{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
地震三维观测系统共中心点面元属性的并行计算方法
[李逢春1, 2  , 王润秋
, 王润秋1 , 赵薇薇2 , 杜清波2 , 郭武2 , 王汉钧2 ]
, 王润秋|
|


作者简介: 李逢春(1976-),男,重庆市人,2006年6月在武汉大学获得工学博士学位,主要研究方向为并行计算、三维可视化及石油勘探软件研发。E-mail:lifcmail@sina.com
针对高密度地震勘探下的三维观测系统海量面元属性计算需求,基于OpenCL并行编程模型,研究并实现了适用于异构环境下面元属性的并行计算方法。根据面元分析算法特点将整个网格分成多个子区域,子区域可由不同设备以粗粒度方式并行,而子区域内部以炮检对方式细粒度并行。采用HP Z820工作站,在CPU+GPU异构混合平台下的试算结果表明,异构多核处理速度是CPU(单核)的30倍以上,数据生成速率高于300 MB/s。
For the purpose of common mid-point bin attribute analysis from high density exploration and three-dimensional seismic geometry,this paper analyzes the calculation characteristics of bin analysis,and proposes an efficient parallel algorithm for bin attribute analysis based on Open Computing Language (OpenCL) heterogeneous programming model.The algorithm divides bin grid into several sub-regions under hardware memory constraint.Tasks of sub-regions are executed with coarse-grained parallelization by assigning task to different devices,whereas pairs of source-receiver in sub-region are executed with fine-grained parallelization.With HP's Z820 desktop workstation,experiment was carried out with high density three-dimensional geometry from seismic exploration.The experimental results show that the parallel algorithm takes full advantage of multiprocessor's parallel processing capability,and the processing speed is about 30 times faster than that on CPU-based implementation (single core) under the condition that the precision is not changed.
为了合理设计野外观测系统方案, 需要对不同观测系统的共中心点(common mid-point, CMP)面元属性进行对比分析。常规CMP面元属性分析有覆盖次数、炮检距和炮检方位角。对覆盖次数、炮检距和炮检方位角的直观和精确描述, 是优化观测系统设计的关键因素之一, 而CMP面元属性计算则是实现观测系统面元属性分析的基本技术手段[1, 2, 3]。
