





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
对数比变换和偏最小二乘法在地球化学组合异常提取中的应用——以湘西北铅锌矿为例
引用本文
王琨, 肖克炎, 丛源. 对数比变换和偏最小二乘法在地球化学组合异常提取中的应用——以湘西北铅锌矿为例[J]. 物探与化探, 2015,39(1): 141-148.
WANG Kun, XIAO Ke-Yan, CONG Yuan. Log-ratio transformation and PLS methods for identifying integrated geochemical anomalies: A case study of lead-zinc mineralization in northwestern Hunan[J]. Geophysical and Geochemical Exploration, 2015,39(1): 141-148.
Doi:10.11720/wtyht.2015.1.23WANG Kun, XIAO Ke-Yan, CONG Yuan. Log-ratio transformation and PLS methods for identifying integrated geochemical anomalies: A case study of lead-zinc mineralization in northwestern Hunan[J]. Geophysical and Geochemical Exploration, 2015,39(1): 141-148.
Permissions
Copyright©2015, 《物探与化探》编辑部
《物探与化探》编辑部 所有
对数比变换和偏最小二乘法在地球化学组合异常提取中的应用——以湘西北铅锌矿为例
作者简介: 王琨(1985-),女,博士研究生,中国地质大学(北京),研究方向为数学地质及化探异常信息提取方法研究。
摘要
以湘西北水系沉积物测量常量元素含量数据为研究对象,针对湘西北铅锌矿床的层控特征,以研究区含矿层地球化学常量元素含量的统计规律为基础,利用对数比变换(alr、clr、ilr变换)对原始数据进行预处理,并在此基础上进行偏最小二乘(PLS)降维分析,提取了地球化学组合异常,并与常用的主成分分析、因子分析的结果进行对比。分析结果表明,等距对数比变换(ilr变换)相对于其他变换方法有明显的优势,变换后的数据对称特征明显,更趋于正态分布。相对于其他两种降维方法,偏最小二乘法提取的元素组合与研究区铅锌矿的地球化学基本特征更为接近,组合异常与已知矿床分布和构造特征耦合良好,与研究区地质特征吻合,比主成分分析与因子分析得到的结果更易于地质解释。
关键词:
地球化学组合异常; 对数比变换; 偏最小二乘法; 异常提取; 湘西北铅锌矿
中图分类号:P632
文献标志码:A
文章编号:1000-8918(2015)01-0141-08
Log-ratio transformation and PLS methods for identifying integrated geochemical anomalies: A case study of lead-zinc mineralization in northwestern Hunan
Abstract
As lead-zinc deposits in northwestern Hunan are controlled by strata, the authors chose statistical regularities of constant elements in the ore-bearing layer as the basis of integrated geochemical anomaly extraction and used a stream sediment geochemical dataset. Firstly, three main forms of log-ratio transformation were used to explore the effects of the constant elements data closure problem. On such a basis, the PLS method was employed to study the integrated geochemical anomalies. The results show that data transformed by ilr method have obvious symmetrical statistical features and are much closer to the normal distribution. In contrast with PCA and FA, the integrated geochemical anomalies extracted by PLS method are generally more consistent with such geochemical features of lead-zinc mineralization in the study area as the known ore deposits and the fault distribution, and the results can be explained easier in geological field.
