动化和可视化实现
在进行中国地质调查局地质矿产调查专项“ 中大比例尺化探数据一体化处理系统研究” 项目研究时, 为了实现化探数据迭代过程的自动化, 开发了“ 特异值检查” 模块, 用来进行数据的迭代处理、背景值及异常下限的统计。利用此功能, 可以实现迭代过程的自动化处理和结果的可视化显示, 主要功能界面如图1所示。
 | 图1 自动化迭代过程功能界面 |
界面主要分为7个功能区:
①区为迭代条件的设置, k值默认为3, 用户可以自定义。
②区为异常上下限的计算公式。
③区为数据类型的选择, 默认为对原始数据迭代, 可选择数据取对数后再迭代。
④区为迭代变量的选择, 变量为单个或多个元素。
⑤区为迭代结果的可视化显示, 可以查看迭代过程中每次剔除点的情况(图2)。图2表明Cu经过了4次迭代处理。图中不同的颜色显示了每次处理时所剔除的点个数及其位置。
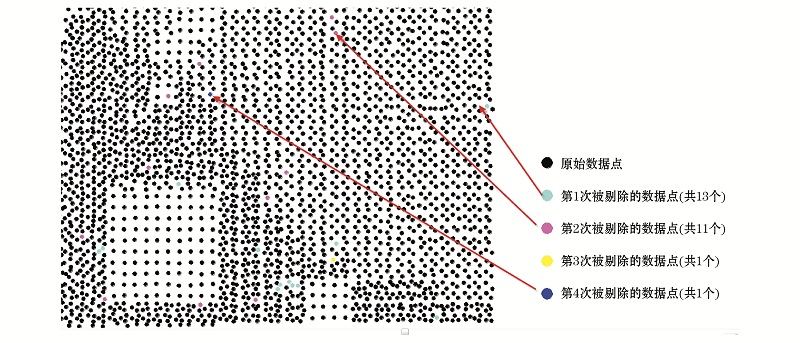 | 图2 迭代剔除过程的可视化显示 |
⑥正态分布曲线, 浏览查看每次剔除后元素的正态分布曲线(图3)。图3表明经过4次迭代处理的Cu每次迭代后所具有的概率分布形式及其平均值的大小、背景区间。
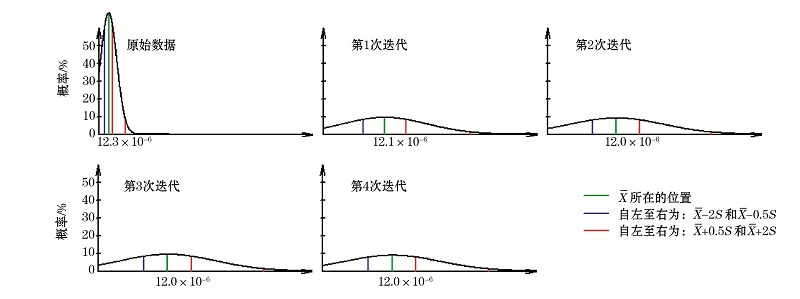 | 图3 Cu迭代剔除过程中的正态分布曲线 |
⑦计算获得结果, 获得的统计结果如表1所示。结果记录了每一次剔除时的各项参数。
| 表1 Cu迭代剔除结果 |
3 结果对比
化探数据的迭代过程, 由于参数众多(如k取值不同)、方式不同(剔除和替代)、数据形式不同(原始数据和取对数)、迭代规则不同(
3.1 取不同k值的结果比较
将k取不同的值时, 获得的结果如表2。从表2可以看出, 当k为3、 2.5、 2时, 迭代剔除的次数和点数随k值的减小呈明显的增加, 从而导致算数平均值和异常下限值的减小。但是k为3、2.5时, 差别不明显; k为3、2时差别显著。
| 表2 k取不同值时的迭代结果比较 |
化探数据在迭代处理时, k值究竟应该选择哪个数值最为恰当, 作者认为应该从迭代处理的目的去考虑。迭代处理的目的是在剔除高值点的同时使元素呈现正态分布, 从而获得适宜的背景值。按照正态分布的3α 法则:μ 为平均值, σ 为标准离差, 在[最小值, μ -3σ ]和[μ +3σ , 最大值]范围中仅占有0.3%的数据量, 此范围称为极端异常区, 此区内的数据称为离群值, 所以k=3为首要的选择。在表2中, 若选择k=3时, 最大剔除量为844个数据点; 当k=2时, 最大剔除点数达到3 342个, 几乎近一半为离群点, 显然不切合实际。
3.2 原始数据迭代和取对数迭代的结果对比
利用实测数据进行原始数据迭代和取对数迭代, 迭代剔除的规则为剔除>
| 表3 1:50 000数据真值迭代剔除和取对数迭代剔除结果对比 |
从表3可以看出, 原始数据迭代过程的次数和剔除点数要远远多于以对数方式进行的迭代次数和点数, 只有1个元素稍有不同。