近年来, 随着地球物理探测技术的发展, 特别是万道以上地震仪的推广应用, 高密度地震勘探技术正逐渐成为地震勘探技术发展的主流[4]。高密度地震勘探通过减小面元尺度和提高空间采样率来增加采样密度。目前, 常规地震勘探面元一般为25 m× 25 m, 而为了适应未来的石油勘探开发的精度要求, 可能采用5 m的空间采样密度, 这对于山地勘探和小断块、薄储层、小砂体、小尺度孔洞的识别以及精细油藏描述具有重要意义[5]。高密度地震勘探具有小道距、高覆盖的特点, 因此极大地增加了地震野外采集的数据量。野外生产的接收道数不断增多, 百万乃至千万级炮检点的布设越来越普遍。日益增长的地震采集应用对三维地震观测系统面元属性快速分析和变观提出了越来越高的要求[6, 7]。由于一个面元的面元属性值是对该面元上覆盖的多个关系片计算后的统计和累加结果, CMP面元属性计算的工作量大、耗时长, 对存储容量和I/O的要求更高, 成为生产应用的瓶颈。目前, 普遍应用于野外施工设计的软件主要有美国ION公司的Green Mountain软件[8]和GEDCO公司的OMNI软件[9], 均面临计算时间长、结果数据量太大导致计算失败等问题。这些软件面对超大观测系统和高覆盖次数(千次以上)面元分析任务的挑战, 也显得无能为力。在对CMP面元属性分析的过程中, 由于传统的面元属性计算方法是串行执行的, 即依次计算每个面元的面元属性, 因此, 在多核硬件环境下, 不能充分利用计算资源; 由于串行执行CMP面元属性计算的效率低, 而不能满足高密度地震勘探带来海量CMP面元属性计算的需求, 从而导致了分析CMP面元属性时, 效率低、资源利用率低的问题。
图形处理器GPU有着高速浮点性能和超高的内存带宽的独特优势, 近年来在地球物理领域得到了广泛而成功的应用。地震勘探目前对高性能计算的直接需求是叠前偏移、叠前反演和全波形反演[5]。张兵等[10]实现了裂步法二维地震叠前深度偏移处理的GPU计算。刘国峰等[11]基于CUDA编程环境实现了台式GPU/CPU协同并行计算, 并成功应用到地震偏移成像。张慧等[12]采用震源重构方法解决了逆时偏移互相关成像条件需要的海量存储问题, 引入GPU解决逆时偏移计算效率低的问题。张猛等[13]研究提出基于CPU/GPU异构平台的时空域声波方程全波形反演算法实现流程。
开放计算语言(open computing language, OpenCL)作为面向异构系统通用目的并行编程行业标准, 得到包括Intel、NVIDIA和AMD等主流芯片厂商的支持[14, 15]。OpenCL为软件开发人员提供了统一的异构系统的并行编程环境, 屏蔽了基于SDK编程的很多复杂硬件细节, 提高了并行编程的生产率。针对CMP面元分析特点, 笔者采用基于OpenCL的面元网格分区并行计算方法。并行设计中将计算任务沿纵横向分配成多个子区域, 每个子区域由CPU/GPU设备进行并行计算, 最后通过10万道接收观测系统验证文中并行计算方法的效率。
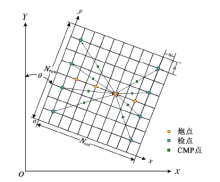
按地质任务建立满覆盖观测系统, 利用已知观测系统关系片得到炮检中心点和偏移距, 并根据炮检中心点得到面元覆盖次数。常规面元属性计算原理如图1所示, 面元宽为w, 高为h, 面元总行数Nrow, 面元总列数Ncol, 面元线方位角为θ , 炮点到检波点的距离dSR为炮检偏移距。利用三维观测系统炮检关系数据, 得到炮检对中心点M的大地坐标M(X, Y)。根据面元划分参数将大地坐标M(X, Y)转换为相对坐标M(x, y), 中心点M(x, y)在相对坐标系下的坐标为
式中:Ox, Oy为观测系统大地坐标原点。
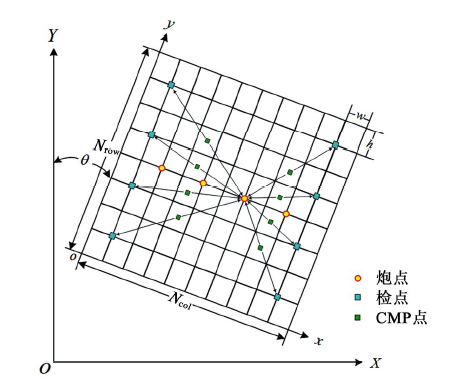 | 图1 面元属性计算原理示意 |
根据中心点M(x, y)相对坐标确定所在面元行列位置分别为i=y/h, j=x/w。统计出一个面元内累计落入的炮检对中心点个数即为该面元的覆盖次数。
炮检距也称偏移距, 是具有炮检排列关系的炮点与检波点的距离。方位角是炮检矢量与正北方向顺时针旋转所形成的夹角。可以采用公式
计算得到炮检距和炮检方位角。其中:D为炮检距, β 为炮检方位角, (sx, sy)为炮点在大地坐标系下的坐标值, (rx, ry)为检波点在大地坐标系下的坐标值。
CMP面元属性分析的主要计算负荷在于大量的炮检对循环, 任何网格属性值计算只需要周围有限个炮检对即可, 因此计算过程具有良好的局部性, 非常有利于并行计算。首先, 读取观测系统数据并将面元网格分成多个子区域(分区); 其次, 在CPU端创建OpenCL内核执行所需的运行环境和资源; 最后在多设备上执行并行面元计算任务。
算法的核心部分有两点:一是如何根据计算设备的缓存大小将面元网格分区; 二是子区域内部炮检对的并行方法。