Keyword:
integrated geochemical anomaly; log-ratio transformation; PLS; anomaly extraction; lead-zinc ore deposits in northwestern Hunan
随着勘查地球化学方法的不断进步, 地球化学数据的深入挖掘和异常信息的提取及分析工作显得尤为重要。如何有效圈定异常范围, 对异常进行合理分析与科学解释, 成为勘查地球化学领域关注的重点问题[1, 2, 3, 4, 5, 6]。地球化学异常的提取与分析不仅要考虑元素的含量水平, 还要考虑元素之间的亲和性与空间关系, 按照地球化学元素的空间组配形态与机制来提取组合异常[7, 8, 9]。其中因子分析、主成分分析等方法在具体工作中取得了较为广泛的应用, 是较传统、常用的降维方法[10, 11, 12, 13]。
在地质研究中常遇到成分数据, 如地球化学全分析数据、矿物分析数据、沉积物粒度数据等, 都是成分数据[14, 15]。成分数据由于闭合效应引起伪相关, 不服从正态分布, 必然影响基于协方差结构的各种R型统计结果[16, 17]。因此, 在进行地球化学元素组合异常提取之前, 首先应进行数据的预处理。
笔者从地球化学元素含量区域特征入手, 对原始数据进行对数比变换, 消除变量间的多重相关性, 在此基础上进行偏最小二乘法分析和主成分分析, 从变量系统提取正交成分作为元素组合, 提取组合异常并进行地质解释。
1 区域地质概况
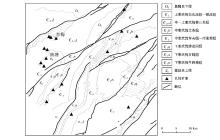
研究区位于湖南省西北部湘西自治州的铅锌矿集区, 区域上位于扬子陆块东南缘, “ 江南古陆” 西侧的加里东运动形成的八面山褶皱带内, 为湘黔铅锌矿带的北延部分[18, 19]。在地层和沉积建造上是一个在扬子旋回基础上发展起来的长期沉降单元, 在湘西北弧形构造带的北西侧。区内下古生界地层分布最为广泛。自震旦纪以来, 地台型盖层发育较全, 经历了万余米的海相沉积层, 均未发生区域变质。下古生界沉积厚度达4 000余m, 其中碳酸盐岩厚达1 800余m, 为区域铅锌矿的主要赋存岩层[20]。
研究区铅锌矿主要控矿地层为下寒武统清虚洞组, 矿体主要产于该组上部第三、四亚段, 为一套灰— 浅灰色、厚层— 巨厚层块状藻礁灰岩、斑块状云化灰岩, 含藻砂屑灰岩、砾屑灰岩, 厚数十至二百余米, 各种生物屑结构、鲕状结构、核形石结构、砂— 砾屑结构等十分复杂, 具有碳酸盐台缘礁和礁滩相特征[20]。藻礁相中矿体与围岩产状基本一致, 多呈缓倾斜整合层带状, 形态比较规则, 分布较稳定[24]。
