{kind=link}
{kind=link}
{kind=link}
{kind=link}
GRNN与LS-SVM方法在计算煤质工业组分中的应用
[周大鹏1 , 王祝文1  , 李晓春
, 李晓春2 ]
, 李晓春|
|


作者简介: 周大鹏(1992-),男,硕士研究生,研究方向为地球物理测井。
在煤炭开发过程中,对煤质的评价尤为重要。依靠实验室分析来确定煤质的工业组分效率比较低,成本也比较高,因此通过建立其与测井参数之间的关系来进行各组分的计算。选取自然伽马、双收时差、密度以及三侧向电阻率这四个测井参数为输入的特征参数,煤质的水分、灰分、挥发分以及固定碳的含量作为输出结果,利用在某煤田挑选的73层测井数据当作训练样本,构建了基于广义回归神经网络(GRNN)以及最小二乘支持向量机(LS-SVM)的计算模型,从而建立了测井参数与各工业组分之间的关系。对19层的测试数据进行了检验,结果表明这两种方法均能应用于实际的生产之中;相比之下,广义回归神经网络能更准确地计算出各组分的含量,其平均平方误差均在1%以下。
As one of the most pivotal resources, coal cannot be replaced. The evaluation of coal properties plays an essential role in the development. The calculation of coal properties based on laboratory analysis is inefficient and expensive. In this paper, the authors have resolved this problem by establishing the relationship between logging parameters and coal properties. Natural gamma, time difference, density and three-lateral resistivity are treated as input, and values of moisture, ash, volatile matter and fixed carbon are chosen as output. By using 73-layer logging data to train, the authors constructed a model based on GRNN and LS-SVM to calculate coal qualities. Through testing 19-layer data, the authors have reached the conclusion that these two methods can be well used in practice. The GRNN can calculate the content of moisture, ash, volatile matter and fixed carbon more accurately than LS-SVM, with its mean square error lower than 1%.