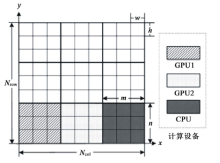
炮点激发, 由具有炮检关系的全部接收点接收, 则同一关系片内所有CMP点必定落在关系片所在的包络矩形区域内。据此可按关系片包络矩形与分区的相对空间位置将全部关系片映射到各个分区, 处于分区边界的关系片可能同时属于几个相邻分区。计算分区作为多设备粗粒度并行基本单位, 由每个设备(CPU/GPU)独立负责计算, 计算结果拷贝到设备全局内存。由于各分区炮检对CMP点叠加过程是独立的, 分区间不存在“ 写后读” 、“ 读后写” 、“ 写后写” 的数据竞争情况。
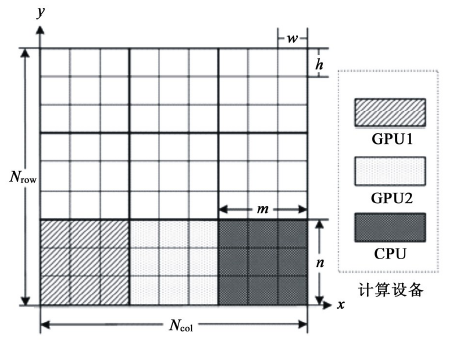 | 图2 面元网格分区并行示意 |
如图2所示, 针对CMP面元计算特点, 将三维观测系统待分析区域沿纵横向划分为多个计算分区(m× n面元格网)。假设每个CMP点占用16个字节, 则分区计算过程中每个网格需要申请的缓存为Fmax× 16个字节。分区大小由设备端开辟的属性数据缓存大小决定, 分区的数量由纵横向面元网格数决定。每个分区网格数应满足
的数量关系。其中:C为设备端可分配的缓存大小
(单位:字节), φ 为CMP点存储字节数, Fmax为最大覆盖次数, ⌊」为向下取整符号。
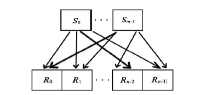
本文算法提速的关键正是利用了异构设备大量的线程级并行, 将面元属性分析的主要计算量转移至异构多设备端执行, 尤其是在超大观测系统面元计算时获得了理想的加速比。对具体的设备而言, 要提高算法并行度, 就是要使设备运算单元尽可能均匀地分配到计算任务, 这是提高计算效率的重要举措。笔者利用OpenCL内核(kernel)计算关系片内部每对炮检对的属性值, 分区内所包含的若干个关系片按照串行顺序执行。根据炮检关系建立炮检对与OpenCL执行模型的映射关系。如图3所示, 设有m炮n道关系片, 炮点集合S={S0, S1, …, Sm-1}, 接收点集合R={R0, R1, …, Rn-1}, 则炮检对集合为
其中, 集合SR中炮检对个数为m× n。
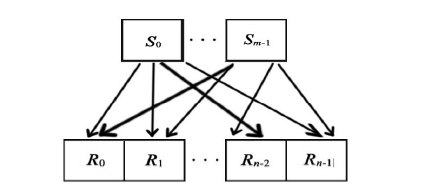 | 图3 关系片内炮检关系示意 |
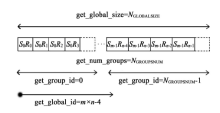
每一个实际执行计算的线程称为一个工作项(work-item), 负责一个炮检对的属性值计算。如图4所示, 炮检对集合SR可映射为一个一维的全局工作项索引空间, 工作项进一步组织成工作组(work-group), 则工作组分组数和全局工作项数目分别为
其中:NGROUPSNUM为工作项分组数目, m为炮点数, n为接收点数, L0为设备工作项第一维尺寸, Gmax为设备硬件所允许的工作组最大尺寸, 「⌉ 为向上取整符号, NGLOBALSIZE为全局工作项数目。
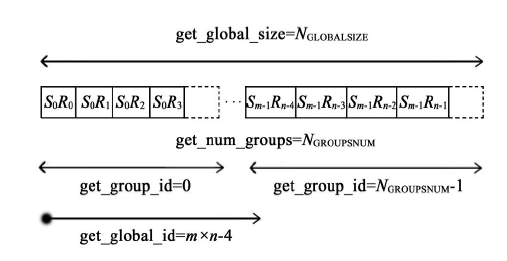 | 图4 炮检对映射到工作项索引空间示意 |
每个工作组对应min(L0, Gmax)个炮检对, 而每个工作项对应其中一个炮检对。激发点集合S与接收点集合R作为输入数据存放于设备全局内存。在工作项内部, 基于OpenCL技术在设备上进行的属性计算过程可分解成:根据工作项全局标示符从全局内存拷贝激发点和接收点数据到本地内存, 计算中心点坐标、偏移距和方位角, 将计算结果数据拷贝回全局缓存。
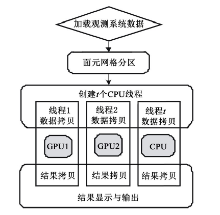
结合CMP面元分析算法原理及GPU等多核处理器架构特点, 设计了异构平台下基于OpenCL的并行计算流程, 如图5所示。
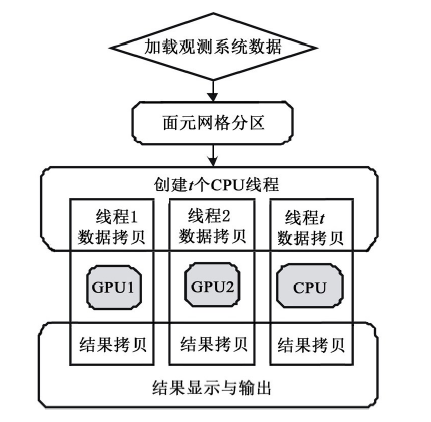 | 图5 异构并行面元属性计算流程 |
步骤一:读取观测系统数据并将面元网格分成多个子区域(分区)。
读取面元网格划分参数和设备的执行配置参数, 根据计算设备可用内存大小, 由式(4)得到面元网格分区大小和分区个数。计算每个关系片包络矩形, 得到每个分区所包含的关系片集合, 然后将每个分区作为基本计算任务放入任务队列TaskQueue。
步骤二:在CPU端创建OpenCL内核执行所需的运行环境和资源。
为每个计算设备创建OpenCL缓存对象及命令队列; 加载并编译内核代码, 创建程序执行体。为每个设备创建一个执行任务的CPU线程。