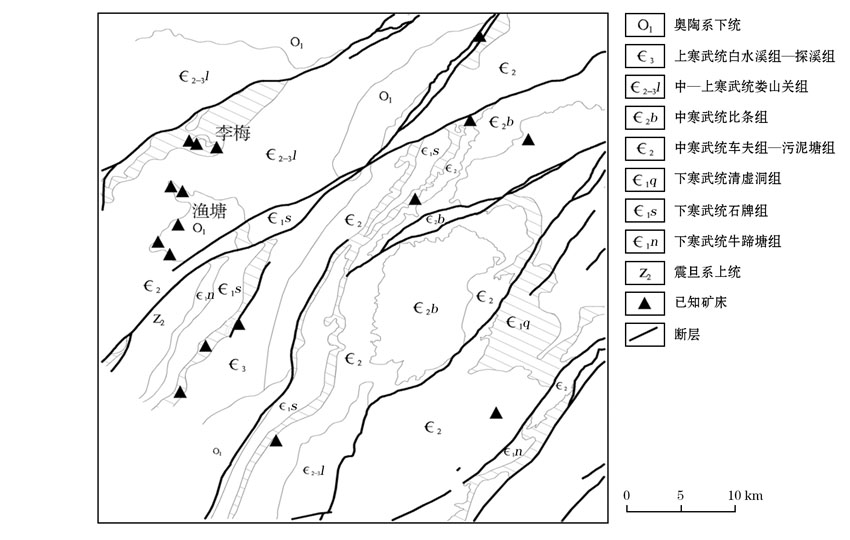 | 图1 湘西北铅锌矿区地质简要 |
2 方法原理
2.1 对数比变换
对数比变换是克服成分数据闭合效应的有效方法, 成分数据是指分布在有限区域内的, 服从单位和约束条件的数据, 地球化学常量元素含量数据就是成分数据[25]。对数比变换是根据成分分量的比值不受“ 定和” 限制的影响, 以及比值的对数常常服从正态分布的特点, 对成分数据进行投影变换, 利用特定的标准正交基来表现数据特征, 具体定义[26, 27]如下。
定义数据集SD为:SD={x1, x2, …, xD}, 其中xi> 0, i=1, 2, …, D。
则对数比变换函数分别定义为:
其中g(x)=[x1· x2…xD]1/D。
其中i=1, 2, …, D-1。
其中i=1, 2, …, D-1。
2.2 偏最小二乘方法(PLS)
偏最小二乘方法集成和发展了典型相关分析、多元线性回归和主成分分析方法的基本功能, 通过成分提取, 对包含多自变量和多因变量的数据进行建模分析[28, 29]。偏最小二乘方法利用将系统中的数据信息进行分解和筛选的方式, 提取对因变量解释性最强的综合变量, 识别自变量系统中的信息和噪声, 从而更好地克服变量多重相关性在系统建模中的不良作用。因此, 偏最小二乘方法也适用于地球化学数据组合异常的提取。具体建模方法[30]为:
设自变量X=
第一组成分t1和u1被提取后, 分别进行X对t1及Y对u1的回归计算。如果回归方程达到满意精度, 则算法终止, 否则将利用X被t1解释后的残余信息以及Y被u1解释后的残余信息进行第二轮成分提取。如此迭代计算, 直到达到一个较满意的精度为止。若最终对X共提取了m个成分t1, t2, …, tm, 偏最小二乘将通过yk对t1, t2, …, tm回归(k=1, 2, …, q), 表达为yk关于原变量x1, x2, …, xp的回归方程。提取的m个成分t1, t2, …, tm即为能更好概括原数据信息的综合变量。
3 地球化学特征分析
采用湘西北地区1: 20万化探水系沉积物7组常量元素及铅锌矿标志元素共9组数据作为研究对象, 具体包括SiO2、Al2O3、K2O、Na2O、CaO、MgO、Fe2O3、Pb、Zn。