虽然目前我国的能源结构已经有了很大的改善, 但煤炭作为国民经济发展的重要资源, 仍然有着举足轻重的作用, 各领域对煤炭资源的消耗量仍然很大, 只有做好资源开采和高效利用才能更好发挥煤炭资源的作用。在煤炭资源开发过程中, 煤质的工业评价是很重要的一个方面[1]。目前, 煤质工业参数求取主要依靠取心分析, 这种方法工作效率低, 代价昂贵, 并且只能得到特定煤层的总体特征, 而不能进行煤层内部精细解释。建立测井参数与工业组分之间的关系可以很好地解决这一问题。
近来, 煤田测井无论是在仪器装备还是数据处理技术方面都得到了长足发展, 多年的测井工作实践证明煤质的工业组分与测井参数之间有着一定的关系[2, 3]。但是常规解释模型的建立需要很多的假设条件, 并且解释模型的使用还受很多其他因素的限制。神经网络等学习算法适合解决存在某种潜在联系但又无法确切表达的问题, 在油气藏测井评价中已经得到广泛应用[4, 5, 6, 7]。笔者借鉴油气藏中的测井评价方法, 探讨GRNN神经网络和LS-SVM在煤质工业分析中的应用。
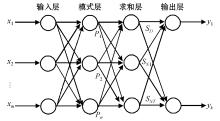
广义回归神经网络(Generalized Regression Neutral NetWork, GRNN)是美国学者Donald F. Specht 在1991年提出的一种径向基神经网络, 具有很强的非线性映射能力、高度的鲁棒性以及柔性网络结构, 适于解决非线性问题[8]。GRNN与一般的网络相比有更好的逼近能力和更快的学习速度, 最后收敛于积聚样本量较多的回归面, 并且当样本数据比较少时, 预测效果也很好。在结构上, GRNN由四层组成, 如图1所示, 分别为输入层、模式层、求和层和输出层[9]。对应网络输入X=[x1, x2, …, xm]T, 其输出为Y=[y1, y2, …, yk]T。
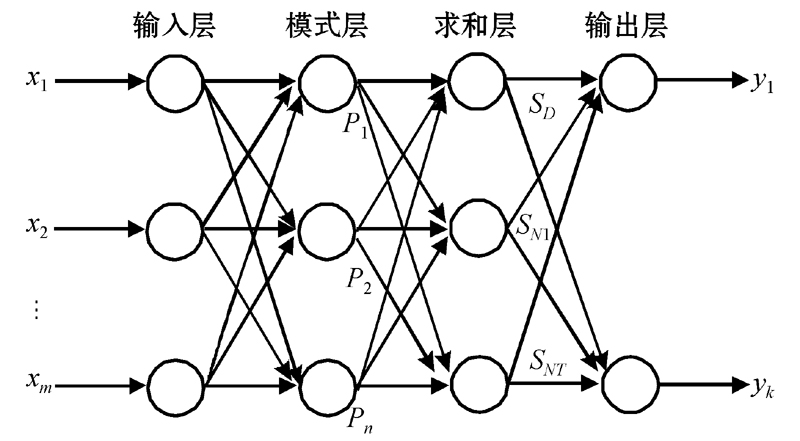 | 图1 广义回归网络结构 |
1) 输入层:各神经元是简单的分布单元, 输入层神经元的数目等于输入向量的维数, 直接将输入传递给模式层。
2) 模式层:模式层神经元的数目与样本的数目n一致, 各个神经元对应不同的样本, 神经元传递函数为
神经元i的输出为输入变量与其对应样本之间Euclid距离平方的指数形式。其中X为输入变量; Xi为第i个神经元对应的学习样本。
3) 求和层:这种求和方法可以分为两类。一类为
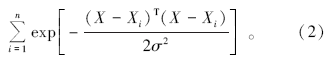
其对模式层所有神经元的输出进行算数求和, 模式层与神经元的连接权值为1, 其传递函数为

另一类计算公式为