步骤三:在多设备上执行并行面元计算任务。
以步骤一得到的分区及其所属关系片集合作为基本的计算任务, 运行在各计算设备上的任务执行线程向任务队列TaskQueue申请计算任务。任务队列TaskQueue充当向各任务执行线程分发计算任务的角色。调用OpenCL内核Kernel计算不同炮检对的中心点、偏移距和方位角。将计算结果从设备端缓冲对象读入到主机内存, 并跳转到步骤三。重复步骤三直到任务队列TaskQueue为空, 则算法结束。
以L120S8T115 200(120线8炮115 200道, 960点/接收线, 接收点距12.5 m, 接收线距为100 m, 炮点距12.5 m, 炮线距100 m、滚动距为100 m)的正交式观测系统为例, 纵向(inline)和横向(xline)方向各滚动200次, 得到勘探区域inline方向长31 887.5 m, xline方向宽318 000 m。总激发点数320 000, 总接收点数814 088, 关系片个数40 000。面元大小为6.25 m× 6.25 m, 则inline方向面元网格数5 102, xline方向面元网格数5 088。满覆盖次数3 600 次, 面元属性计算结果数据总量达到549 GB。
本实验采用惠普新一代Z系列图形工作站HP Z820, CPU采用12核英特尔至强E5-2600系列处理器, 支持双处理器。GPU分别为NVIDIA Quadro K5000/4GB和NVIDIA Tesla K40c/12GB。操作系统为win7专业版64位, 驱动支持OpenCL1.2。具体参数如表1所示。
| 表1 实验环境 |
高密度超大观测系统面元属性计算难以在生产中推广应用的一个重要原因是耗时长、微机磁盘占用量太大。共中心点面元分析算法效率依赖分区的划分方式, 需要综合平衡GPU显存和计算子区域的大小。文中选取3种不同的分区大小进行计算, 即100面元× 100面元(549 MB)、200面元× 200面元(2 197 MB)、250面元× 250面元(3 433 MB)。分别采用4种并行加速策略, 每种加速策略按分区从小到大的顺序计算得到加速比如下。
策略1:在Intel CPU平台上测得加速比分别为10.4、13.2、8.2; 属性数据的生成速率分别为100、278.6、358.8 MB/s。
策略2:在NVIDIA Quadro K5000平台上测试加速比分别为12.8、14.2、11.6; 属性数据的生成速率分别为123.6、300.1、506.9 MB/s。
策略3:在NVIDIA Tesla K40c平台上的测试加速比分别为16.5、16.9、13.9; 属性数据的生成速率分别为158.5、356.5、606.4 MB/s。
策略4:在CPU+GPU混合平台上测试加速比分别为38.1、43.6、29.6; 属性数据的生成速率分别为366.7、918.6、1 286.4 MB/s。
从并行计算加速比的对比中不难看出, 在各个单一的硬件平台上所获得加速比普遍在10倍以上, 而在CPU+GPU混合平台上取得的加速比达到30~40倍。从表2中可以看出, 随着分区增大, 即开辟较大的缓存, 计算效率呈上升趋势。这是因为计算子分区越大, 处于相邻分区的重叠关系片数量越少, 从而减少了冗余计算量。另外, 从属性数据的生成速率来看, 上述4种策略的数据生成速率普遍高于目前主流机械磁盘I/O性能。
| 表2 CPU及CPU+GPU计算时间比较 |
笔者针对高密度地震勘探下的三维观测系统海量面元属性计算性能问题, 研究了CPU/GPU环境下协同并行的高效算法。试算结果表明本算法对接收道数量大、布设密度高、勘探面积大的三维观测系统, 可以有效提高面元属性计算效率。本算法一方面充分利用微机多核资源, 另一方面以实时计算得到属性数据的方式替代原有先计算再存盘的方式, 极大地节省了微机磁盘空间, 更方便实际生产应用。
对于本文共中心点面元属性并行算法的进一步研究, 可以从以下几方面考虑:①目前的计算任务划分与设备缓存大小相关, 且按相同分区大小进行划分, 导致具有较大内存的设备缓存不能充分利用, 如何进一步合理划分任务还有待深入的研究和实验; ②对多个计算设备而言, 设备间的负载均衡问题需要在后续的研究中加以考虑。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|