为了分析研究区铅锌成矿的地球化学特征, 统计得到了各地层区域常量元素的含量平均值。为方便对比, 对不同元素的含量进行了z-score标准化标准化处理(表1)。对主要赋矿地层清虚洞组及其主要上覆地层娄山关组各元素含量做柱状图(图2), 可以得到成矿相关的地球化学统计特征, 即不同常量元素的组合情况。
从图2可以看出, 清虚洞组地层中Al2O3、Fe2O3、MgO、CaO和K2O数值为正, Na2O和SiO2为负值。娄山关组与清虚洞组情况相似, 不同的是K2O数值为负。
| 表1 湘西北铅锌矿区不同地层常量元素含量平均值(标准化后) |
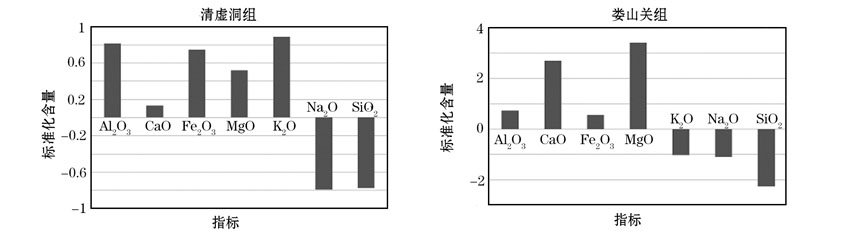 | 图2 湘西北铅锌矿区不同地层常量元素组合特征 |
4 组合异常提取
4.1 数据预处理
分别对原始数据进行对数比变换(alr变换、clr变换、ilr变换)及ln变换处理, 并将原始数据作为对比组, 以Pb、Zn数据为例进行对比说明。
通过变换结果的数字统计特征(表2)及频率分布直方图(图3)可以看出, 原始数据为典型的偏峰分布, 具有较大的偏度和峰度值。经过对数比变换以及ln变换之后趋于正态分布。clr变换与ilr变换结果的频率分布比ln变换与alr变换后频率分布的对称特征更为明显, 其中ilr变换后的数据呈显著的集中趋势, 均值更趋近于0值, 且均值两侧更为对称。
| 表2 湘西北铅锌矿区Pb、Zn含量数字统计特征 |
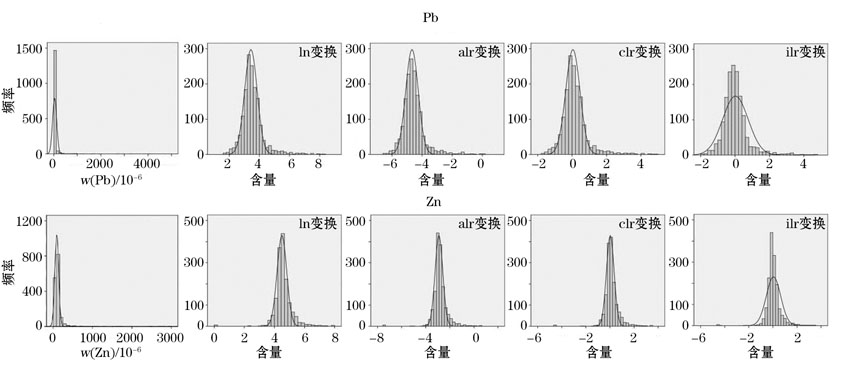 | 图3 湘西北铅锌矿区Pb、Zn含量频率直方分布 |
4.2 偏最小二乘(PLS)法提取组合异常
选取预处理后的地球化学常量元素数据作为自变量数据集X, Pb、Zn构成因变量数据集Y, 进行偏最小二乘降维处理。对4种不同预处理方法计算后的数据分别进行降维处理, 并将处理结果作对比, 分析不同预处理方法对降维效果的影响。
利用PLS方法各提取了7组主成分, 其中第一主成分方差贡献率最高, 包含了大部分原始信息, 各常量元素的贡献组合更接近研究区铅锌矿的地球化学基本特征(图4), 主要表现为Fe2O3、Al2O3、CaO、MgO对第一主成分的贡献为正值, Na2O、SiO2为负值, 与统计得到的本研究区含矿层(清虚洞组)地球化学常量元素分布规律基本一致(图2)。K2O对第一主成份的贡献由于预处理时选择的方法不同而出现两种结果:对数变换(ln)和对数比变换(alr和clr)后的数据经PLS降维处理, 得到的K2O贡献为负值; 而ilr对数比变换得到的K2O贡献值为正, 与研究区地球化学元素含量的统计规律完全吻合。