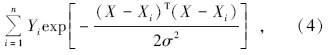
对模式层的神经元进行加权求和, 模式层中第i个神经元与求和层中第j个神经元之间的连接权值为第i个输出样本Yi中的第j个元素, 传递函数为
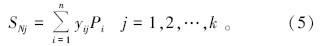
4) 输出层:输出层中神经元的个数等于输出向量的维数。其将求和层的输出相除, 神经元j的输出为计算结果的第j个元素[10, 11]。
支持向量机(SVM)在机器学习领域已经建立了比较完整的理论体系, 其理论基础是统计学习理论, 本质上是结构风险最小化的近似实现。对于一个给定的训练集合, 利用非线性映射把样本映射到高维特征空间。在特征空间中构造决策函数。这样原空间的非线性函数就转换成了特征空间中的线性函数[12, 13]。
最小二乘支持向量机(LS-SVM)是标准支持向量机(SVM)的一种扩展形式, 与传统的支持向量机相比, 最小二乘支持向量机的损失函数采用误差的二范数, 并利用等式约束代替标准支持向量机的不等式约束, 从而将二次规划问题转化为线性方程组求解问题。降低了计算的复杂性, 从而提高了求解速度, 在很短的时间里已广泛用于许多领域[14, 15, 16]。
对于有k个样本的训练集合(Xi, yi), Xi∈ Rd, y∈ R, i=1, 2, …, k; 根据LS-SVM理论, 应用公式
在特征空间中对样本空间的非线性函数进行估计。其中:φ (X)是到高维空间的映射, ω 是权系数, b是偏差。当损失函数为误差的二范数时, ω 和b的确定转变成求解优化问题:
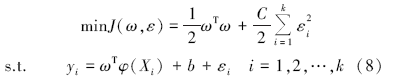
式中, ω 对应模型的泛化能力, C为惩罚因子, 控制模型的精度。
用拉格朗日法求解本优化问题
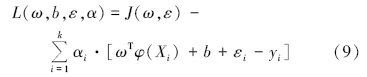
其中α 为Lagrange乘子, 根据优化条件可得
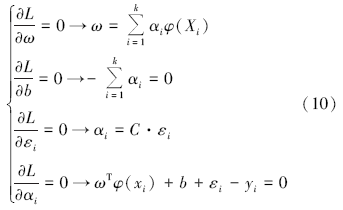
定义核函数K(Xi, Xj)=φ (Xi)· φ (Xj), 优化问题转化成求下面的线性方程组:
式中:Id是单位矩阵, Id=(1, 1, …, 1)T。则式(7)变为
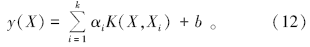
由此可知, 只要确定了核函数与惩罚因子, 就可以得到想要的向量机模型。
在某煤田挑选了15口详查井的综合测井解释资料, 从中任意选出了有实验室分析的92层特征煤层, 其中73层的数据作为训练样本, 剩余的19层作为检验, 选择自然伽马、双收时差、密度以及三侧向电阻率这四个测井参数作为输入的特征参数, 水分、灰分、挥发分以及固定碳的含量这四个比较重要的工业分析指标为输出结果。利用MATLAB软件编程, 分别对上述两种方法的有效性进行了验证, 并对其结果进行了对比分析。
由于各个测井参数具有不同的物理意义, 其量纲和数量级有很大差别, 因此, 在进行计算前需对原始的数据进行归一化处理。处理公式为