同时, 利用对数算数平均值和对数标准离差计算异常下限转换后的真值 , 均远远高于原始数据的迭代结果。这是长期以来一直困扰着化探工作者的问题。在实际科研生产中, 为了获得较低的异常下限, 往往将对数计算时标准离差的倍数从2降为 1.65, 这是一种没有依据的人为妥协。
经过研究发现, 利用取对数后的对数计算获得的异常下限过高, 这是由于对数标准离差的误用而引起的。
已知某元素i在n个采样点上的分析数据为
x1、x2、x3、…、xn, 则其原始数据的算数平均值为 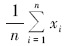
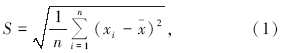
其对数的算术平均值为 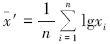
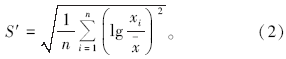
从式(1)和式(2)可以看出, 对数算术平均值的真值即为原始数据的几何平均值。但是对数标准离差的真值并不对应实际真值的标准离差, 也就是说对数标准离差和原始数据取对数再剔除后的真值的标准离差是不相等的。所以利用对数的平均值和2倍标准离差求和后再取真值, 由于呈指数数量级的变换, 因此所获异常下限往往过大。实际应用中, 以对数方式计算, 有的元素异常下限值最大能超过按原始数据迭代所获异常下限的1/3, 这显然是标准离差的误用引起的。
从表3中还可以发现, 对数迭代过程中, 若按对应真值的几何平均值和此时真值的标准离差进行统计, 就不会出现异常下限过高的结果。尽管对数迭代过程次数少, 剔除的离群值数据点少, 其标准离差会大于原始数据迭代替换时的标准离差, 但是因为几何平均值永远小于算数平均值, 所以以此方式求得的异常下限有时甚至小于原始数据迭代的结果, 但总体上二者是一致的, 数据也是可用的。这可以说明, 用真值和取对数分别进行迭代处理, 求得的异常下限是吻合的。
“ 特异值检查” 模块在进行取对数迭代时, 最后提供了两个数据结果, 一个是按照对数进行统计的结果, 一个是按照对应真值进行统计的结果。按对应真值直接获得的标准离差才是正确的结果, 这也说明利用几何平均值和真值的标准离差计算获得的异常下限可以被利用。
4 结语
化探数据处理中迭代剔除过程是一个数据进行重复计算的复杂过程。利用计算机技术及可视化技术开发获得的“ 特异值检查” 功能, 将化探数据的迭代处理过程实现了自动化和可视化, 从而可以解释模糊或无从证实的疑问, 获得明确的结论。这也说明, 充分利用先进的计算机技术, 化探数据处理过程可在实现数据处理自动化、可视化甚至智能化的同时, 对化探数据本身蕴含的规律有新的理解和认识, 这些认识必将进一步促进方法技术的发展和进步。
The authors have declared that no competing interests exist.
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|