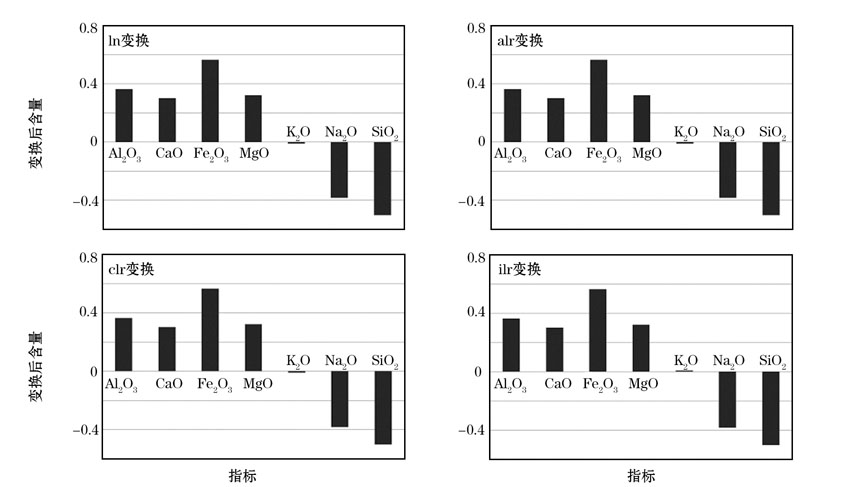 | 图4 不同预处理方法经PLS降维提取的常量元素组合 |
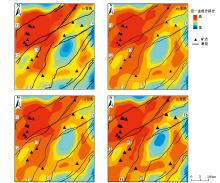
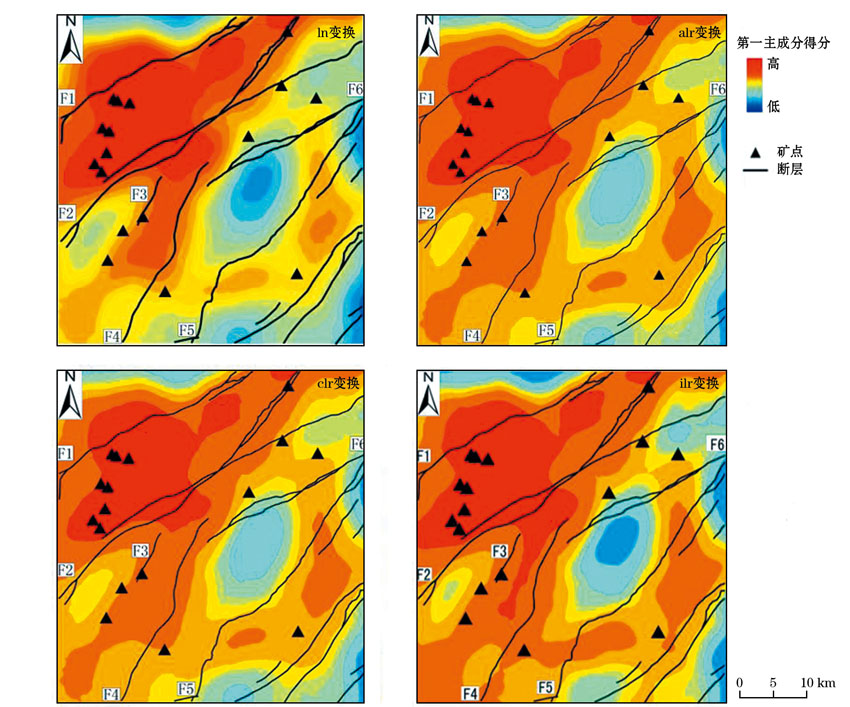 | 图5 PLS提取第一主成分得分等值线分布 |
分别利用4种预处理数据提取的第一主成分得分值作等值线图(图5), 经过克里格插值可以明显看出, 原始数据经过对数变换和不同对数比变换后, 经PLS方法提取的异常分布大致相似, 但局部还是有细微的差别。
总体来说, 异常区的总体分布与构造线走向基本吻合, 异常高值区主要集中在研究区北西侧两条近似平行的断层附近, 与已知矿点分布耦合良好, 断层则大致位于正负异常交界附近。研究区中部有一明显低值异常区, 对应上扬子东南缘被动边缘盆地。ilr对数比变换处理的数据经PLS方法提取的异常, 与其他3种方法的不同主要集中在研究区南西侧两断层之间的高值异常区。
本研究区已经发现的铅锌矿床主要产于下寒武统清虚洞组的藻礁灰岩中, 主要位于断层F1南侧的正异常高值区内。断层F1与断层F2之间异常强烈, 对应花垣、渔塘等主要矿区。断层F3与断层F4之间表现为带状高值异常区, 异常分布与断裂走向耦合良好。断层F3北西侧带状出露主要赋矿地层清虚洞组, 南东侧为爵山沟组地层, 已知铅锌矿床沿断裂走向分布。断层F4北西侧为车夫组、敖溪组地层, 南东侧带状出露清虚洞组、石牌组地层。因此, 已知铅锌矿床位于断层F3、F4对应的正异常高值区边缘。断层F5与断层F6之间有一明显的负异常高值区, 对应上扬子东南缘被动边缘盆地, 主要为下寒武统比条组地层。断层F2南东侧矿点主要位于次级正异常区边缘, 大致沿断裂走向分布。
与其他3种数据处理方法对比, ilr对数比变换数据经PLS提取的组合异常高值正异常及次高值正异常区域有所放大, 特别是突出了断层F3与断层F4之间的异常, 正异常高值区范围与成矿地层特征更为符合, 更有利于进一步的异常解释及成矿预测工作的开展。
4.3 对比与讨论
将ilr对数比变换后的数据分别利用主成分分析(PCA)和因子分析(FA)方法进行降维处理, 并将得到的结果与偏最小二乘降维方法作对比。
处理结果显示, 3种降维方法提取的主成分方差贡献率依次降低(图6)。累计方差贡献率结果显示, PLS方法的降维效果优于主成分分析和因子分析。