式中:xg为归一化后的数据, x为原始的测量数据, xmax、xmin分别为设定的最大值和最小值。经过处理后, 不同量纲的测井数据会在一个相同的数值范围内, 这样有利于提高计算的准确性。
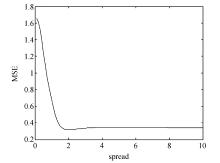
GRNN神经网络人为需要调节的参数比较少, 只有一个spread值需要调解。利用交叉验证的方法确定了网络最终的输入样本以及spread值。当spread值为2的时候, 网络的计算结果最为准确, 交叉验证的最小平均平方误差为0.32。
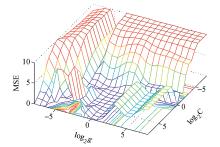
选用高斯径向基(RBF)函数作为LS-SVM的核函数, 在交叉验证中使用网格搜索方法确定了核参数与惩罚因子。当核参数(g)为0.19, 惩罚因子(c)为1.7时, 交叉验证的最小平均平方误差为0.47, 拟合效果最好。图2、图3示意了两种方法参数的选取, 表1给出了部分样本的训练误差。
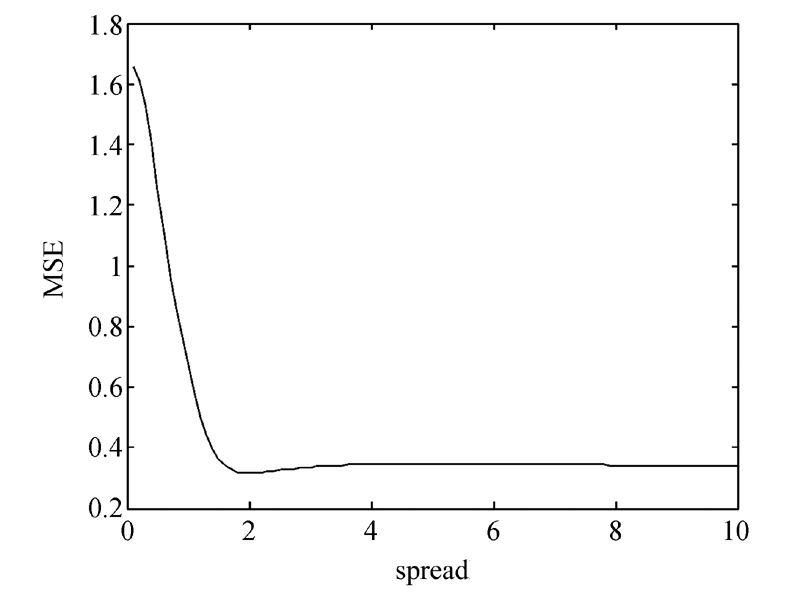 | 图2 GRNN参数的选取 |
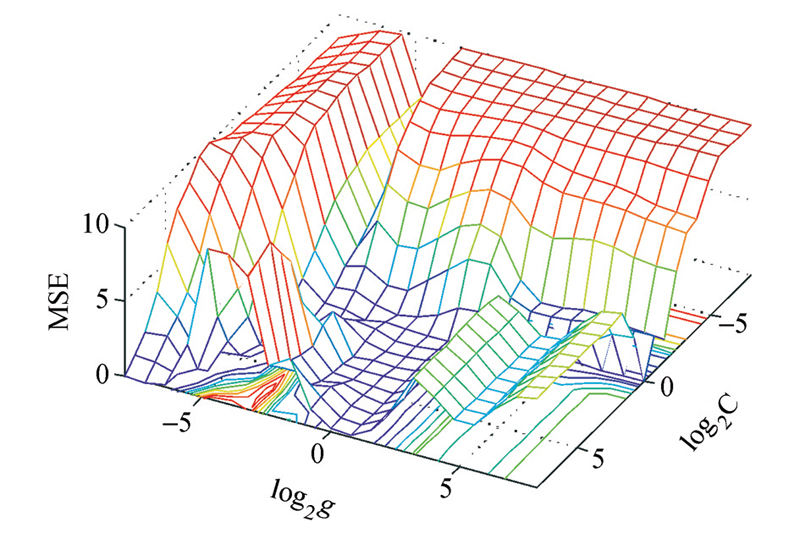 | 图3 LS-SVM 参数的选取 |
| 表1 73层训练样本的训练误差% |
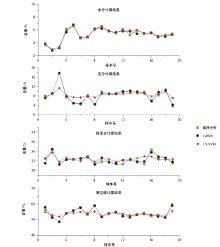
分别利用训练好的GRNN网络和LS-SVM对选取的19层数据进行计算, 结果见图4。可以看出:与LS-SVM相比, GRNN网络的计算结果更加准确, 水分、灰分、挥发分以及固定碳的平均平方误差均在1%以下(表2)。
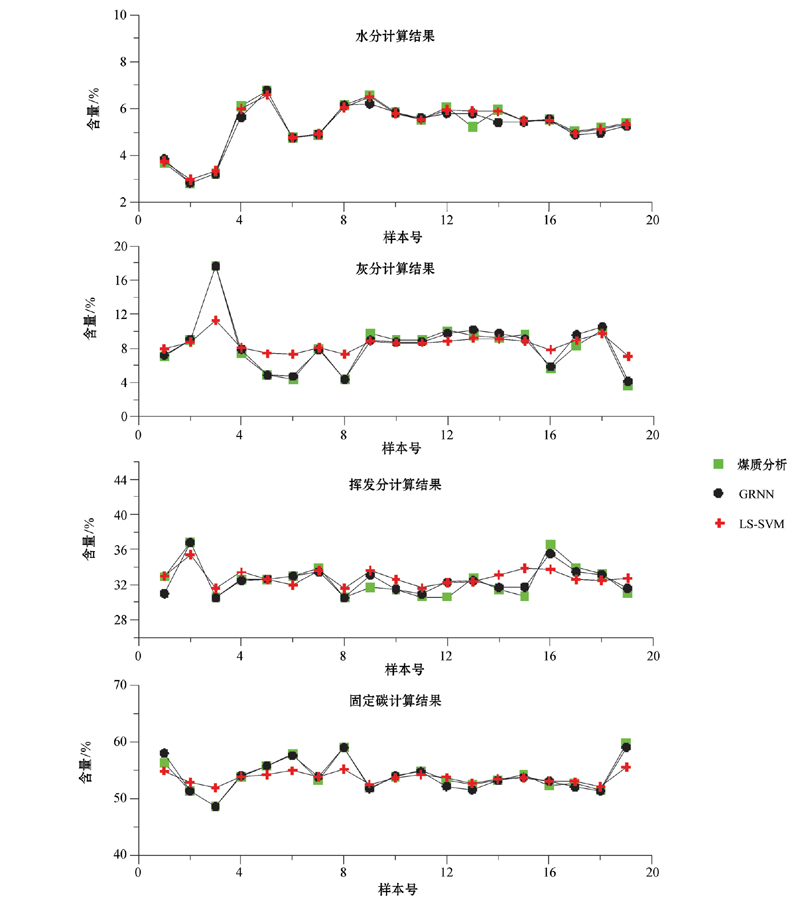 | 图4 不同计算模型的输出结果 |
| 表2 GRNN与LS-SVM的平均平方误差% |
由于GRNN网络计算的本质实际是观测样本的加权平均, 而其中权重为测试数据与样本之间的距离平方指数, 所以, 这四种组分的累加和会一直保持100%, 累加和的误差为0%, 符合常规的煤质解释模型。在LS-SVM计算模型中, 水分、灰分、挥发分以及固定碳这四种工业组分是分别进行拟合计算的, 所以计算的结果可能并不满足累加和为100%。但在对水分含量的计算上, LS-SVM的计算结果要优于GRNN神经网络。
构建了基于GRNN神经网络和LS-SVM算法的计算模型, 实例分析表明, 这两种方法均能很好地应用在计算煤质工业组分方面。通过建立这种测井参数与工业组分之间的关系, 在不进行取样的情况下也能对煤层的组分进行分析。这两种方法中, GRNN网络的整体计算精度要高于LS-SVM。在算法进行学习的过程中, 有关参数的选取至关重要, 如何能快速、准确的确定出所选网络的计算参数是下一步的研究重点。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|