分别提取主成分分析和因子分析的前3个主成分, 得到对应的常量元素组合(图7、图8), 并与PLS方法提取的常量元素组合作对比。可以明显看出, PLS方法提取的结果更符合研究区地球化学常量元素的含量分布特征。
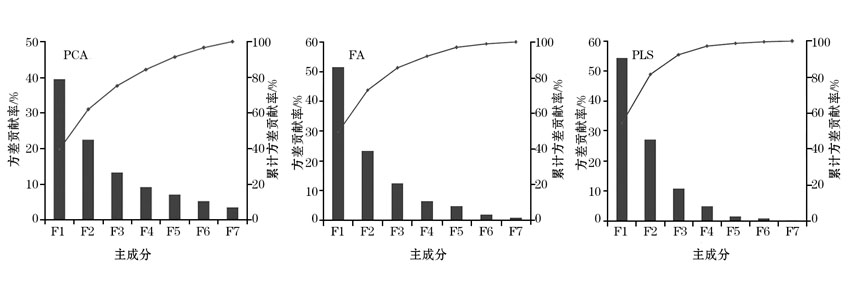 | 图6 不同方法提取的主成分方差贡献率及累计方差贡献率 |
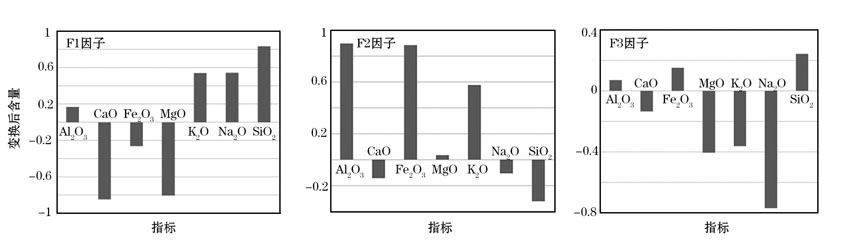 | 图7 主成分分析前3个主成分提取的常量元素组合 |
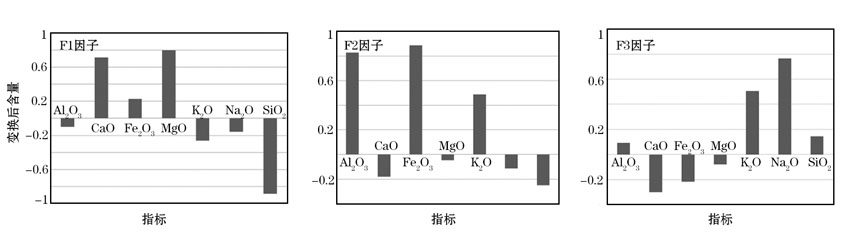 | 图8 因子分析前3个主成分提取的常量元素组合 |
5 结论
针对湘西北铅锌矿床的层控特征, 以研究区含矿层地球化学常量元素含量的统计规律为基础, 利用偏最小二乘法(PLS)进行降维处理, 提取研究区的地球化学组合元素异常, 并进行了异常解释。
为了克服常量元素可能会出现的闭合效应, 首先利用对数变换和对数比变换(包括alr变换、clr变换、ilr变换)对原始数据进行了预处理。其中等距对数比变换(ilr变换)相对于对数变换(ln变换)及其他两种对数比变换方法(alr变换、clr变换)有明显的优势。ilr变换后的数据呈显著的集中趋势, 均值更趋近于0值, 且均值两侧更为对称。
为了提取组合元素异常, 消除变量间的多重相关性, 采用偏最小二乘法(PLS)进行降维处理, 并与传统常用的主成分分析(PCA)和因子分析(FA)方法进行对比研究。3种方法的基本思想都是在数据信息损失最小的原则下, 从变量系统提取正交成分, 对高维数据进行降维处理。通过研究区实例证明, 偏最小二乘法(PLS)提取的组合元素异常较主成分分析(PCA)和因子分析(FA)方法更便于地质解释。
不同数据变换方法对组合元素异常提取有一定的影响, 但总体趋势不变, 其中ilr变换提取的异常与实际地质情况更为符合。研究区通过ilr对数比变换再利用偏最小二乘法(PLS)提取的组合元素异常区, 与已知矿床分布及断层位置耦合良好, 正异常高值区与赋矿地层下寒武统清虚洞组相对应, 能很好地反映研究区层控铅锌矿床的地球化学特征, 更便于异常解释, 为进一步的成矿预测提供更好的信息基础。
The authors have declared that no competing interests exist.
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|